



在建立多元线性回归模型时,我们常常希望各自变量能够独立地对因变量产生影响。然而,当自变量之间高度相关时,就会出现一个常见而棘手的问题——多重共线性。它不仅会影响模型系数的稳定性,还可能导致结果解释失真,甚至使模型失去预测能力。
本文将系统介绍多重共线性的识别方法、诊断标准与处理策略,并结合SPSSAU软件的实际输出案例,帮助读者在实际研究中有效应对这一问题。
一、什么是多重共线性?
多重共线性指的是在回归模型中,两个或多个自变量之间存在着高度线性相关关系。根据其严重程度,可分为:
- 完全共线性:一个自变量可以被其他自变量完全线性表示。
- 高度共线性:自变量之间高度相关,但未达到完全共线。
需要注意的是,多重共线性本质上是一个“程度”问题,而非“有无”问题。我们的目标不是完全消除它,而是将其控制在可接受的范围内。
二、为什么要检验多重共线性?
忽视多重共线性可能导致:
- 系数估计不稳定:微小的数据变动可能导致系数符号和大小剧烈变化。
- p值失真:即使自变量与因变量有真实关系,也可能因共线性而被判定为“不显著”。
- 模型解释困难:R²可能较高,但变量对因变量的预测能力被稀释,无法准确判断每个自变量对因变量的独立贡献。
例如,在分析卷烟销量与均价的关系时,若高二类与普一类销量高度相关,单独分析某类销量对均价的影响时,结果可能因共线性而失真。因此,在发布模型结果前,进行共线性诊断是必不可少的步骤。
三、多重共线性的检验方法
1. 相关系数矩阵
最直观的方法是计算自变量之间的Pearson相关系数矩阵。一般来说,如果两个自变量之间的相关系数绝对值超过 0.8,就可能存在共线性问题。
SPSSAU【进阶方法】模块提供【共线性分析】方法,我们来看一个SPSSAU输出的实例:

表中可见,“人均教学面积”与“人均设备”的相关系数高达 0.933,明显超过0.8,提示存在强共线性。在输出中,系统会自动用红色标识相关系数大于判断标准的项,方便用户快速定位问题变量。
2. 方差膨胀因子
相关系数矩阵只能判断两两之间的共线性,而方差膨胀因子(VIF) 能综合考察某一自变量被其他自变量预测的程度。其公式为:
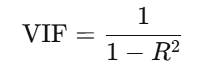
其中 R2是将该自变量作为因变量,对其他所有自变量回归后得到的决定系数。
判断标准如下:
- VIF < 5:共线性不严重
- 5 ≤ VIF < 10:存在中度共线性
- VIF ≥ 10:存在严重共线性
在实际研究中,部分严格场景下会以 VIF > 5 作为判断标准。
我们继续看SPSSAU的共线性诊断表:

可见,“人均教学设备”的VIF值高达 187.44,远超10的临界值,说明其几乎可以被其他变量完全线性表示。SPSSAU软件会自动计算VIF与容忍度,并对VIF>10或容忍度<0.1的项进行红色高亮,帮助研究者快速识别问题变量。
3. 条件指数与方差比例
在更严谨的学术研究中,还会使用条件指数(Condition Index) 和方差比例(Variance Proportion) 进行判断。通常认为:
- 条件指数 > 30:存在中度共线性
- 条件指数 > 100:存在严重共线性
由于该方法计算复杂,多数实用场景下VIF与相关系数矩阵已足够。
四、如何处理多重共线性?
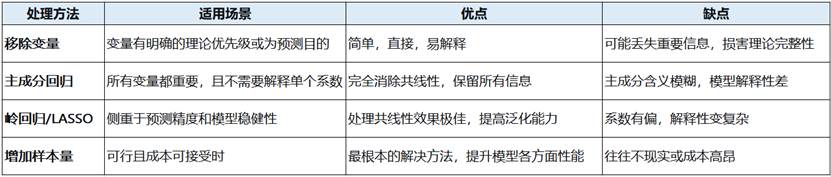
当诊断出模型中存在严重的多重共线性后,我们绝不能视而不见,否则所有基于该模型的推论都可能是建立在流沙之上。处理多重共线性不是一个简单的“是”或“否”的决策,而是一个基于研究目标、理论重要性和统计效力的综合权衡过程。以下是几种经过验证的、行之有效的处理策略,从最直接到最复杂,供研究者选择。
1. 移除高相关变量
这是最常用、也最易于理解的方法。核心思想是:既然变量A和变量B提供了高度重叠的信息,那么我们只需要保留其中一个即可。
操作步骤:
- 识别候选变量:通过相关系数矩阵和VIF表,找出哪些变量是“问题源”。通常,VIF值最高的变量是首要考虑移除的对象。
- 选择保留变量:这是关键一步,不应随意选择。应基于以下原则进行决策:
- 理论重要性:保留那个在理论框架中更核心、更具解释力的变量。例如,在研究教育投入的影响时,“人均教育投入”可能比“人均教学设备”更具根本性。
- 统计显著性:比较两个变量在单独回归中的显著性,保留与因变量关系更紧密的变量。
- 数据质量:保留那个测量更精确、数据更完整的变量。
- 业务可解释性:保留那个更容易向业务方或读者解释和理解的变量。
案例分析:
在我们的SPSSAU输出中,“人均教学设备”的VIF高达187.442,它与“人均图书”的相关系数也高达0.977。这意味着这两个变量几乎在传达同一信息——学校的物资装备水平。因此,我们可以根据理论,选择保留其中一个(比如“人均图书”),而将“人均教学设备”从模型中移除。移除后,需要重新运行回归和共线性诊断,观察剩余变量的VIF是否已降至可接受范围。
优点: 简单、快速、有效,能从根本上解决问题。
缺点: 可能会丢失部分信息,如果被移除的变量在理论上非常重要,会损害模型的内容效度。
2. 主成分回归
当所有存在共线性的变量在理论上都不可或缺时,直接移除就不可取了。此时,主成分分析 结合回归(称为主成分回归)是一个极佳的解决方案。
操作步骤:
- 提取主成分:对所有存在共线性的自变量进行主成分分析。PCA会将这群高度相关的原始变量转换为一组互不相关(正交)的新变量,称为主成分。
- 选择主成分:每个主成分能够解释原始变量集总方差的一部分。通常,我们选择前k个能够解释绝大部分方差(如80%或90%以上)的主成分。
- 进行回归:将这k个主成分作为新的自变量,与因变量进行回归分析。
原理:
主成分是原始变量的线性组合,它重新分配并浓缩了信息。第一个主成分捕捉了原始变量中最大的变异方向,第二个主成分捕捉与第一个正交的最大剩余变异,以此类推。由于主成分之间完全独立,共线性被彻底消除。
优点: 完全消除了共线性,并充分利用了所有原始变量的信息。
缺点: 主成分的含义往往难以解释,失去了对原始变量系数的直接解释能力。它更适用于预测模型,而非解释性模型。
3. 正则化回归
当你的目标是建立一个预测精度高且稳健的模型时,正则化方法 是非常强大的工具,其中最常用于处理共线性的是岭回归。
岭回归
- 原理:它在普通最小二乘法(OLS)的损失函数中,加入了一个惩罚项,这个惩罚项与系数平方和(L2范数)成正比。这个惩罚项的作用就是“收缩”系数,将那些因为共线性而变得异常大的系数向零压缩,从而获得一个更稳定、偏差稍大但方差更小的模型。
- 关键参数λ:惩罚的强度由一个参数λ(lambda)控制。λ=0时,岭回归退化为OLS;λ越大,收缩力度越强,系数越趋于零。λ的选择通常通过交叉验证来确定。
- SPSSAU的应用:在SPSSAU的“进阶方法”模块中提供了岭回归选项,用户可以自动或手动输入λ值,并直接得到结果,非常方便。
LASSO回归
- 原理:与岭回归类似,但它使用的惩罚项是系数绝对值之和(L1范数)。这种惩罚不仅能使系数收缩,甚至能将一些不重要的变量的系数直接压缩为0,从而实现变量筛选。
- 对比:岭回归倾向于保留所有变量但缩小其系数,而LASSO回归会进行变量选择,得到一个更稀疏的模型。
优点: 能有效处理高度共线性的数据,提高模型的泛化能力(预测新数据的能力)。
缺点: 由于系数被有偏地压缩,其解释性变差;且需要额外的步骤(如交叉验证)来确定最佳惩罚参数。
4. 增加样本量
多重共线性本质上是一个“数据信息不足”的问题。在样本量很小的时候,稍微有点相关的自变量都可能表现出较强的共线性。如果条件允许,增加样本量 是解决共线性最“自然”的方法。
原理:
更大的样本量提供了更多信息,能够更精确地估计每个自变量的独立效应,从而降低系数估计的方差,使模型对共线性不再那么敏感。原本VIF高达15的变量,在样本量大幅增加后,其VIF值可能会显著下降。
优点: 不仅能缓解共线性,还能全面提升模型的统计功效和稳健性。
缺点: 在许多研究中(如社会科学、医学),收集更多数据可能成本高昂或根本不现实。
5. 其他方法与综合策略
- 变量组合或变换:根据领域知识,将高相关变量组合成一个综合指数。例如,将“人均图书”和“人均教学设备”合并为一个“教学资源丰富度”指标。或者对变量进行中心化(减去均值)或标准化,这有时能改善数值计算稳定性,但对严重的共线性问题效果有限。
- 逐步回归:让算法基于某个标准(如AIC)自动进行变量的筛选与剔除。这是一种数据驱动的方法,但可能受到样本随机波动的影响,且结果可能不稳定。
- 坦然接受:在极少数情况下,如果研究的目的仅仅是预测,并且共线性结构在未来预测样本中保持不变,那么即使存在共线性,模型预测值可能仍然是可靠的。但此时,绝不能对模型系数进行任何解释。
总结与选择指南如下:
四、总结与建议
多重共线性是多元回归分析中的常见问题,但通过系统诊断和适当处理,完全可以将其影响控制在可接受范围内。
操作建议:
- 建模前:检查自变量相关系数矩阵,避免引入高度相关的变量。
- 建模后:务必检查VIF值,确保所有变量VIF < 10(严格场景下<5)。
- 发现问题后:优先考虑移除变量,若需保留所有变量,可考虑主成分回归或岭回归。
工具选择:像SPSSAU这样的平台极大地简化了这个过程。你可以在“线性回归”中快速完成VIF诊断,根据智能分析建议尝试移除变量;也可以轻松地在“进阶模型”中找到岭回归和主成分分析功能,进行对比分析,从而在专业指导下做出最合适的选择。

















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









