



在空间计量经济学的工具箱中,空间误差模型(Spatial Error Model, SEM)扮演着一个独特而关键的角色。如果说空间杜宾模型(SDM)旨在主动探索变量间的空间互动机制,那么SEM则更像一位精细的“修复师”,它的首要任务是纠正因空间依赖性存在于误差项中 而导致的模型设定偏误。理解SEM,不仅能完善我们的空间分析知识体系,更能在面对特定类型的数据问题时,选择最锋利的工具。
一、 空间误差模型(SEM)的理论定位与核心思想
当我们使用普通最小二乘法(OLS)进行回归分析时,一个基本假设是误差项之间相互独立。然而,在空间数据中,这个假设经常被打破。这种打破可能并非源于我们关心的核心变量(如收入、政策)之间的相互影响,而是由一些未被观测到的因素所导致。
试想一下:
- 研究各地区犯罪率时,我们可能无法完美量化“社会凝聚力”或“治安执法效率”等隐性变量。
- 这些未被纳入模型的变量,其本身可能就具有空间相关性(例如,相邻地区共享相似的文化氛围或治理水平)。
在这种情况下,模型的误差项就不再是“白噪声”,而是包含了空间结构。如果忽略这种结构,尽管自变量的回归系数估计仍可能是无偏的,但其标准误的估计将是错误的,从而导致基于t检验或z检验的统计推断(p值)失效,我们可能会错误地判断一个变量的显著性。
空间误差模型(SEM)正是为此而生。其数学模型如下:
y = Xβ + u, u = λWu + ε
让我们解析这个模型的核心构成:
- y = Xβ + u:这部分与经典线性回归模型一致。y是因变量,X是自变量矩阵,β是待估计的回归系数,u是随机误差项。
- u = λWu + ε:这是SEM的灵魂。它指出,误差项 u 本身存在空间自回归结构。
- Wu:是误差项 u 的空间滞后项,由空间权重矩阵 W 计算得出,代表了邻近地区的误差项对本地区误差项的影响。
- λ:是空间误差自相关系数。它是模型的核心参数,衡量了这种误差项间空间依赖性的强度和方向。如果 λ = 0,模型就退化为OLS回归。
- ε:是均值为0、方差为常数的“纯粹”的随机扰动项,满足了经典假设。
SEM的理论定位非常明确: 它主要用于处理“ nuisance ”的空间依赖性——即那些我们不关心其具体来源,但必须予以纠正的、存在于扰动项中的空间相关性。SPSSAU在模型设定中清晰地标识了这一关键参数 Lambda,使用户能够直接关注到这一核心。
二、 SEM分析的核心流程与SPSSAU输出解读框架
在SPSSAU中进行SEM分析,其流程清晰而严谨。整个过程围绕着模型估计、诊断和与其它模型的比较展开,最终引导我们得出可靠的结论。
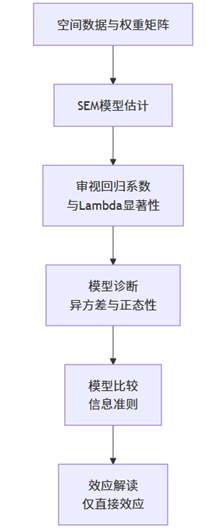
与分析SDM等不同,SEM的解读路径相对简洁,核心在于确认误差空间依赖性(λ)的存在,并正确解读在考虑此依赖性后的自变量回归系数。
1. 模型基本参数表
在SPSSAU的输出中,首先呈现的是“模型基本参数”表格。

上表格明确告知读者本研究使用的是空间误差SEM模型,并列出了所使用的空间权重矩阵名称、标准化方式、样本量以及估计方法(如极大似然估计ML)。这些信息对于任何严肃的学术研究都是必不可少的。SPSSAU将此表格前置,体现了其输出结果的规范性与专业性。
2. 模型分析结果表
这是SEM模型输出的核心,以“空间误差SEM模型分析结果”表格呈现。它包含了常数项、各自变量的回归系数、标准误、z值、p值,以及最为关键的 Wu(残差空间滞后变量)(Lambda) 项。
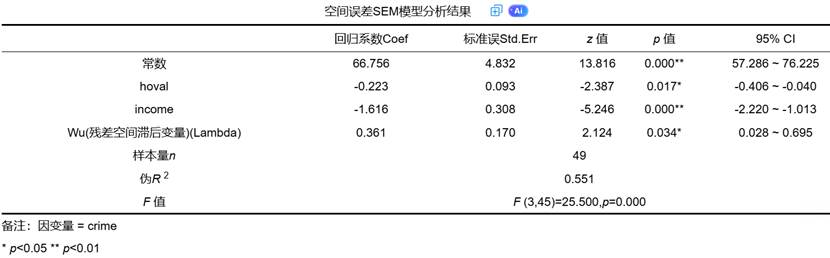
- 自变量回归系数(β):在SEM框架下,这些系数代表了在控制了误差项的空间依赖性之后,自变量对因变量的“净影响”或“直接影响”。此时的估计更为纯净,统计推断更为可靠。研究者可据此判断一个变量是否对因变量存在 statistically significant 的影响。
- Lambda (λ) 系数:这是SEM模型的“心跳”。一个显著的 Lambda(p值 < 0.05)是支持使用SEM模型而非OLS的强有力证据。它证实了误差项中确实存在空间自相关,SEM模型的纠正是必要且有效的。SPSSAU的智能分析会重点强调此项的显著性。
3. 空间效应表
SEM模型也会输出一张“空间效应”表格,但其内容与SDM模型有本质区别。

在SEM模型中,自变量的影响只有直接效应,间接(溢出)效应和总效应栏位通常显示为“-”或不可计算。这是因为SEM的设定决定了自变量 X 的变化只会通过改变本地区的 y 来产生影响,而不会像SDM那样通过 WX 机制直接波及邻区。误差项的空间依赖性(λWu)虽然造成了区域间的联动,但这种联动被归结于随机扰动,而非由解释变量 X 驱动的、可解释的溢出效应。
因此,这张表格的作用在于明确告知研究者:在SEM框架下,我们仅能讨论自变量对本地区的直接影响。 这是SEM与SDM、SLM等模型在结论解释上的一个根本性差异。
4. 模型诊断与比较:为模型选择提供依据
这部分包括“相关检验汇总”和“信息准则指标结果”等表格。
- Breusch-Pagan (BP) 检验:用于检验修正了空间误差后,模型是否存在异方差问题。如果存在,可能需要使用SPSSAU提供的“Robust稳健标准误”选项再次进行估计,以确保结果稳健。
- Jarque-Bera (JB) 检验:用于检验模型最终的残差 ε 是否服从正态分布。这在极大似然估计法下是重要的辅助诊断。

- 信息准则(AIC, SC):这些指标在模型比较中至关重要。当我们在SDM、SEM、SLM等多个空间模型之间犹豫时,一个普遍的原则是选择AIC和SC值较小的模型,因为它通常意味着在模型复杂度和拟合优度之间取得了更好的平衡。SPSSAU提供这些指标,方便用户进行数据驱动的模型选择。

三、 何时选择SEM?
选择SEM模型,通常基于以下考量:
- 理论基础:研究者从先验知识判断,空间依赖性主要来自于那些未被观测的、遗漏的变量,而非核心变量之间的直接互动。
- 统计检验:在模型筛选阶段,拉格朗日乘数(LM)检验结果强烈支持SEM over OLS 或其他空间模型。
- 研究目标:研究者的兴趣在于准确估计自变量的局部直接影响,而非探索空间溢出机制。
在这些场景下,SPSSAU展现了其强大的易用性与专业性:
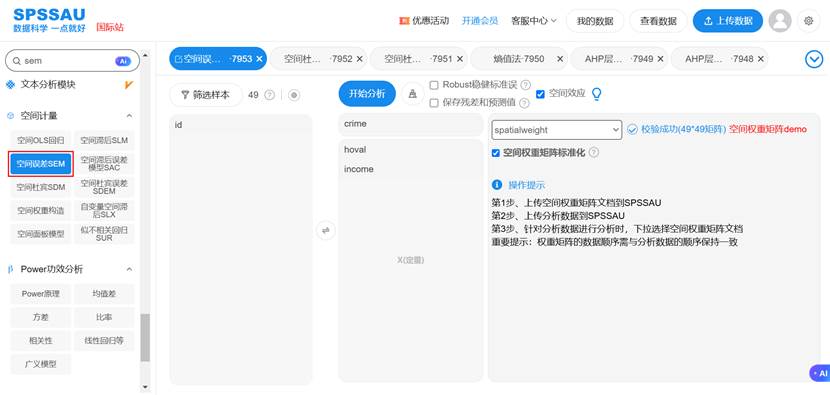
- 一键式分析:用户只需上传数据和空间权重矩阵,选择“空间误差模型”,SPSSAU即可自动完成所有复杂的矩阵运算和极大似然估计,输出包括系数、检验、效应分解在内的完整结果。
- 清晰的逻辑引导:SPSSAU的输出结构完全遵循前述分析流程,引导用户从基本参数审视到核心系数解读,再到模型诊断,最后通过信息准则进行横向比较,思路清晰,不易混乱。
- 智能分析辅助:其内置的智能文本能自动提示 Lambda 的显著性,帮助用户快速抓住SEM模型的关键证据,降低了空间计量的理解门槛。
SPSSAU操作示例如下:
四、 总结
空间误差模型(SEM)是空间计量经济学中一个功能纯粹而强大的模型。它通过对误差项的空间结构进行建模,有效地纠正了传统回归方法在空间数据上可能导致的统计推断错误。
SPSSAU将这一模型完整地、友好地呈现给所有研究者。通过其系统化的输出框架,用户可以轻松地完成从模型设定、参数估计、显著性判断到模型比较的全过程,从而能够将更多的精力投入到理论思考与结果阐释中,而非纠结于复杂的技术实现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









