




随着大语言模型(LLM)逐步走向工程化与规模化部署,其推理效率、资源利用率以及硬件适配能力正成为影响应用落地的核心问题。2023 年,加州大学伯克利分校的研究团队开源 vLLM,通过引入 PagedAttention 机制对 KV 缓存进行高效管理,显著提升模型吞吐量与响应速度,在开源社区迅速走红。截至目前,vLLM 在 GitHub 上已突破 47k stars,是大模型推理框架中的明星项目。
2025 年 1 月 27 日,vLLM 团队发布 v1 alpha 版本,在过去近两年的开发基础上对核心架构进行系统性重构,从某种程度上讲,这也标志着 vLLM 正从推理加速引擎升级为更灵活、更通用的大语言模型部署基础设施。
此次更新的 v1 版本核心在于执行架构的全面重构,引入隔离式 EngineCore,专注模型执行逻辑,采用多进程深度整合,通过 ZeroMQ 实现 CPU 任务并行化多进程深度整合,显式分离 API 层与推理核心,极大提升了系统稳定性。同时,引入统一调度器(Unified Scheduler),具备调度粒度细、支持 speculative decoding、chunked prefill 等特性,在保持高吞吐量的同时提升延迟控制能力。
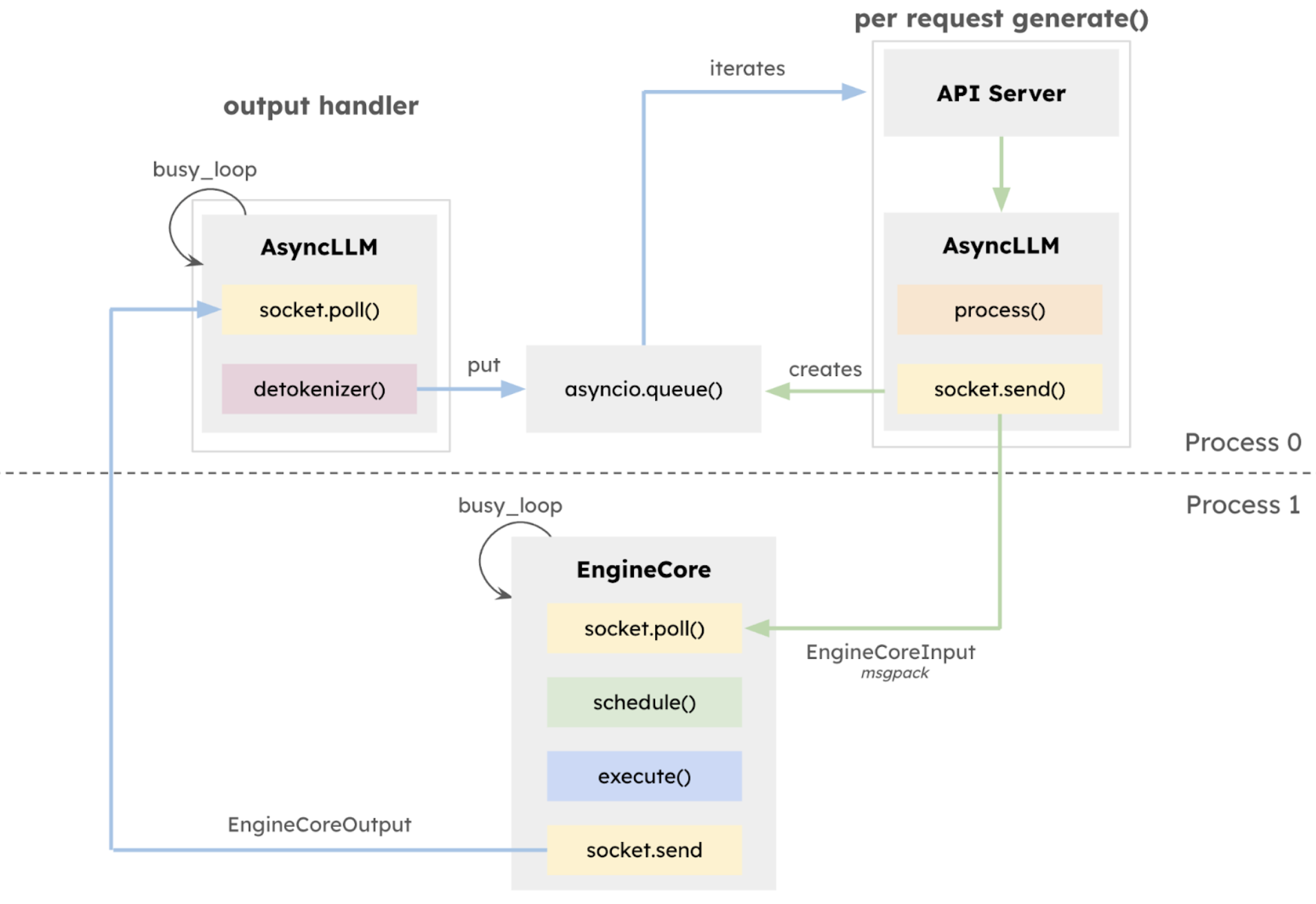
VLLM v1 的多进程处理架构及数据流向图
此外,vLLM v1 突破性采用无阶段调度设计,优化了用户输入和模型输出 token 的处理方式,简化了调度逻辑。该调度器不仅支持分块预填充(chunked prefill)和前缀缓存(prefix caching),还能够进行推测解码(speculative decoding),有效提高推理效率。
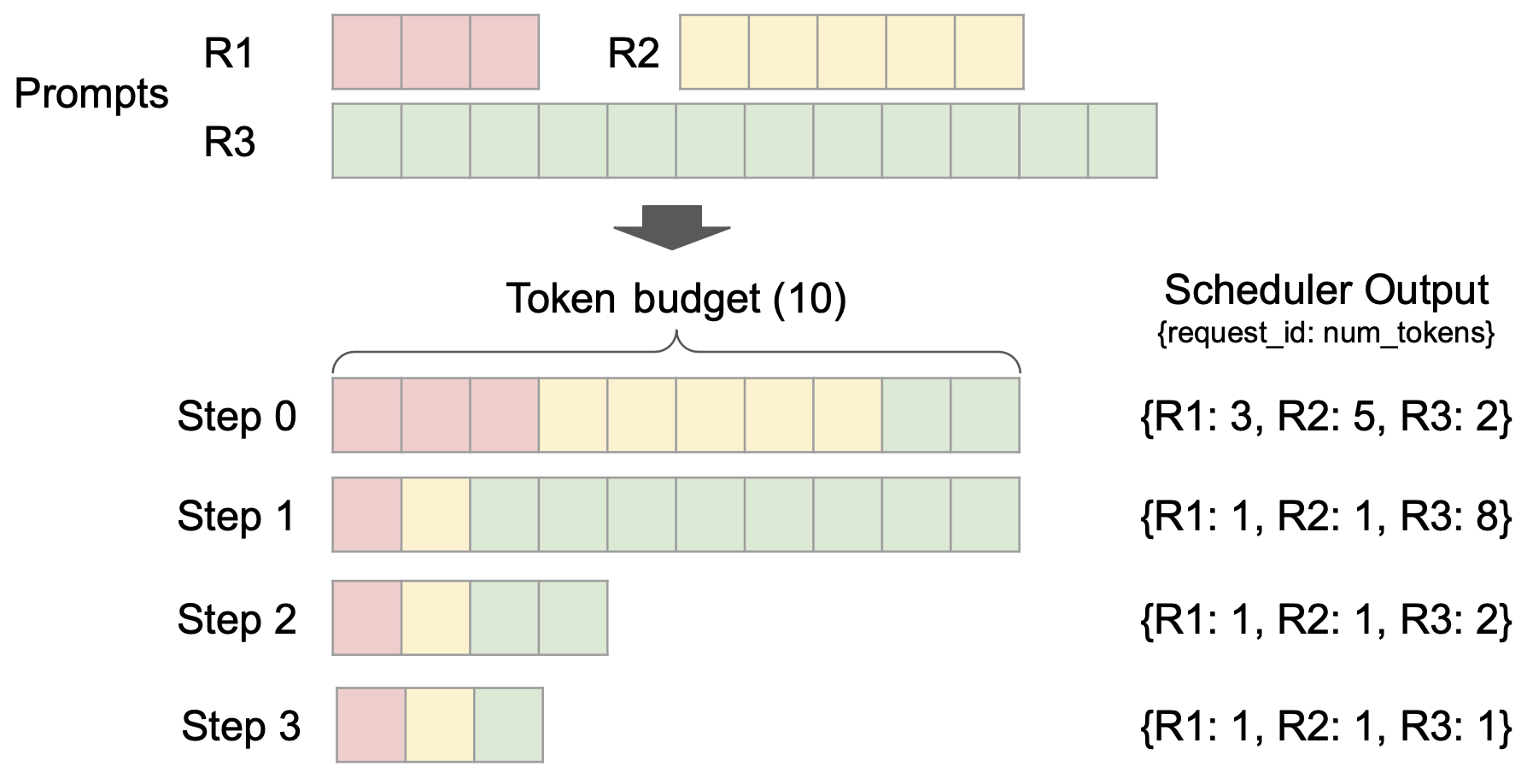
不同请求的调度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7130
7130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









