



 文章讲述了如何利用GPU加速计算,重点在于配置CUDA环境,包括检查和安装driverCUDA和toolkitCUDA,以及处理可能出现的问题。作者强调了版本匹配和添加环境变量的重要性,并提供了简单的CUDAC++测试程序来验证安装是否成功。
文章讲述了如何利用GPU加速计算,重点在于配置CUDA环境,包括检查和安装driverCUDA和toolkitCUDA,以及处理可能出现的问题。作者强调了版本匹配和添加环境变量的重要性,并提供了简单的CUDAC++测试程序来验证安装是否成功。
的一 前言
最近写了个又臭又长的代码来验证idea,效果还行但速度太慢,原因是代码中包含了一个很耗时的模块,这个模块需要连续执行百次以上才能得到最终结果,经过实测模块每次执行消耗约20ms,而且两次执行之间没有先后关系,为了保证系统的实时性,我决定将这一部分运算放在GPU上执行。
二 环境配置(dirver CUDA + runtime CUDA)
要想使用GPU加速计算,首先需要一块性能还可以的Nvidia显卡(并不是所有的N卡都可以,需要RTX900系列及以上),我的是海鲜市场500块买的GTX 1060 6G版本,韩巨说这张卡虽然有点跟不上时代,但是做个小规模C++加速、训练个几万参的pytorch网络还是轻轻松松的。
2.1检查自己的系统
一个电脑里可以拥有两个CUDA API,一个是dirver CUDA(显示屏幕用的),一个是toolkit CUDA(加速深度学习),这两个API大多数人都是分开安装的(如果你都没有安装,例如你是新装的系统,或者是新插入的新卡,那么也可同时安装,同时安装的方法本文也写了),在正式安装前,应该先知道自己缺什么,否则如果系统中已有且没卸载,就会导致安装失败。
你可以通过nvidia-smi查看自己是否安装了dirver CUDA,
nvidia-smi通过查找系统中是否有CUDA工具箱来确认自己是否安装了toolkit CUDA,
locate CUDA_Toolkit2.2缺哪个装哪个
(1)dirver CUDA的安装:【参考链接】
注意,先禁用,否则容易驱动不匹配导致黑屏
sudo gedit /etc/modprobe.d/blacklist.confblacklist nouveau
options nouveau modeset=0
driver cuda的安装方法有多种,我是直接用图形化界面一键安装的,具体过程参考上面链接
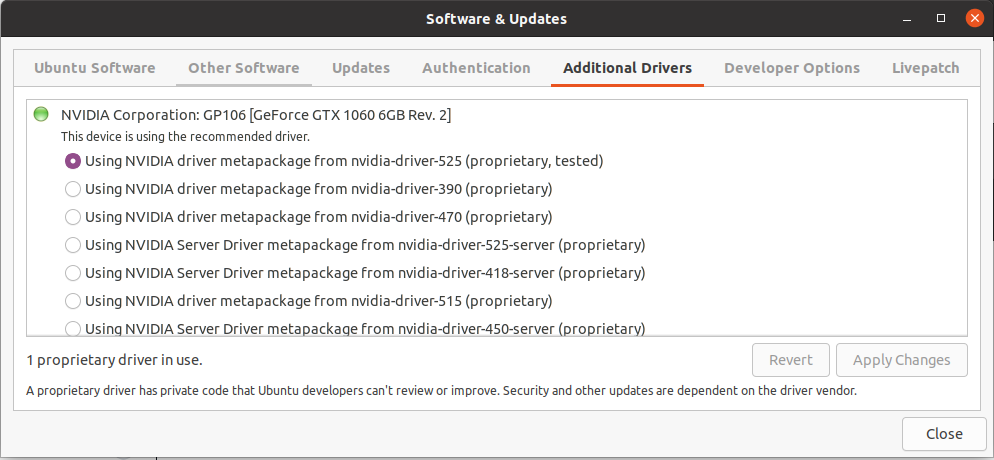
安装显示驱动可能会出现黑屏、无法双屏、只能双屏不能单屏等问题,解决方案也请查看我上面给的链接。
(2)toolkit CUDA的安装:【参考链接】
我认为这个安装的重点是要选对版本,cuda_toolkit的版本不能高于dirver cuda的版本,我们可以通过nvidia-smi查看dirver cuda的版本:
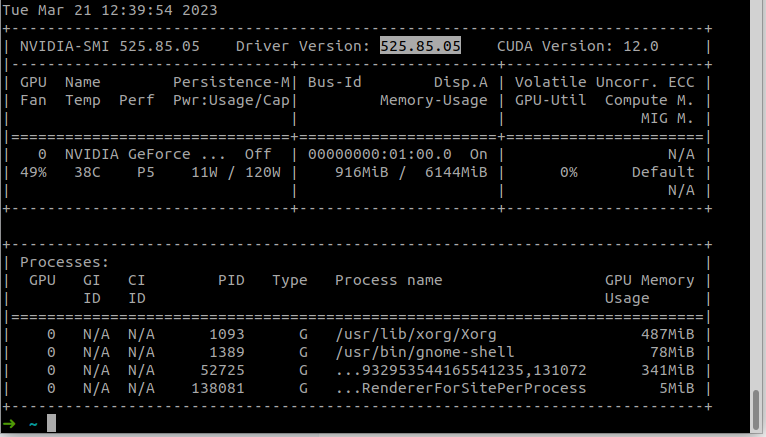
根据dirver cuda的版本,我们在toolkit下载官网选择满足要求的toolkit进行下载即可,cuda_toolkit的版本可以在生成的代码中看到:
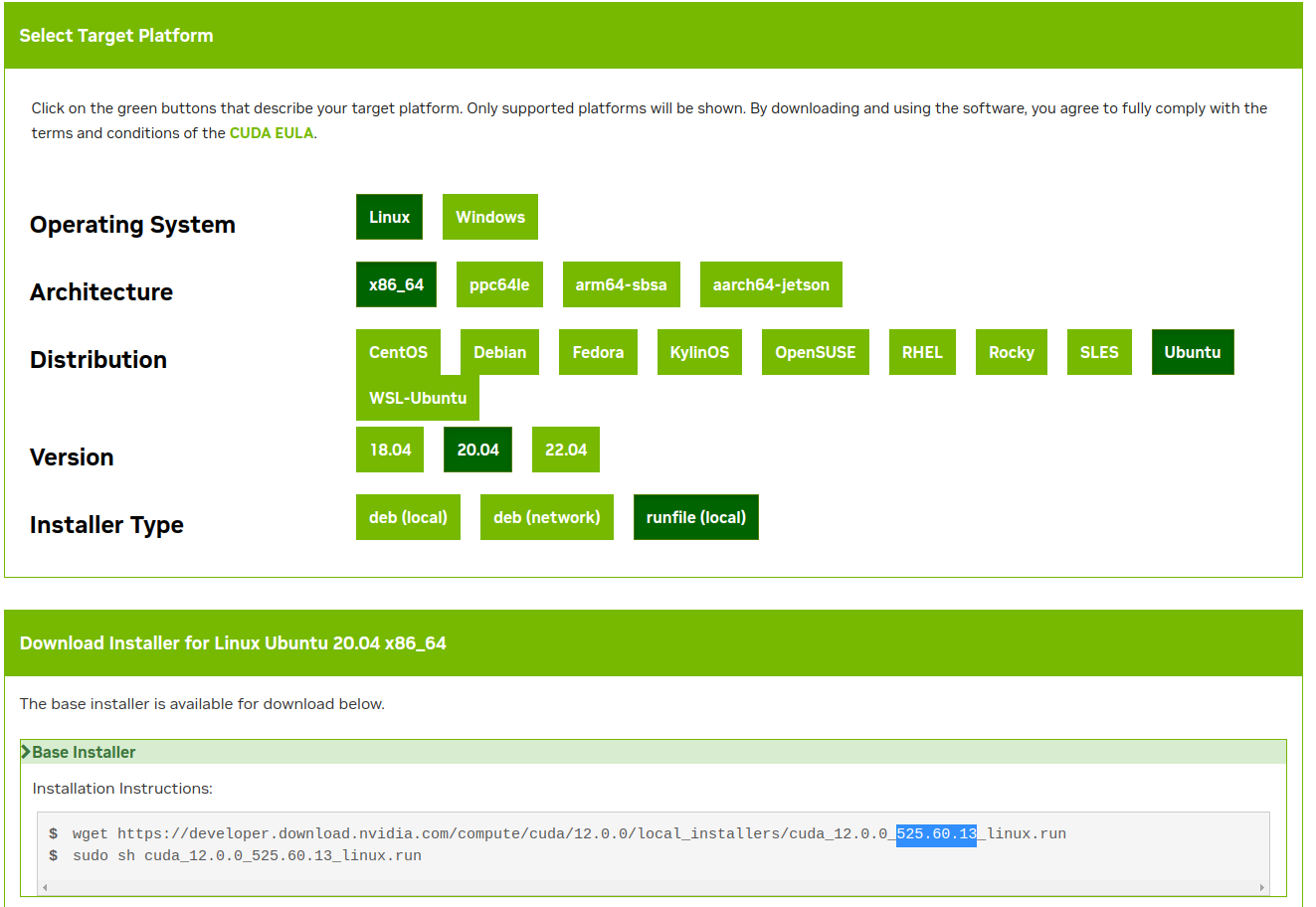
如果当前的toolkit满足你的版本要求,那么就新建个文件夹,在文件夹里执行生成安装命令的第1行:
wget xxxx #写你自己的将安装包下载下来之后,先不要急着执行sh安装,先下载依赖:
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev然后再执行安装:
sudo sh xxxx.run #写你自己的执行安装程序后跟着引导走就行,这里需要注意:
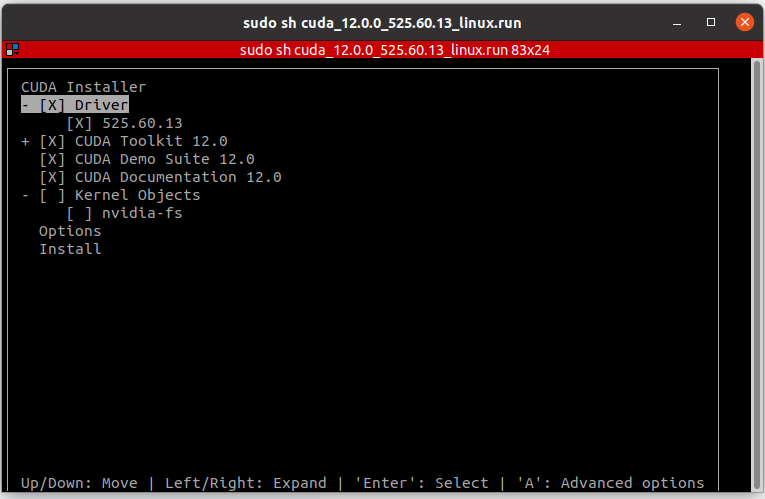
如果你已经安装了dirver CUDA,那就把Driver前的X去掉,如果你driver和toolkit都没装,那么就都选上,其实对于新装的系统or新插入的显卡,完全没必要分开装,直接在这里一起装了是最省时间的
最后不要忘了在.bashrc或.zshrc中添加cuda的路径:
#注意,你安装的并不一定是cuda-12.0,你要根据自己的版本写
export PATH=$PATH:/usr/local/cuda-12.0/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.0/lib64
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda-12.0/lib642.3 C++CUDA测试
安装完后,可以写一个简单的cuda加速程序,看一下是否可以运行【参考链接】


















 2711
2711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









