




今日任务:
- 假设检验基础知识:原假设备与择假设;P值、统计量、显著水平、置信区间
- 白噪声:定义;自相关性检验(ACF和Ljung-Box检验);偏自相关性(PACF检验)
- 平稳性:定义;单位根ADF检验
- 季节性检验:ACF检验;序列分解(趋势+季节性+残差)
作业:自行构造数据集,来检查是否符合这个要求
一、假设检验
假设检验:证明正确很困难,先假设反面,用证据推翻反面,从而论证正面的正确性。
1.1 原假设与备择假设
在假设检验中,存在两个假设:一个是保守的、现状的、需要强证据才能推翻的假设作为原假设 (H₀),另一个是它的反面(要证明的)作为备择假设(H₁)。
用法律类比:
- H₀ (无罪):原假设,状态清晰且单一。直接证明比较困难
- H₁ (有罪):备择假设,需要证明的东西。从多样的罪状中找到一条证明即可
1.2 P值与统计量
投硬币:
原假设 (H₀):你的朋友是普通人,没有特异功能。(对应“嫌疑人无辜”)
备择假设 (H₁):你的朋友真的有特异功能。(对应“嫌疑人有罪”)
收集证据:抛一枚公平的硬币10次。结果他抛出了 8次正面,2次反面。预期结果为1:1。
(1)统计量:测量值,衡量证据偏离原假设的程度。这里是正面次数8
(2)P值:在原假设(H₀)为真的前提下,出现当前观测结果,或比当前结果更极端结果的概率。回答“原假设若为真,证据为巧合的概率”。在这个例子里:在一个公平硬币的世界里,出现“统计量 ≥ 8”(即抛出8次、9次或10次正面)这种程度的偏离,是件很容易发生的事,还是件极其罕见的事?
(3)显著水平(α):判断的门槛,“定罪标准”,一般为0.05。
- P值 < 0.05:说明证据强度足够。如果H₀是真的,不太可能是巧合(小概率事件却发生了)。于是我们拒绝原假设。
- P值 ≥ 0.05:说明证据强度不够。如果H₀是真的,证据虽然不常见,但还算是一种合理的巧合。于是我们不拒绝原假设。
(4)置信区间:根据参数可能存在的合理范围,来推断原假设值出现的巧合性
- 原假设的值在置信区间之外:P值 < 0.05,拒绝原假设
- 原假设的值在置信区间之内:P值 > 0.05,不拒绝原假设
实际上,假设检验在序列预测中可以帮助判断看到的模式是真实的规律,还是仅仅是数据中的随机噪声。
二、白噪声
一个完全随机的序列,是无法让模型学习到规律的,因为数据本身就不具备可预测性,这样的序列就是白噪声。白噪声需要满足以下条件:
- 均值为0
- 方差稳定
- 自相关性为0(核心):自相关性是指在一个序列中,当前值与过去值之间的关联程度。
# 生成随机序列
np.random.seed(42) # 随机种子,结果可复现
num_points = 200 # 定义序列的长度
# 生成一个包含 200 个点的随机序列
# np.random.randn() 从标准正态分布(均值为0,方差为1)中抽取随机样本
random_sequence = np.random.randn(num_points)在检验一个数据是否为白噪声时,可以上面三个条件入手。
2.1 均值为0
# 检验 1: 均值是否接近 0
mean = np.mean(random_sequence)
print(f"1. 序列的均值: {mean:.4f}")
if -0.1 < mean < 0.1:
print(" (结论: 均值非常接近0,满足条件。)\n")
else:
print(" (结论: 均值偏离0较远。)\n")2.2 方差稳定
# 检验 2: 方差是否恒定(且接近理论值1)
# 对于我们生成的数据,方差恒定是与生俱来的。我们主要检查其值。
variance = np.var(random_sequence)
print(f"2. 序列的方差: {variance:.4f}")
if 0.8 < variance < 1.2:
print(" (结论: 方差接近于1,满足条件。np.random.randn理论方差为1)\n")
else:
print(" (结论: 方差偏离1较远。)\n")2.3 自相关性为0(核心)
作为最核心的自相关性检查存在以下三种方式:ACF检验、PACF检验、Ljung-Box检验。
2.3.1 ACF:自相关函数图
ACF测量的是X{t} 与 X{t-k} 之间的总相关性,“总相关性”包含了所有中间值(X{t-1},X{t-2},..., X{t-k+1})的间接影响。
from statsmodels.graphics.tsaplots import plot_acf
# 创建一个新的图形来绘制ACF图
fig, ax = plt.subplots(figsize=(12, 5))
plot_acf(random_sequence, lags=30, ax=ax) # 我们查看前30个滞后的相关性
ax.set_title('序列的自相关函数图 (ACF Plot)')
ax.set_xlabel('Lag (滞后阶数)')
ax.set_ylabel('Autocorrelation (自相关系数)')
plt.grid(True, linestyle='--', alpha=0.6)
plt.show()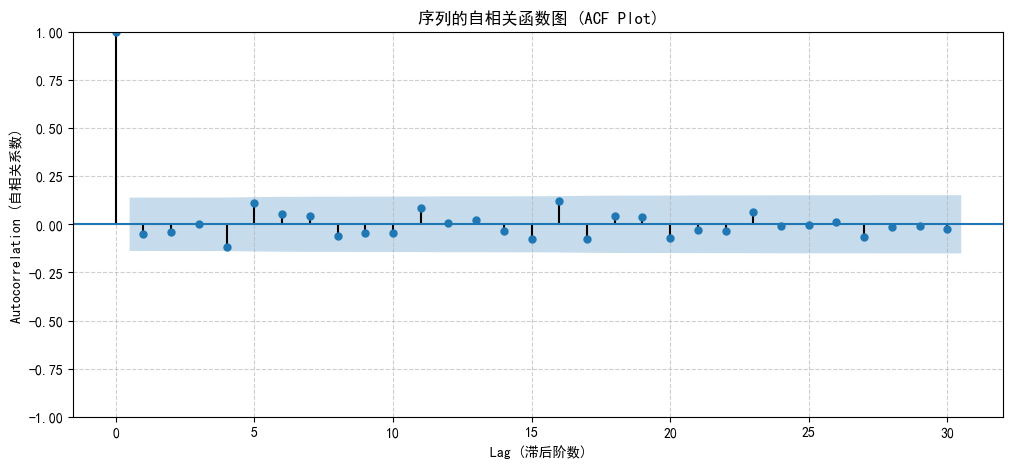
- 纵轴:自相关系数,即相关性强弱
- 横轴:滞后阶数(Lag),Lag=k,即t 时刻的值与 t-k 时刻的值之间的相关性
- 蓝色区域:95%置信区间。如果相关系数的柱子落在这个区域内,我们就认为它的相关性从统计学上看不显著,可以当作是0。
2.3.2 PACF:偏自相关函数图
PACF测量的是在控制了中间的所有值(X{t-1}, X{t-2}, ..., X{t-k+1})之后(去除中间时刻的干扰), X{t} 与 X{t-k} 之间的直接相关性。
from statsmodels.graphics.tsaplots import plot_pacf # 引入PACF图
# --- 绘制PACF图 ---
fig, ax = plt.subplots(figsize=(12, 5))
plot_pacf(random_sequence, lags=30, ax=ax)
ax.set_title('序列的偏自相关函数图 (PACF Plot)')
ax.set_xlabel('Lag (滞后阶数)')
ax.set_ylabel('Partial Autocorrelation')
plt.grid(True, linestyle='--', alpha=0.6)
plt.show()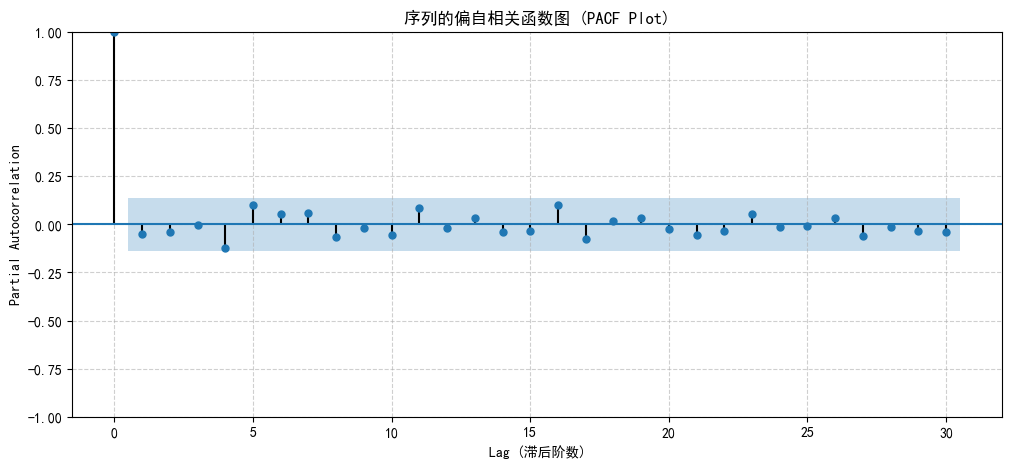
2.3.3 Ljung-Box检验
Ljung-Box检验是一个整体的、基于假设检验的方法。它不再是看单个滞后期,而是联合检验前 m 个滞后期(比如前10阶或20阶)的ACF是否整体上接近于0。
from statsmodels.stats.diagnostic import acorr_ljungbox
print(" - 原假设(H₀): 序列是白噪声。")
print(" - 判断标准: 如果 p-value > 0.05,则接受原假设,认为序列是白噪声。")
# 执行Ljung-Box检验
# 我们通常会检查一系列的滞后项,比如前10、20、30个
# 函数返回一个包含统计量和p值的DataFrame
ljung_box_result = acorr_ljungbox(random_sequence, lags=[10, 20, 30], return_df=True)
print(ljung_box_result)# 打印检验结果
# 我们可以检查最后一个(最严格的)p值
# .iloc[-1] 获取最后一行, .loc['lb_pvalue'] 获取p值
last_p_value = ljung_box_result.iloc[-1]['lb_pvalue']
if last_p_value < 0.05:
print(f"在滞后30阶时,p-value ({last_p_value:.4f}) 小于 0.05。")
print("结论:我们拒绝原假设,该序列不是白噪声。")
else:
print(f"在滞后30阶时,p-value ({last_p_value:.4f}) 大于 0.05。")
print("结论:我们无法拒绝原假设,该序列是白噪声。")关于检验结果的说明:
- 第一列 lb_stat:Ljung-Box统计量的值。
- 第二列 lb_pvalue:p值。
- 行索引 10, 20, 30:前10个、前20个、前30个滞后项的自相关性。
可以看到所有的p值都远大于0.05,即原假设(白噪声)成立。
| lb_stat | lb_pvalue | |
| 10 | 8.849179 | 0.546474 |
| 20 | 18.26404 | 0.57002 |
| 30 | 21.00065 | 0.887868 |
小结:可以先可视化进行快速检查后,使用Ljung-Box检验查看p值,进行统计性分析。
| 方法 | 视角 | 输出 | 在白噪声检验中的优势 |
|---|---|---|---|
| ACF/ PACF图 | 微观、可视化 | 图形 | 直观,能看到在哪一阶可能存在相关。 |
| Ljung-Box检验 | 宏观、定量 | P值 | 客观,提供一个明确的统计结论;综合判断多阶滞后的整体情况。 |
三、平稳性
平稳性:序列的统计特性不会随时间的变化而变化,从而确保序列的规律可重复、可学习。
而检验平稳性使用的方法是:ADF检验(单位根检验)。同样地,ADF检验也是假设检验,说明:
- 原假设:序列是非平稳的(存在单位根)
- 备择假设:序列是平稳的
- 判断(p-value): p < 0.05,拒绝原假设,采纳备择假设,即序列是平稳的;p ≥ 0.05,无法拒绝原假设,即序列是非平稳的。
# 引入ADF检验的函数
from statsmodels.tsa.stattools import adfuller
# --- 新增:使用ADF检验来判断平稳性 ---
print("开始进行ADF平稳性检验...")
# 执行ADF检验
# adfuller()函数会返回一个包含多个结果的元组
adf_result = adfuller(random_sequence)
# 提取并展示主要结果
adf_statistic = adf_result[0]
p_value = adf_result[1]
critical_values = adf_result[4]
print(f"ADF统计量 (ADF Statistic): {adf_statistic:.4f}")
print(f"p值 (p-value): {p_value:.4f}")
print("临界值 (Critical Values):")
for key, value in critical_values.items():
print(f' {key}: {value:.4f}')
print("\n--- 检验结论 ---")
# 根据p值进行判断
if p_value < 0.05:
print(f"p-value ({p_value:.4f}) 小于 0.05,我们强烈拒绝原假设(H₀)。")
print("结论:该序列是平稳的 (Stationary)。")
else:
print(f"p-value ({p_value:.4f}) 大于或等于 0.05,我们无法拒绝原假设(H₀)。")
print("结论:该序列是非平稳的 (Non-stationary)。")
# 也可以通过比较ADF统计量和临界值来判断,结论是一致的
if adf_statistic < critical_values['5%']:
print("\n补充判断:ADF统计量小于5%的临界值,同样表明序列是平稳的。")
四、季节性检验
季节性:时间序列中以固定、已知的频率重复出现的模式或周期性波动。比如冰淇凌的销量(夏天高,冬天低),用电量等。
注意:季节性不等于周期性。周期性是不固定且变化的频率,周期长度不固定且相对较长,可预测性较低。
生成季节性数据后,使用三种方法进行观察:
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.graphics.tsaplots import plot_acf
# 显示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False
# --- 1. 创建一个带季节性的序列 ---
# 我们模拟一个为期5年的月度数据(60个点)
num_points = 60
time = np.arange(num_points)
# a. 创建一个线性趋势
trend = 0.5 * time
# b. 创建一个季节性成分(周期为12个月)
# 使用sin函数来模拟年度周期性波动
seasonal_component = 15 * np.sin(2 * np.pi * time / 12)
# c. 创建一些随机噪声
np.random.seed(10)
noise = np.random.randn(num_points) * 2
# d. 合成最终序列
seasonal_data = trend + seasonal_component + noise4.1 可视化原始数据(肉眼观察)
# 方法一:肉眼观察
print("--- 方法一:肉眼观察 ---")
plt.figure(figsize=(14, 6))
plt.plot(seasonal_data)
plt.title('带趋势和季节性的时间序列图', fontsize=16)
plt.xlabel('时间步 (月)')
plt.ylabel('值')
plt.grid(True, linestyle='--', alpha=0.6)
plt.show()
可以清晰地看到一个整体上升的趋势,以及每年重复的波峰和波谷(季节性)。
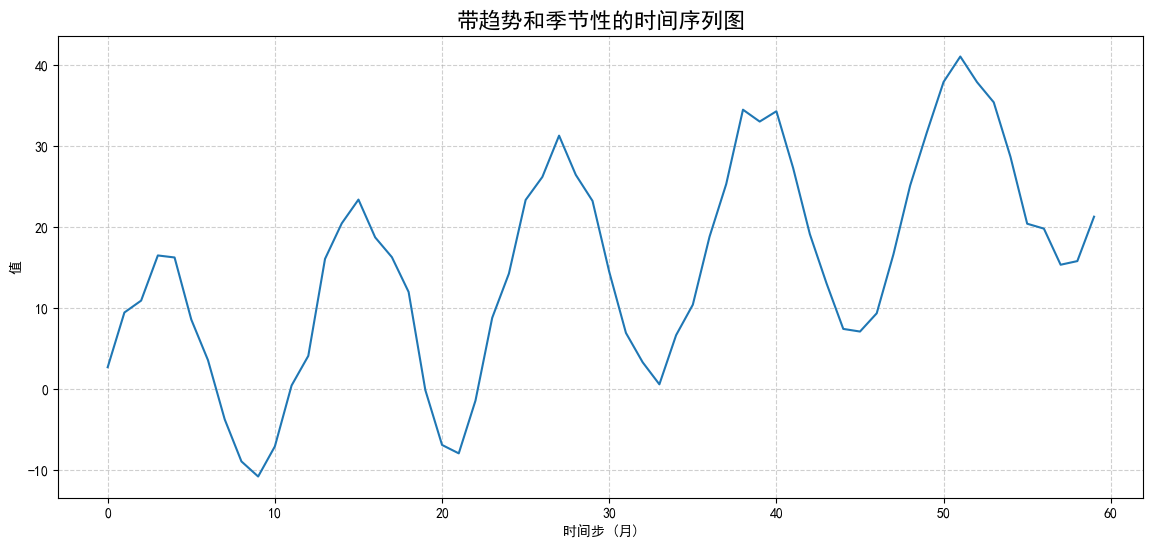
4.2 ACF图
如果一个序列存在季节性,它的ACF图会呈现出非常独特的形态:在代表季节性周期的滞后点上出现显著的尖峰。对于月度数据(年度季节性,周期为12),在 lag=12, 24, 36, ... 的位置看到很高的相关性柱子。因为今年1月的数据和去年1月的数据高度相关,和前年1月的也相关。
# 方法二:ACF图
print("\n--- 方法二:ACF图 ---")
fig, ax = plt.subplots(figsize=(14, 6))
plot_acf(seasonal_data, lags=30, ax=ax)
ax.set_title('季节性序列的ACF图')
plt.grid(True, linestyle='--', alpha=0.6)
plt.show()
不仅整体缓慢下降(表明有趋势),更重要的是在lag=12和24的位置出现了明显的峰值!
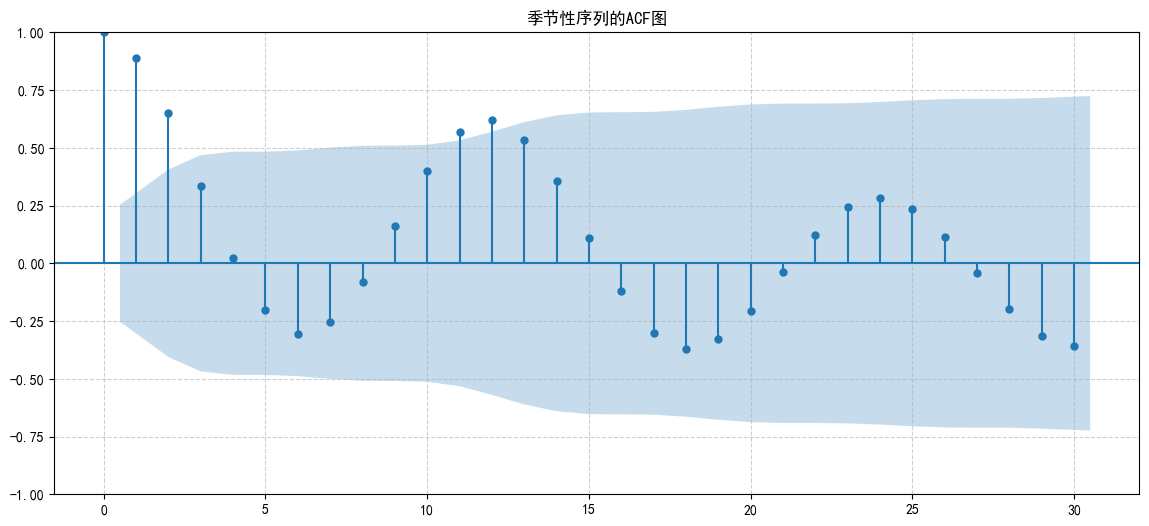
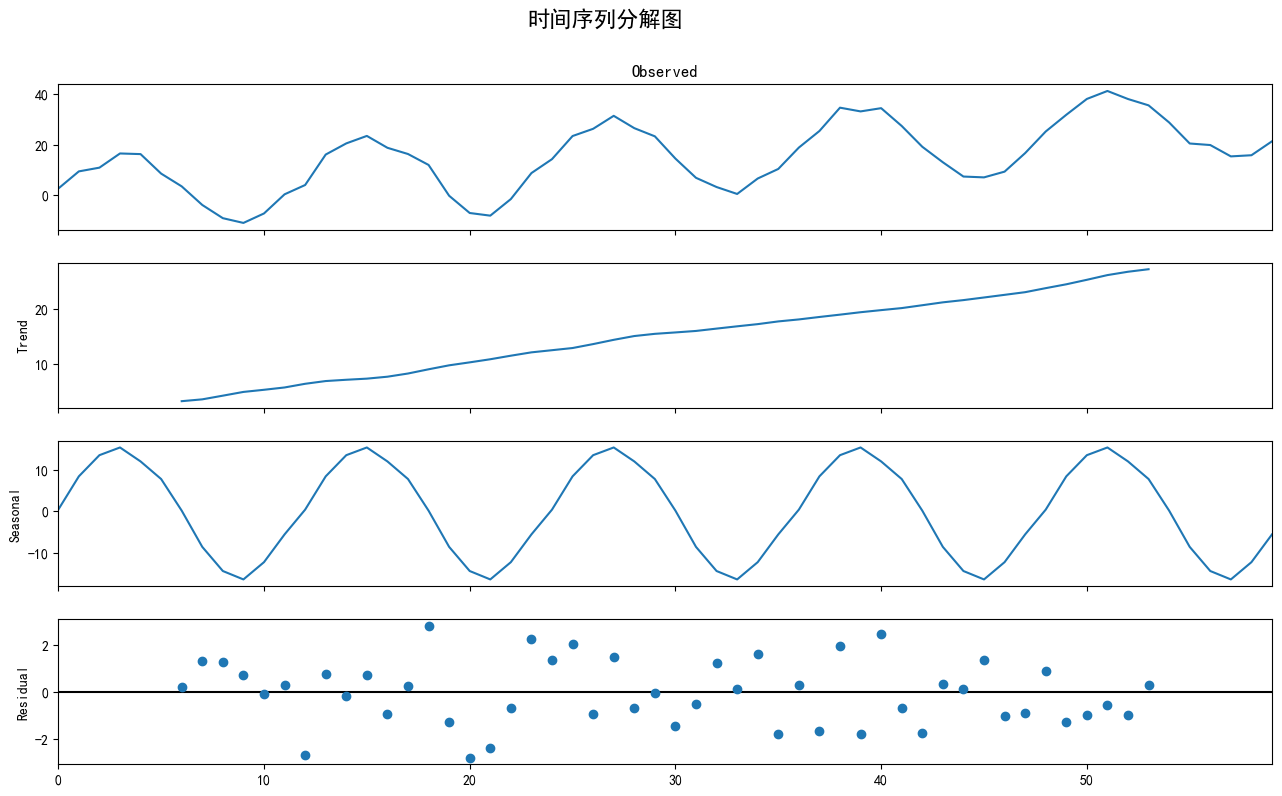
4.3 序列分解
# 方法三:序列分解
print("\n--- 方法三:序列分解 ---")
# 使用statsmodels进行分解(假设为加法模型)
decomposition = seasonal_decompose(seasonal_data, model='additive', period=12)
# 绘制分解图
fig = decomposition.plot()
fig.set_size_inches(14, 8)
plt.suptitle('时间序列分解图', y=1.02, fontsize=16)
plt.show()
分解图清晰地将数据拆分成了趋势、季节性和残差。季节性部分呈现完美的年度周期,而残差看起来像随机噪声。
- Trend图:捕捉到了数据长期、平滑的上升趋势。
- Seasonal图:完美地提取出了那个每年重复的、固定的波动模式。
- Residual图:剩下的残差部分,看起来杂乱无章,非常接近白噪声。
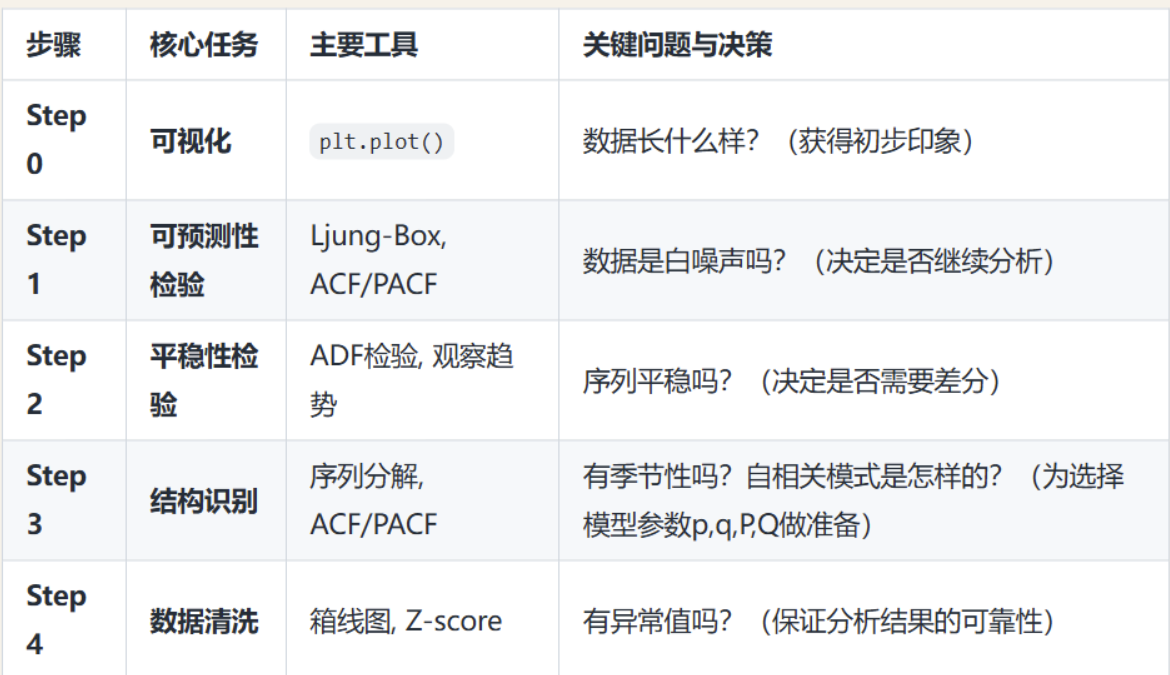
五、时间序列分析流程
遵循这个流程,可以系统化地完成时间序列的探索性数据分析,为后续使用ARIMA、指数平滑等模型进行精准预测打下坚实的基础。

















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









