




- 规范的文件命名
- 规范的文件夹管理
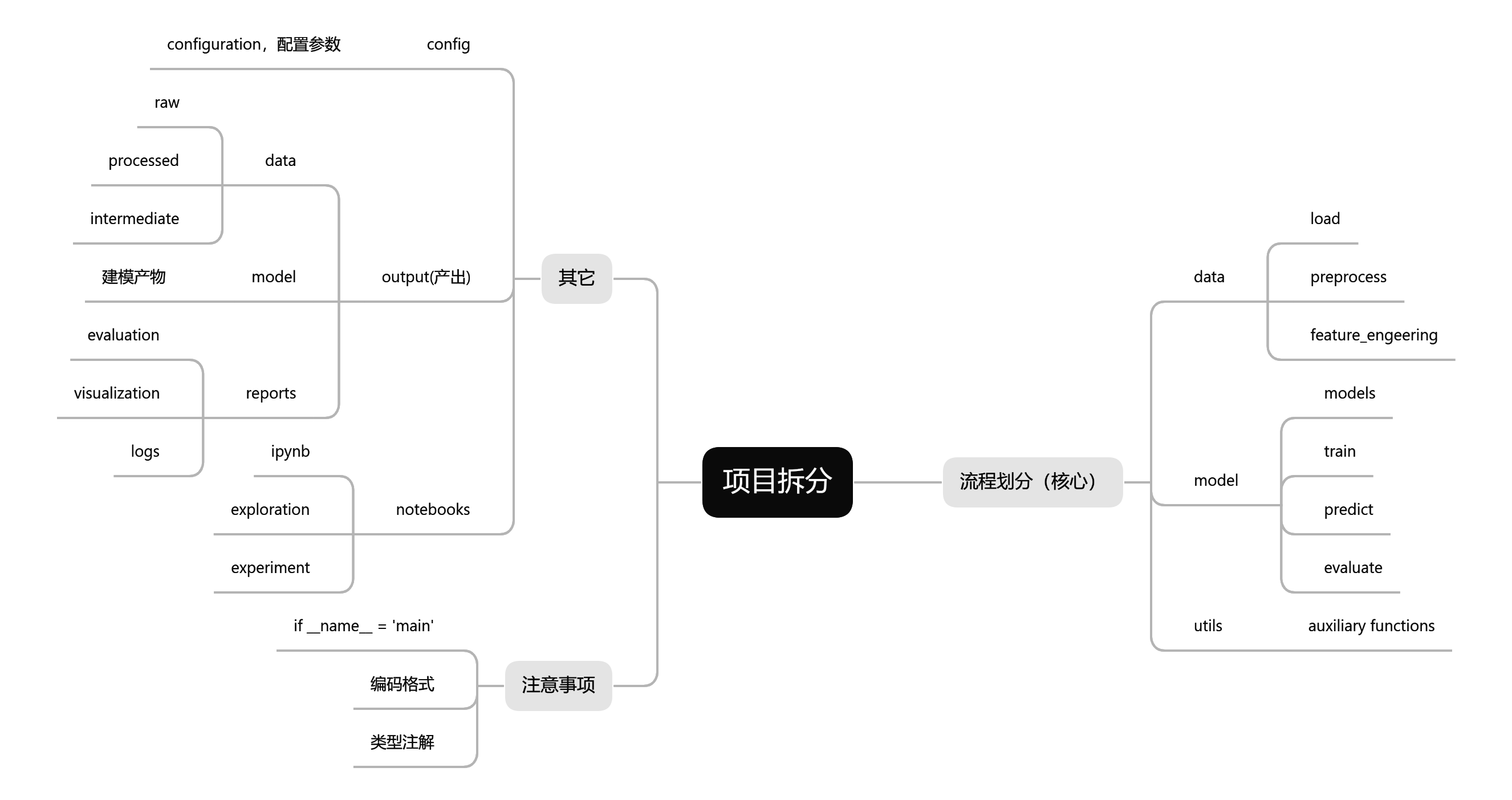
- 机器学习项目的拆分
- 编码格式和类型注解
作业:尝试针对之前的心脏病项目ipynb,将它按照今天的示例项目整理成规范的形式,思考下哪些部分可以未来复用。
在昨天的学习中,知道了自定义库和模块的方法,也清楚了导入库的方法。在之前的学习中,提到pipeline管道将机器学习进行流程化,而今天将顺着这个思路,将一个ipynb文件进行拆分为不同的py文件(实现不同的功能),这样做的好处如下:(1)主文件的代码清晰(2)维护难度降低:修改一个功能时,只需要修改原始代码,从而达到修改多个文件的目的(3)复用:某些功能是通用的。
项目拆分
将一个机器学习项目文件进行拆分时,主要遵循以下步骤:(1)将主要流程拆分到py文件中(数据处理、训练等)(核心)(2)通用的辅助函数放入utils.py中(3)所有配置参数放入config.py中(4)产出物的存放
关于每一步骤(模块)中,写法就是使用类或函数进行封装功能,然后在主文件中使用import导入后调用函数即可。
机器学习的流程:
- 数据加载:获取原始数据(raw)
- 数据探索与可视化:数据特性的初步查看
- 数据预处理:异常值、缺失值处理,离散特征编码,连续特征归一化等
- 特征工程:特征筛选和特征降维,选择、优化现有特征
- 模型训练:建模、调参
- 模型评估:指标评估,得到报告
- 模型预测:预测新数据
从大方向上讲,可以创建四个文件夹,分别是:
- source:存放核心代码,即机器学习主要流程相关。比如数据预处理,模型训练与评估,辅助函数等
- config:存放配置文件,方便管理和切换不同环境(开发、测试、生产)
- output:存放产出物,比如预处理后的数据、评估的报告、可视化的结果等等
- notebook:存放ipynb文件,比如初期可视化探索等
信贷预测项目的划分:
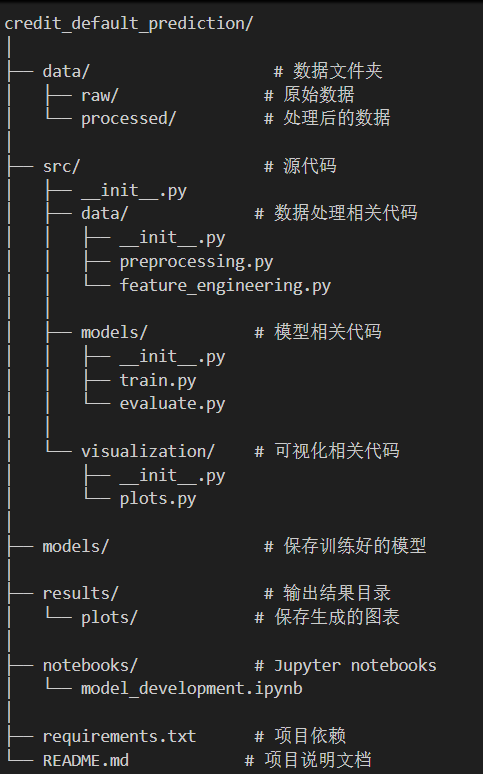
上面的拆分思路和原则,可能还是需要实践才能体会地更加深刻。
注意事项
if __name__ == '__main__'
这行代码的主要作用是判断当前模块属于被导入的,还是直接运行的:
- 当python文件直接运行,__name__的值被设置为‘__main__’
- 当python文件被导入到其它文件,__name__的值被设置为模块的名称(文件名)
# my_module.py
def hello():
print("Hello from my_module!")
print(f"在 my_module 中,__name__ = {__name__}")
if __name__ == '__main__':
print("my_module 被直接运行")
hello()
else:
print("my_module 被导入")
# 直接运行
'''
在 my_module 中,__name__ = __main__
my_module 被直接运行
Hello from my_module!
'''# main.py
import my_module
print("在 main_script 中执行")
my_module.hello()
# 输出结果
'''
在 my_module 中,__name__ = my_module
my_module 被导入
在 main_script 中执行
Hello from my_module!
'''主要用途:(1)在开发时可以直接运行文件进行测试 (2)防止导入时自动执行不必要的代码 (3)既可以被导入使用,也可以作为独立程序运行。
编码格式
前两行给出(一般为首行):#--coding:utf-8--
主要原因是在之前的Python 2 中默认使用的是ASCII编码,所以需要提前声明编码方式。虽然在Python 3 中默认使用的是UTF-8编码,但显式声明编码是良好的编程习惯,可以避免潜在的编码问题,特别是当代码需要在不同环境间共享时。
类型注解
类型注解用于标明变量、函数参数和返回值的预期类型。包括变量类型注解和函数参数返回值注解。
# 变量类型注解,直接使用冒号加类型
name: str = "张三"
age: int = 25
score: float = 95.5
is_student: bool = True
# 函数参数和返回值注解,参数注解通变量,返回值使用'->'
def greet(name: str, age: int) -> str:
return f"你好,{name},今年{age}岁"关于类属性和方法的类型注解,与函数基本类似:
class Rectangle:
width: float = 1.0 # 类属性注解,有默认值时推荐使用
height: float = 1.0 # 有默认值
def __init__(self, width: float = None, height: float = None): #参数注解
if width is not None:
self.width = width
if height is not None:
self.height = height总结
今天的项目拆分步骤,思路如下。如果只是简单的拆分,那么只需要将之前的ipynb文件直接按步骤拆分到一个py文件里,命名一个函数(类),再Import到主文件调用就可以了。通过这个流程加深了对day 30 导入库的认识,也知道了模块化的好处。
但困难地是,如何将这些属于某个数据集的特定代码通过参数调整、条件判断等方式变成一个可以复用到其它数据集的通用模块。

















 82
82

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









