



 本文介绍了AI上色技术的基本原理,通过生成对抗网络(GAN)实现图像上色。文章以《你好李焕英》电影片段和五四运动图像复原为例,展示了技术如何将黑白图像转变为彩色,营造身临其境的感觉。AI上色过程中,生成器和鉴别器相互作用,不断优化图像色彩,直到达到逼真的效果。同时,文章提供了简单的在线AI上色工具和DeOldify开源项目的链接,供读者实践和进一步研究。
本文介绍了AI上色技术的基本原理,通过生成对抗网络(GAN)实现图像上色。文章以《你好李焕英》电影片段和五四运动图像复原为例,展示了技术如何将黑白图像转变为彩色,营造身临其境的感觉。AI上色过程中,生成器和鉴别器相互作用,不断优化图像色彩,直到达到逼真的效果。同时,文章提供了简单的在线AI上色工具和DeOldify开源项目的链接,供读者实践和进一步研究。
↑↑↑关注后"星标"Datawhale
每日干货 & 每月组队学习,不错过
Datawhale干货
作者:桔了个仔,南洋理工大学,Datawhale成员
身临其境的图像复原
之前看《你好李焕英》里,有一个表现手法非常让我印象深刻。就是一开始场景是黑白的,然后慢慢变成彩色的,从黑白到彩色的这个过程,让我有种「进入新的现实」的感觉。
近期有五四运动的图像复原,看到仿佛置身五四运动现场,尽管画面分辨率不高,色彩也不那么完美,但就是能给人一种身临其境的感觉,回到一百年前,与青年们一起救亡图存。
当时的青年尚能挺身而出,忧国忧民,我相信,现代的青年也能奋发图强,肩负起对于这个国家的历史责任,塑造起具有时代光芒的民族精神。
看了下,大家都对技术原理感兴趣啊,那我来用简单的语言讲讲吧。
技术原理
AI上色的原理是什么? 那我们就需要介绍一种深度学习网络架构了,它就是GAN(这里不是粗话)。GAN不是干饭人的干,而是生成对抗网络(英语:Generative Adversarial Network,简称GAN)。当然,太复杂的技术讲解可能会让读者迷惑,于是我找到一张很直白的原理图。

GAN网络分两部分,一个是生成器(Generator),一个是鉴别器(Discriminator)。生成器通过对图像上色,然后交给鉴别器。鉴别器判断这一个图片看起来真不真,如果觉得假,鉴别器会返回「修改意见」,让生成器重新试试,直到鉴别器觉得足够真了。如果你觉得还不好懂,我再打个比方,这就好像美术老师指导学生画画的过程,一开始学生画出来的不够好,老师指出,学生尝试改改,老师再检查,再给意见,直到老师满意。
这就是一张图的上色过程。而视频是一帧帧画面组成的,给视频上色可以理解为通过这个网络架构给视频里的每一帧上色。不过没有这么简单,毕竟视频一秒钟几十帧,一帧帧上色有点慢,而且每一帧之前可能会出现上色效果不一致。所以有的架构会针对细节调整。例如DeOldify采用了NoGAN(一种新型GAN训练模型),用来解决之前DeOldify模型中出现的一些关键问题。例如视频中闪烁的物体:

使用NoGAN前,画面闪烁严重
 使用NoGAN后闪烁减少
使用NoGAN后闪烁减少
当然,实际还原的色彩其实和原本的色彩是不一样的,仅仅是能让其看起来自然。我做了个实验(AI上色工具稍后介绍到),能看到上色效果和原来的效果并不一样。我下载了这么一张向日葵的照片

我手动转成黑白的

这时候再让AI上色,咦,向日葵变成雏菊了。不过看起来竟然也有另一番美感。

一般来说,给人上色会更接近实际情况些。因为人的肤色比较有限,判别器里已经学习过人脸的颜色可能是哪些,转换成灰度图像后对应什么颜色值,所以AI不太可能会给黑白的人像涂成绿色脸。
动手实现
如果你是技术小白,你可以直接打开这个网址,你只需要上传一张图片就能自动上色。Image Colorizationdeepai.org 例如效果如下:
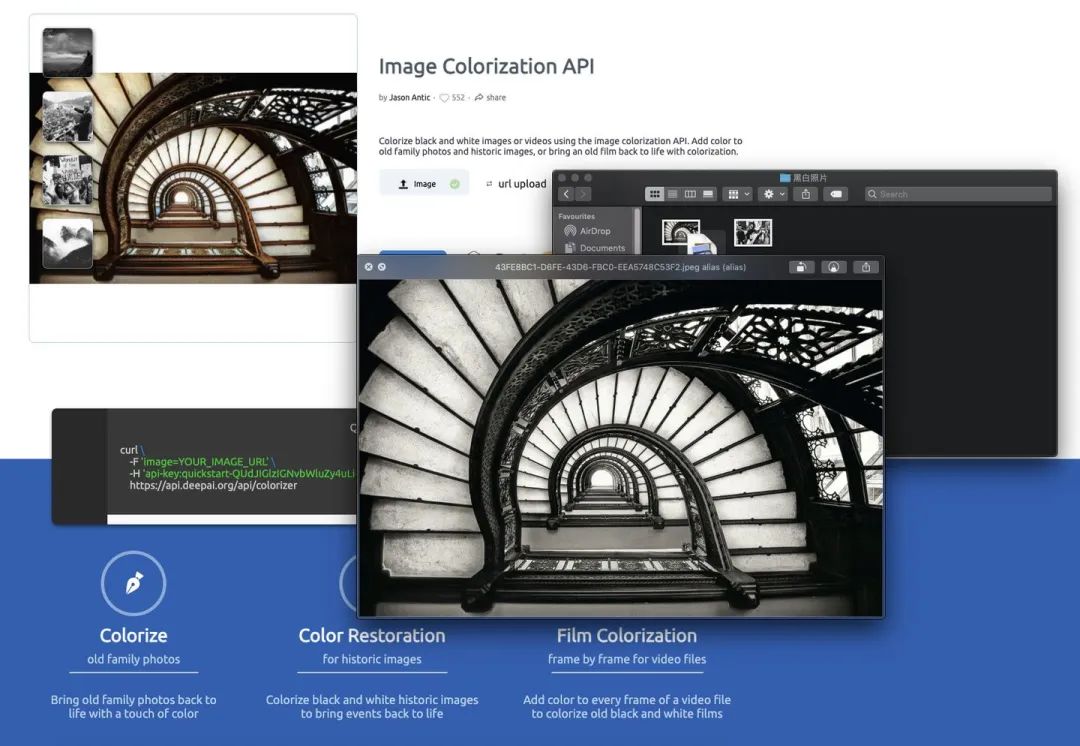
看起来效果很棒吧。如果你懂点技术但不懂机器学习,可以用DeepAI提供的API。例如python调用方法如下:
import requests
r = requests.post(
"https://api.deepai.org/api/colorizer",
data={
'image': 'YOUR_IMAGE_URL',
},
headers={'api-key': 'quickstart-QUdJIGlzIGNvbWluZy4uLi4K'}
)
print(r.json())
# Example posting a local image file:
import requests
r = requests.post(
"https://api.deepai.org/api/colorizer",
files={
'image': open('/path/to/your/file.jpg', 'rb'),
},
headers={'api-key': 'quickstart-QUdJIGlzIGNvbWluZy4uLi4K'}
)
print(r.json())
如果想继续深入研究,可以fork DeOldify的repo。附开源地址:
https://github.com/jantic/DeOldifygithub.com

整理不易,点赞三连↓

















 371
371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









