



Datawhale干货
作者:平凡,英国Northumbria University讲师,
计算机博士
这两天在AI大模型这个日新月异的圈子里面发生了几件事,都挺有纪念意义的。
第一件是DeepSeek-V3.2的发布,将开源模型的智能极限又往前推进了一步,特别是同时发布的一个speciale特别定制版,更是在多个专门测试推理(Reasoning)和智能体(Agentic)的benchmark上达到了全新的高度,跟目前顶级的闭源模型,Gemini-3.0-Pro以及GPT-5-High等模型齐平,甚至还有所超越。
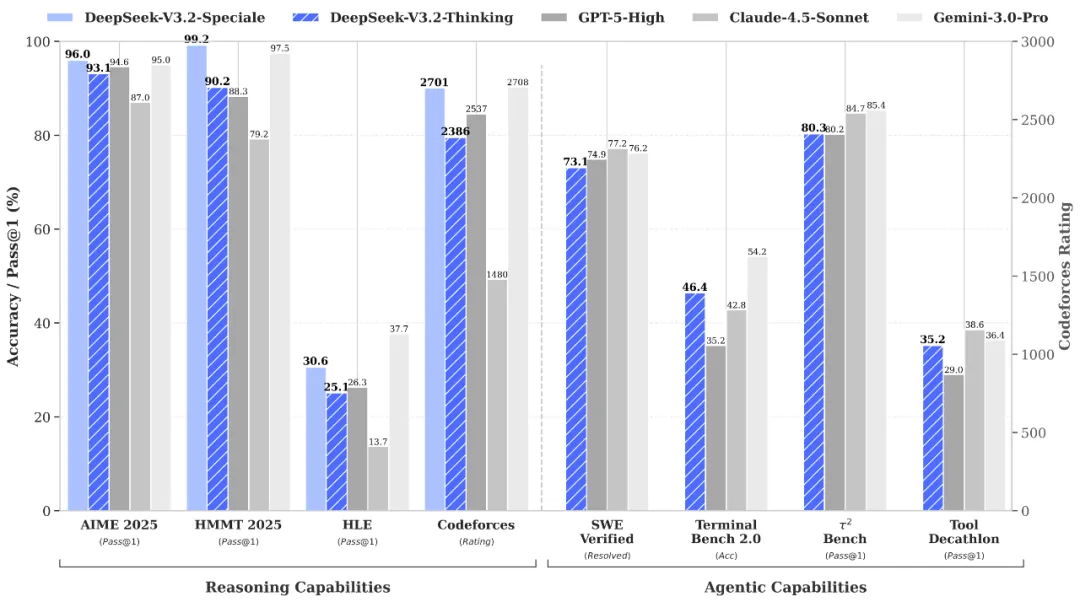
来源:https://huggingface.co/deepseek-ai/DeepSeek-V3.2/resolve/main/assets/paper.pdf
除了注意力机制的进一步创新、新的数据合成技术之外,这次最受行业关注的亮点之一,是 DeepSeek 官方反复强调的能力:
“Thinking in Tool-Use”(思考融入工具调用)
可以看到,在这个benchmark上,用上这个机制的模型还不算多,但头部模型的融合率已经开始显现,包括 MiniMax M2 等一批具备较强 Agent 能力的模型,都在不同程度上支持类似的交错推理结构。
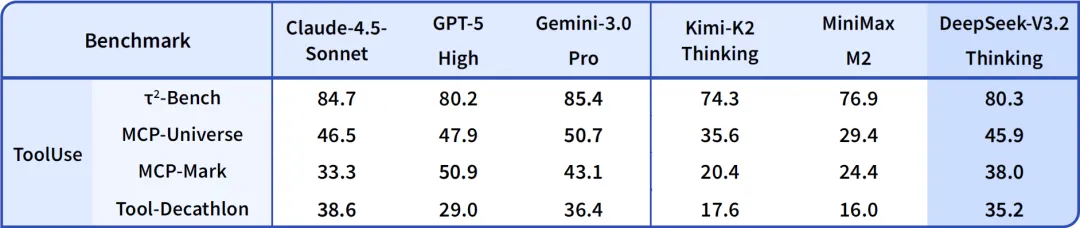
来源:https://api-docs.deepseek.com/news/news251201
事实上,“Thinking in Tool-Use” 并不是一个新的概念,而是一个更标准、更通用的技术术语的工程化体现—它的本质叫 Interleaved Thinking(交错思维链)。这个术语在业内已经逐渐被采用,包括 MiniMax 在其 M2 技术博客中也使用了同样的叫法,并进一步把它定义成 Agent 推理的核心范式。
Interleave这个词意思其实很简单,根据剑桥词典的解释,就是在一部分内容里“嵌入”一些内容。

但仅从字面理解并不够直观,要真正感受到它的意义,我们必须把视角拉回到这两天发生的第二件具有象征意义的事件——ChatGPT 三岁生日。
三年前,初代 ChatGPT 的面世,让 NLP 这个曾经细分成几十种任务的小王国被瞬间“大一统”——分类、摘要、对话、翻译通通被一个统一的架构吞并。那确实是一个时代,但今天回头看,当时的大模型其实还非常稚嫩。
对普通用户来说,他们早已习惯了与 AI 的经典两步式互动模式:
提问题 → 等结果。
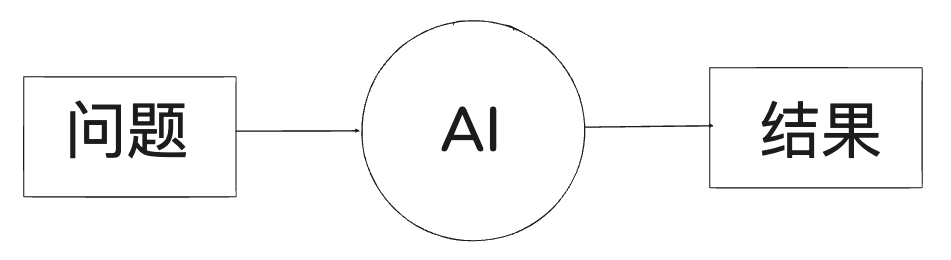
这个表层交互模式直到今天似乎都没什么变化,但在背后,大模型自身已经经历了非常快速的几轮演化。 如果用一种略带“工程视角”的方式来概括,我们大致可以把这三年的发展看作是从最初的 No-Thinking → Thinking → Tool-Use Agent → Interleaved Thinking Agent 四个阶段的演进。
在这条演进轨迹中,不同模型扮演了不同角色——
ChatGPT 的诞生,几乎可以视作第一阶段的起点,也把“大模型对话”推向了大众;
随后的一系列模型(包括 Claude 在内)在思维链、长推理上的表现,进一步强化了“Thinking 模型”的范式;
DeepSeek V3.2 又用 “Thinking in Tool-Use” 把“思考与工具调用一体化”推到了台前;
而包括 MiniMax 在内的多家团队,则在过去几个月持续把 Interleaved Thinking 往前推了一步——从模型能力,扩展到调用方式、生态适配和开源实践,让它逐渐从“论文里的概念”变成“工程里真正可用的能力”。
第一代:No-Thinking ——没有思考的模型
我们还用做饭这件事来解释,最初的大模型不会“想”,就跟新手厨师一样,就是死记硬背菜谱,表现上更像一个超强版的自动补全:你问它一个问题,它不假思索地直接给答案。
优点是快,但问题也很明显:
对长对话没有记忆
遇到复杂任务容易“张口就来”
数学、逻辑问题经常胡编
这种“无思考的模型”,性能很快就到达了天花板。

第二代:Thinking —— 模型学会规划,但仍是“一次性想完”
后来,模型学会了“先思考,再回答”。这一步非常重要,让大模型的质量跃升一个台阶。它不再单纯的背菜谱,而是开始先思考再回答了。
但它的问题也同样明显:
模型会在内部一次性把整套推理链“憋完”,然后一口气输出结果。
这就像是:
厨师在开火之前,先在脑子里把整道菜从头到尾“模拟做一遍”,然后严格按这个脑内菜谱执行。
厨师也不是超人,他不可能把现实世界的所有情况都考虑到。
特别是现实世界不是静态的—
如果食材状态不同怎么办?
如果灶的温度不够怎么办?
如果步骤中途需要修正怎么办?
Thinking-only 模式在真实的、多变的任务里仍然力不从心。

第三代:Agent —— 有工具,但不会“边用边想”
Agent时代,大模型终于不再是单纯用脑子来模拟一切了,而是真正意义上的掌握了工具的用法,也就是Tool-Use。
它可以写代码、调用 API、查资料、执行搜索,标志性的应用就是深度研究(Deep Research)功能。
大模型会针对于某个具体的问题,在互联网上搜索,用代码工具来模拟,最后调用各种文档编辑方法,生成一份精美的文档或者PPT。
这让模型的能力进一步解锁,但问题依然在:
它的推理仍然是单块式的:先憋一大段思考,再一次性调用工具。
它配备了工具,却缺乏“边用工具边推理、边推理边修正”的能力。
他现在有了各种刀具、温度计、油温探头,看上去武装到了牙齿,但做菜时依然习惯于——先在脑子里把全流程想完,再机械地照着执行,而不是在烹饪过程中不断尝味道、看火候、边做边调整。
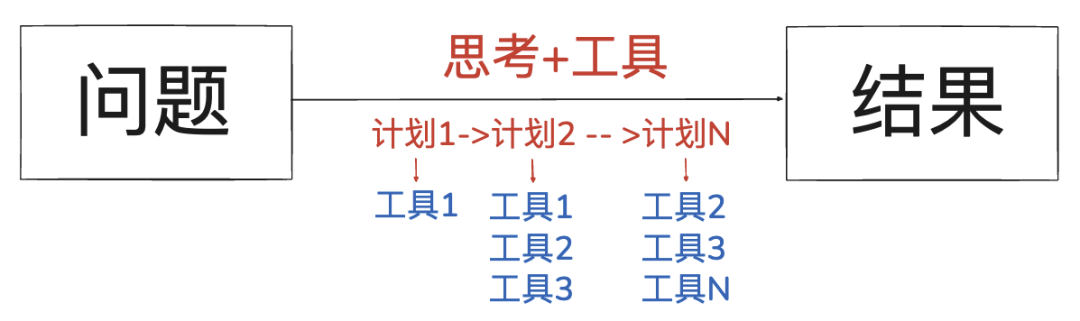
第四代:Interleaved Thinking —— 真正意义上的 AI“像人一样做事”
从第一代到第三代,解决问题的能力可以说是在跃升,从不断被刷新的benchmark分数可见一斑。

但问题依旧存在,那就是“计划是死的,而现实不仅是活的,而且非常多变”,因为真正的智能需要在思考和行动之间建立一个动态的、实时的反馈循环。
Interleaved Thinking 的提出,恰恰补上了这个缺失许久的核心能力。
这也是顶级厨师具备的素质,他们可以在烹饪中不断的品尝、调整火候、根据食材的反应及时修正自己的下一步动作。

放在AI领域里面,我们可以用 MiniMax 的这张图,我们可以看得更清楚:
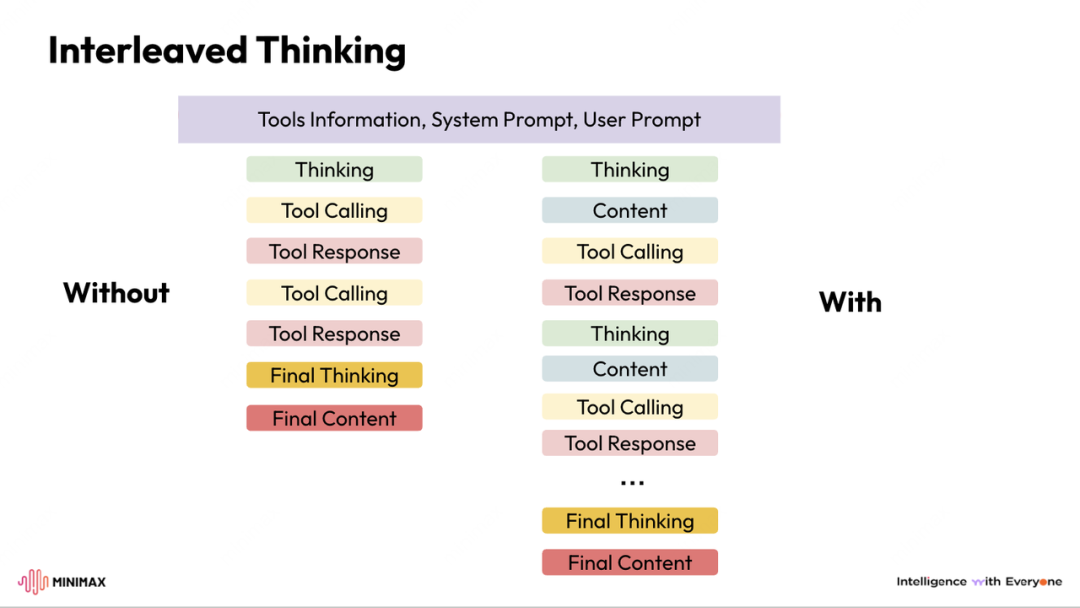
左侧的 “Without Interleaved Thinking” 模式看起来有工具调用,但本质上依旧是“先想完后做完”。工具调用只是附属,不会影响下一轮推理。
右侧的 “With Interleaved Thinking” 模式则完全不同:
模型思考中嵌入工具使用
工具返回结果嵌入下一轮思考
推理链保持连续
状态不会丢失
整个任务形成一个动态闭环
这就像人类解决问题时的方式:
边分析、边尝试、边修正。
它让模型第一次具备了真正“过程式”的智能:
想一小步 → 执行一小步 → 根据执行结果继续想 → 再继续执行 → 反复迭代直到任务完成。
它不是更快,也不是更大,而是思维结构本身的升级。
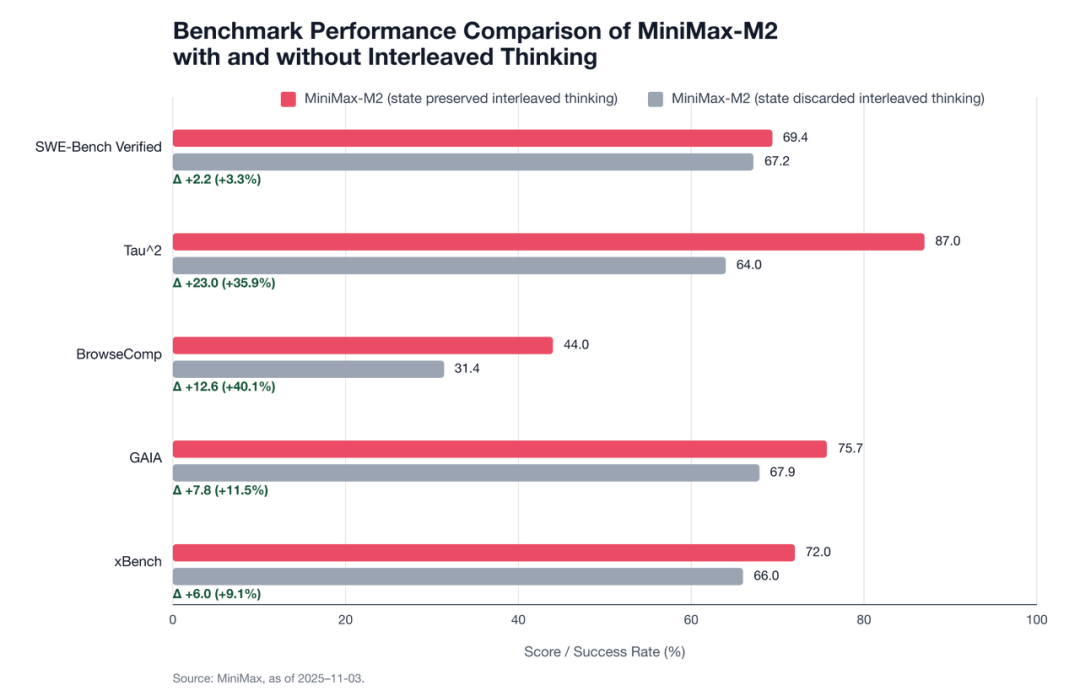
它带来的结果也是非常显著的,使用了这套思维结构的开源模型,与闭源模型的差距不断的缩小。
MiniMax-M2这个模型做的实验结果就能看到,在 “保留推理链” vs “丢弃推理链” 的对比测试中,在多个 Agent 基准任务上都有非常显著的提升:
SWE-Bench Verified:+3.3%
Tau²:+35.9%
BrowseComp:+40.1%
GAIA:+11.5%
xBench:+9.1%
如果只看数字,可能会觉得有些提升“也就几个点”。
但当你把视角切换到完整榜单,就会发现这几个点在实际竞争中的含金量非常高——以 SWE-Bench Verified 为例,个位数的提升就足以让一个模型在排行榜上上升好几位。
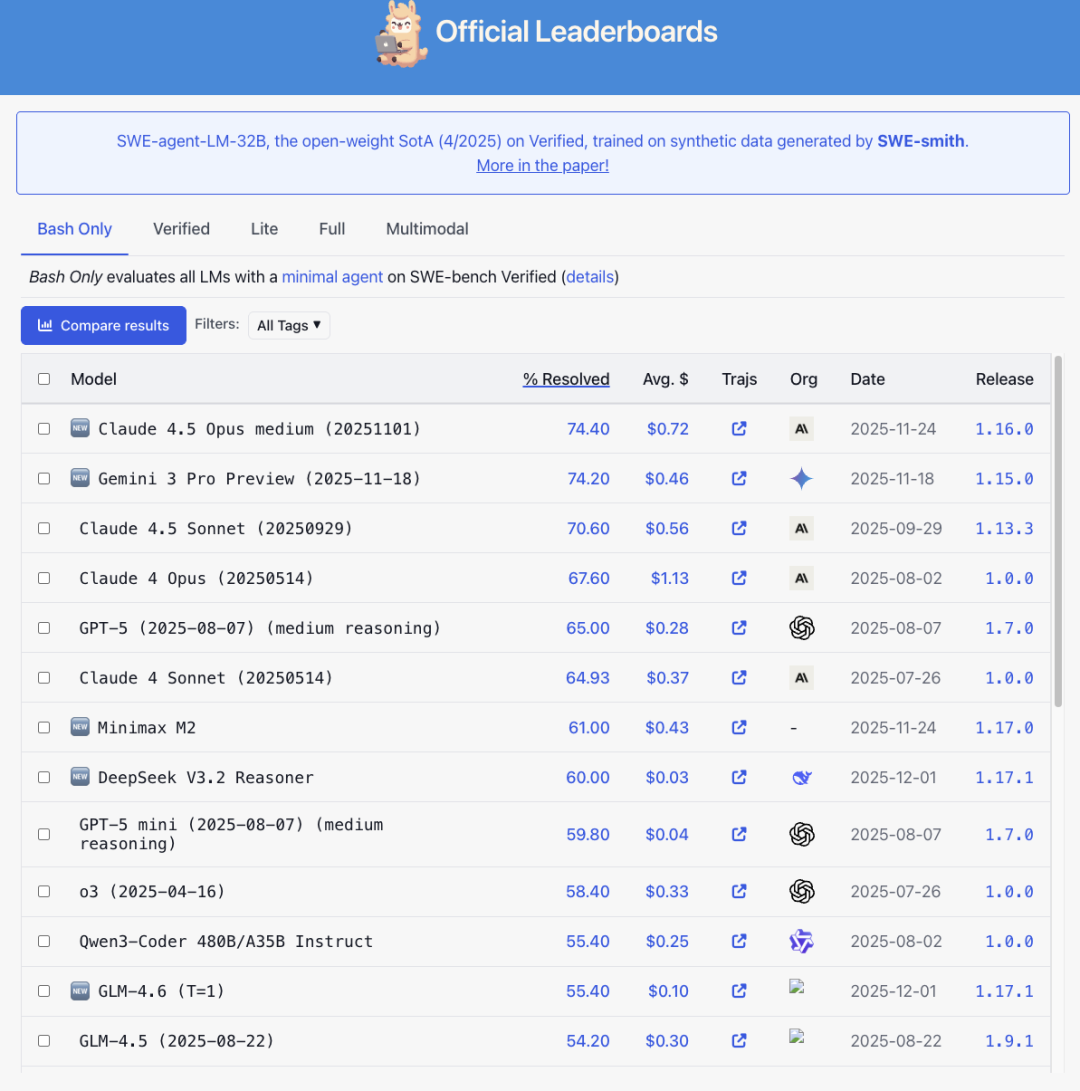
来源:https://www.swebench.com/
更重要的是,对于 Agent 场景而言,这些差异往往意味着:
是“勉强能用”,还是“可以放心交给它跑一整晚”;
是“要人盯着纠错”,还是“真正具备自主完成任务的能力”。
但实际上,Interleaved Thinking 能够从“非共识的小众机制”,发展到今天成为越来越多头部模型的共同选择。
就在DS-V3.2发布后,reddit上的这个帖子就说了,开源大模型领域,用了这个技术的模型并不多,OpenAI的GPT-oss,MiniMax M2,Kimi-K2。
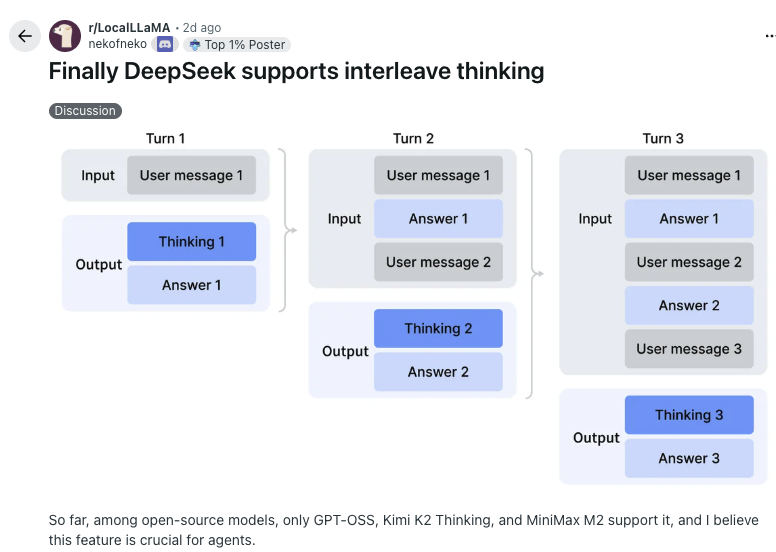
这反映了整个行业的技术演进,但如果放大到整个生态层面,你会发现一个往往被忽略的事实:
它之所以能“真正落地”,不是因为某一家模型实现了,而是因为整个生态——编程工具、API 平台、Host 平台、推理框架——开始陆续支持它了。
而在这场变革中,MiniMax 是最早、也是投入最多的推动者之一。
在 MiniMax-M2 发布之前,整个社区对 Interleaved Thinking 的支持非常少:
大多数编程助手只支持传统的 “ASK → ANSWER” 模式
很多 API 平台不会识别复杂的 reasoning block
一些本地 LLM 运行平台(如 Ollama)会在中间步骤把推理链直接丢弃
工具调用格式不统一、字段缺失、上下文无法回传
这意味着:
哪怕模型本身支持 Interleaving,只要生态不跟上,它的能力就发挥不出来。
推动 RooCode、Cline、OpenRouter、Ollama 等主流工具全面支持,这是一件非常耗费心力的事情,因为家家有问题,且问题各不相同。比如,
有的在工具调用后丢弃思维链
有的把 reasoning_details 当成“无用内容”过滤
有的把多段推理合并成同一 block 导致状态混乱
因此,从 M2 发布到现在,MiniMax 在生态兼容性上推进了多项关键工程工作。这些本该是开源社区共同完成的基础任务,但由于涉及底层接口和执行语义,推进往往不够快。MiniMax 主动补齐了这些关键环节,使 Interleaving 能力能够在实际环境中闭环运行。
包括:
向 Kilo Code 提交核心 PR,使其完整支持交错式推理;
推动 Cline 的执行流适配;
与 Ollama、OpenRouter 协调接口与输出格式,确保能够处理交错式的思考–行动循环。
这些都是不显眼但必要的基础工作,使 Interleaved Thinking 从“模型能力”变成“可用能力”。

来源:X
当然,完成了适配之后的模型性能提升很明显,从越来越多的app支持这个模式也能反映这一点儿。
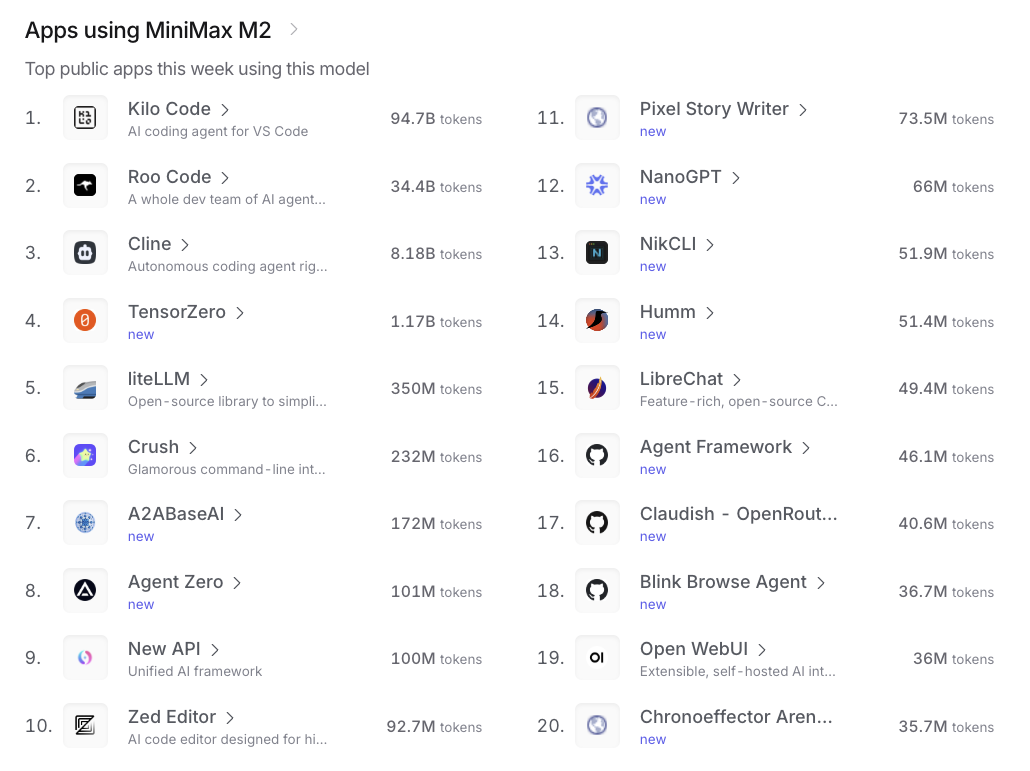
来源:OpenRouter
在刚刚结束的AWS Invent 2025大会上,MiniMax-M2这个模型被Amazon的Bedrock正式收录,这也是为数不多被收录的国产模型。

另一个点更有价值,那就是直接开源了支持Interleaved Thinking 的 Coding CLI。
它本质上提供:
完整的多轮推理状态管理逻辑
工具调用+思维链的正确传递方式
与 M2 模型完全对齐的结构
极低成本即可复用的 Agent 框架
地址:https://github.com/MiniMax-AI/Mini-Agent
这个开源框架可以做很多事情,比如完成一件需要多步操作的任务。
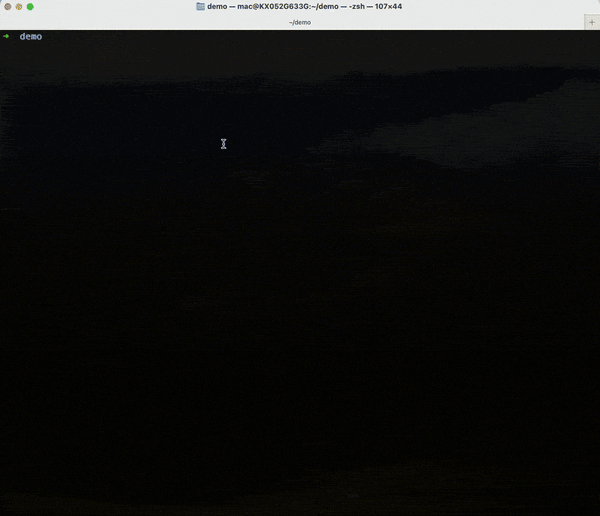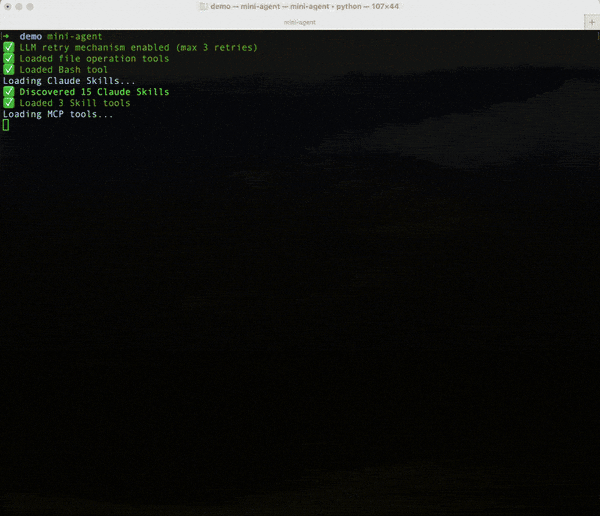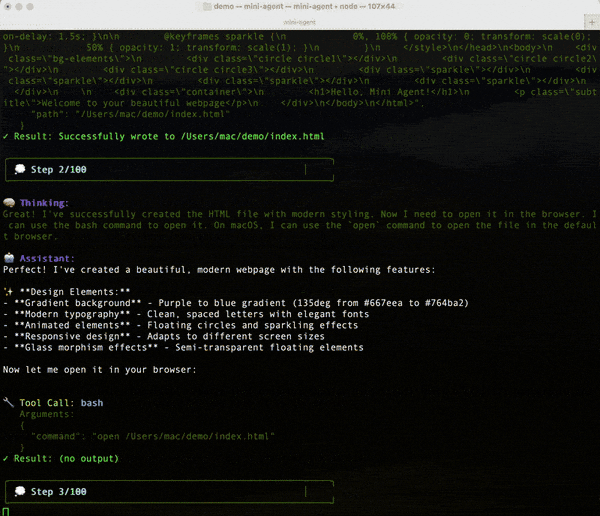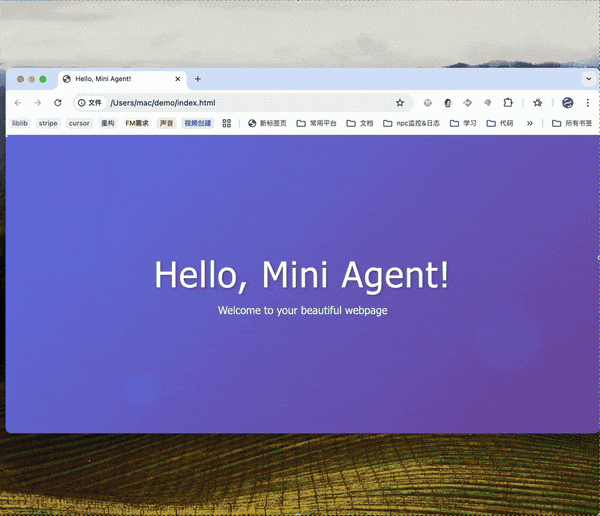
使用Claude Skill。

上线后快速获得 700+ Star(持续增长),并被多个社区项目引用。
它的意义在于:开发者不用再猜“怎么才是正确的调用方式”,而是有一个可跑通的、工程级的标准实现可直接照搬。
这样可以极大程度把这个技术普及开来,特别是在MiniMax-M2的官方技术报告中强调了这个概念之后,Kimi、DeepSeek、Anthropic、GPT-OSS 都在几个月内相继提出了类似概念,并放在非常核心的位置。
这不是巧合,而是技术演进的客观规律:
当大模型从“写答案”进化到“做任务”,Interleaved Thinking 就成为唯一合理的思维结构。
MiniMax 在多个场合(AIE 大会、官方 X、研发 Leader 的深度文章)持续输出这一概念,也让整个行业的讨论逐渐走向统一术语:
Interleaved Thinking = Agent 多轮推理的底层范式。
智能也可以被重构
三年前,ChatGPT 让人类第一次看到“语言可以被统一”。
三年后,Interleaved Thinking 让我们看到“智能也可以被重构”。
当越来越多的模型开始真正做到“边思考、边行动”,大模型的角色也在发生变化:它不再是一个回答机器,而是一个能独立工作、能执行任务、能在复杂环境中持续迭代的智能体。
而 MiniMax等一众大模型在这一波演进中扮演的角色,是让这件事情不只存在于白皮书和演示,而是成为整个生态都能用、都能跑通的现实能力。
未来的智能时代,或许就是从这条交错思维链开始被重新点亮的。

一起“点赞”三连↓

















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









