




🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:CameraCtrl II: Dynamic Scene Exploration via Camera-controlled Video Diffusion Models
论文链接:https://arxiv.org/pdf/2503.10592
开源代码:https://hehao13.github.io/Projects-CameraCtrl-II/

导读
近年来,视频扩散模型取得了显著进展,它可以根据文本描述生成高保真且时间连贯的视频。这些模型接受用户定义的控制,并且在数据集大小和计算资源方面具有可扩展性,能够生成较长且符合物理规律的视频。例如,Sora可以生成具有真实物理效果和复杂运动的一分钟长视频。因此,这些视频扩散模型已成为建模和模拟现实世界动态场景的有前景的工具。
简介
本文介绍了相机控制二代(CAMERACTRL II),这是一个通过相机控制的视频扩散模型实现大规模动态场景探索的框架。先前基于相机条件的视频生成模型在生成相机大幅移动的视频时,存在视频动态性减弱和视角范围有限的问题。我们采用一种逐步扩展动态场景生成的方法——首先增强单个视频片段内的动态内容,然后将这种能力扩展到跨广泛视角范围的无缝探索。具体而言,我们构建了一个具有大量动态且带有相机参数注释的数据集用于训练,同时设计了一个轻量级的相机注入模块和训练方案以保留预训练模型的动态性。基于这些改进的单片段技术,我们允许用户迭代指定相机轨迹以生成连贯的视频序列,从而实现扩展的场景探索。跨多种场景的实验表明,相机控制二代(CAMERACTRL II)在相机控制的动态场景合成方面,比先前方法具有更广泛的空间探索范围。
方法与模型
我们提出了相机控制二代(CAMERACTRL II),以使用视频扩散模型实现相机控制的大规模动态场景生成。为了生成具有高度动态性的此类视频,我们精心策划了一个新的数据集(第 3.2 节),并开发了一种有效的相机控制注入机制(第 3.3 节)。第 3.4 节介绍了我们通过视频扩展技术在动态场景中实现大范围探索的方法。第 3.1 节提供了相机控制的视频扩散模型的必要预备知识。
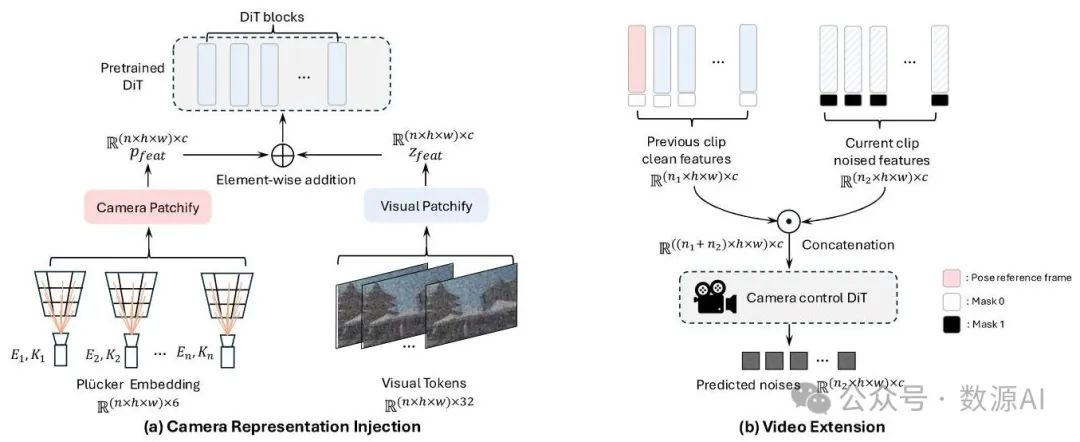
图3. CAMERACTRL II的模型架构。(a) 给定一个预训练的视频扩散模型,CAMERACTRL II在模型初始阶段添加了一个额外的相机分块层。它以普吕克嵌入作为输入,输出与视觉特征形状相同的相机特征。在第一个DiT层之前,将这两种特征逐元素相加。(b) 保留前一个视频片段的特征不变,同时对当前特征添加噪声。拼接后,将特征输入到一个相机控制DiT;我们只计算当前片段的标记的损失。在两个图中我们都省略了文本编码器,在第二个图中省略了相机特征。
1. 预备知识
给定一个预训练的潜在视频扩散模型和相机表示 ,一个相机控制的视频扩散模型学习对视频令牌的条件分布 进行建模,其中 表示来自视觉分词器 [60] 的编码潜在变量, 表示文本/图像提示。训练过程包括在每个时间步 向潜在变量添加噪声 以获得 ,并使用以下目标优化一个变压器模型来预测该噪声:
在推理时,我们从高斯噪声 开始初始化,并使用欧拉采样器迭代恢复视频潜在变量 ,同时以输入图像和相机参数为条件。
对于相机表示,我们遵循最近的工作 [21, 5
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1472
1472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









