




FROM
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
我的环境
- 语言环境:Python 3.10.12
- 开发工具:Jupyter Lab
- 深度学习环境:
- torch==2.3.1+cu121
- torchvision==0.18.1+cu121
一、本周内容
1. ResNet与DenseNet的基本原理
- ResNet (Residual Network)
- 核心思想: 引入残差连接,允许网络通过学习输入和输出之间的残差来简化训练过程。对于一个残差块,其输出可以表示为 F(x)+x,其中 F(x) 是网络层的输出,x 是输入。
- 优点: 能够训练非常深的网络,解决了深层网络的梯度消失问题。
- DenseNet (Densely Connected Convolutional Networks)
- 核心思想: 每个层都与前面所有层相连,即每个层的输入是前面所有层的输出的拼接。这种结构使得特征在不同层之间得到充分的重用。
- 优点: 提高了特征的重用率,减少了参数数量,提高了网络的参数效率。
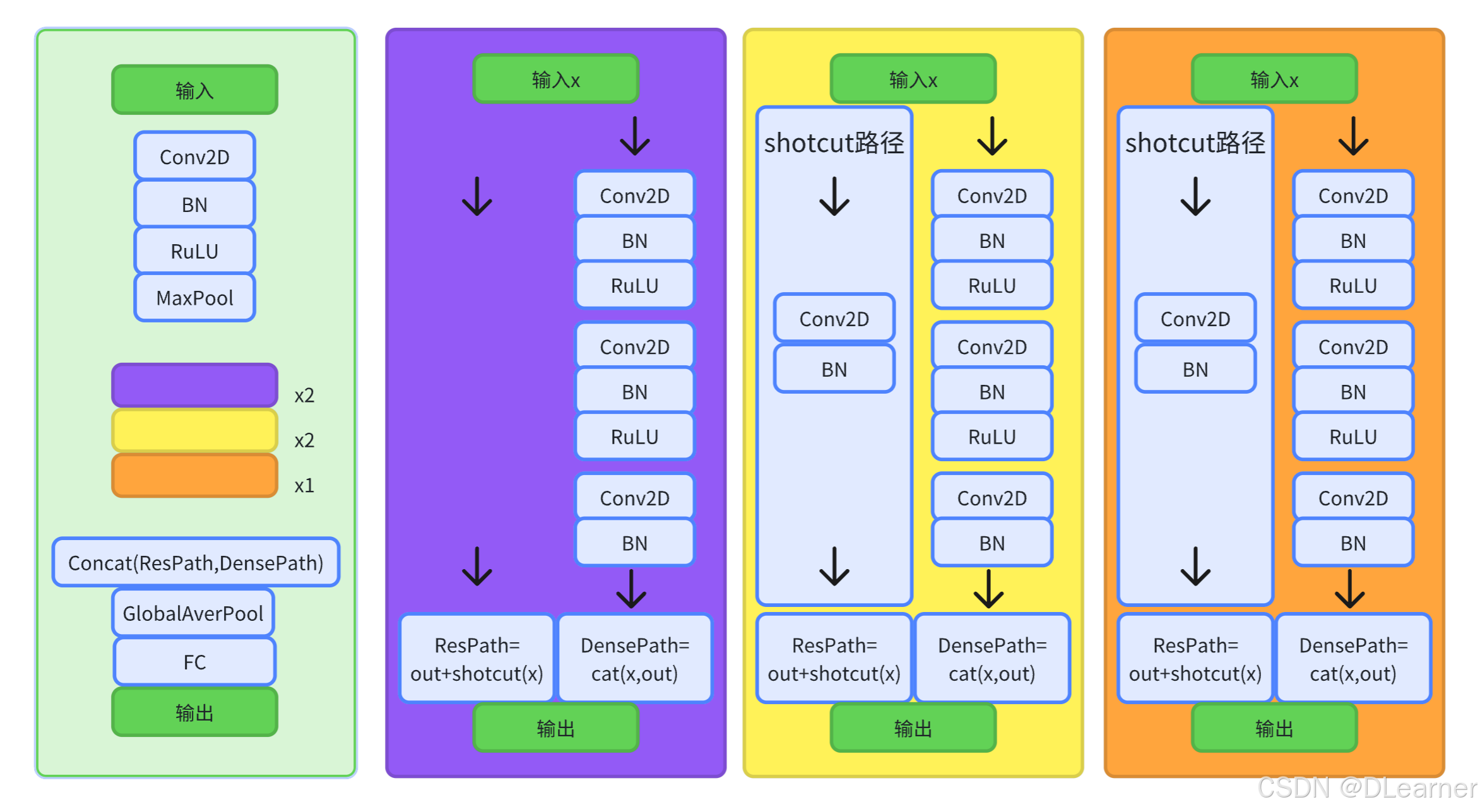
2. ResNet与DenseNet结合模块图
该模型结合了 ResNet 和 DenseNet 的特点,通过两条路径(ResNet 路径和 DenseNet 路径)来处理特征,并在最后合并这两条路径的输出进行分类。
主要模块说明:
2.1 DualPathBlock 类
- 功能:定义了一个双路径网络的基本构建块。
- 关键组件:
- 共享卷积层:包括三个卷积层 (conv1, conv2, conv3) 和对应的批量归一化层 (bn1, bn2, bn3)。
- shortcut 连接:用于 ResNet 路径中的残差连接,当步长不为 1 或输入通道数与输出通道数不匹配时使用。
- 前向传播:分别计算 ResNet 路径和 DenseNet 路径的输出,并返回两个路径的结果。
2.2 DPN 类
- 功能:定义了完整的 DPN 模型结构。
- 关键组件:
- 初始卷积层:conv1 和 bn1,用于将输入图像转换为初始特征图。
- 最大池化层:maxpool,用于缩小特征图尺寸。
- 网络层构建:通过 _make_layer 方法构建多个 DualPathBlock 层,形成网络的主干部分。
- 全局平均池化层:avgpool,用于将特征图转换为固定大小的特征向量。
- 全连接层:fc,用于最终的分类输出。
- 权重初始化:通过 _initialize_weights 方法对所有卷积层和批量归一化层进行初始化。

二、核心代码及运行截图
dpn.py:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DualPathBlock(nn.Module):
def __init__(self, in_channels, channels, stride=1):
super(DualPathBlock, self).__init__()
self.channels = channels
# 共享卷积层
self.conv1 = nn.Conv2d(in_channels, channels, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(channels)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(channels)
self.conv3 = nn.Conv2d(channels, channels * 2, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(channels * 2)
# ResNet路径的shortcut连接
self.shortcut = None
if stride != 1 or in_channels != channels * 2:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, channels * 2, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channels * 2)
)
def forward(self, x):
residual = x
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
if self.shortcut is not None:
residual = self.shortcut(x)
# ResNet路径
res_path = out + residual
# DenseNet路径
dense_path = torch.cat([x, out], 1) if x.size(1) == self.channels * 2 else out
return F.relu(res_path), dense_path
class DPN(nn.Module):
def __init__(self, num_classes=200):
super(DPN, self).__init__()
self.in_channels = 32
# 使用更小的初始卷积层
self.conv1 = nn.Conv2d(3, self.in_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channels)
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
# 构建网络层,使用更少的通道数
self.layer1 = self._make_layer(32, 2, stride=1)
self.layer2 = self._make_layer(64, 2, stride=2)
self.layer3 = self._make_layer(128, 1, stride=2)
# 计算最终特征维度
self.feature_channels = 512 # 修正为实际的特征维度
# 全局平均池化和分类器
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(self.feature_channels, num_classes)
# 初始化权重
self._initialize_weights()
def _make_layer(self, channels, blocks, stride):
layers = []
layers.append(DualPathBlock(self.in_channels, channels, stride))
self.in_channels = channels * 2
for _ in range(1, blocks):
layers.append(DualPathBlock(self.in_channels, channels))
return nn.ModuleList(layers)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.maxpool(x)
# 初始化ResNet和DenseNet路径
res_path = x
dense_path = x
# 通过所有层
for i, layer in enumerate([self.layer1, self.layer2, self.layer3]):
for j, block in enumerate(layer):
res_path, dense_path = block(res_path)
# 合并两条路径的特征
combined = torch.cat([res_path, dense_path], 1)
out = self.avgpool(combined)
out = torch.flatten(out, 1)
out = self.fc(out)
return out
输出:


绘制训练历史
输出:



















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









