




目录
FROM
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
我的环境
- 语言环境:Python 3.11.9
- 开发工具:Jupyter Lab
- 深度学习环境:
- torch==2.3.1+cu121
- torchvision==0.18.1+cu121
一、本周内容及个人收获
1. 本周内容
本周学习内容包括:
- CNN 算法发展
- 残差网络的由来
- ResNet-50 介绍
- 手动构建 ResNet-50 网络模型
2. 个人收获
2.1 ResNet
ResNet(残差网络)是一种深度学习架构,由微软研究院的Kaiming He等人在2015年提出,主要解决深度神经网络训练中的退化问题。ResNet的核心思想是引入“残差学习”,即网络的每个层学习的是输入与输出之间的残差(差异),而不是直接学习输出。这种设计使得网络能够通过简单地堆叠更多的层来增加深度,而不会降低训练性能,反而能够提高性能。
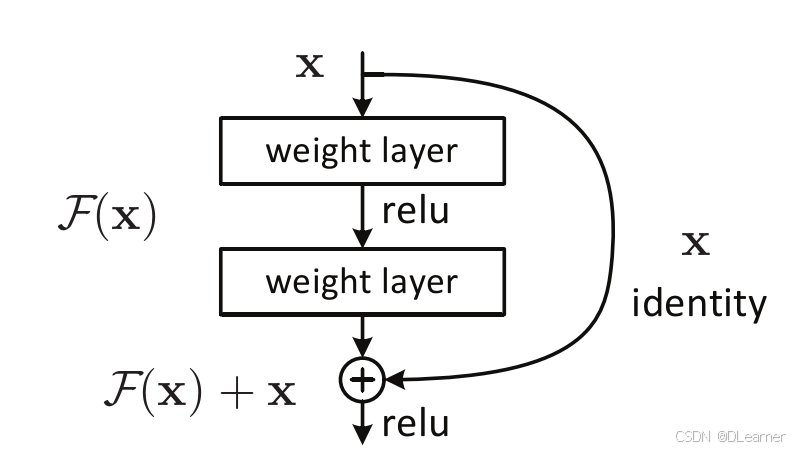
1. 残差块(Residual Block)
ResNet的基本构建单元是残差块,如下图所示,每个残差块包含输入和输出之间的一条捷径(shortcut connection)或恒等连接(identity shortcut)。这种结构允许梯度在网络中直接传播,从而缓解梯度消失问题。
2. 恒等映射(Identity Mapping)
在残差块中,如果输入和输出的维度相同,输入可以直接通过捷径连接添加到输出上,即 F(x)+x 这种结构使得网络即使在增加深度时也能保持性能不会下降,解决了退化问题。
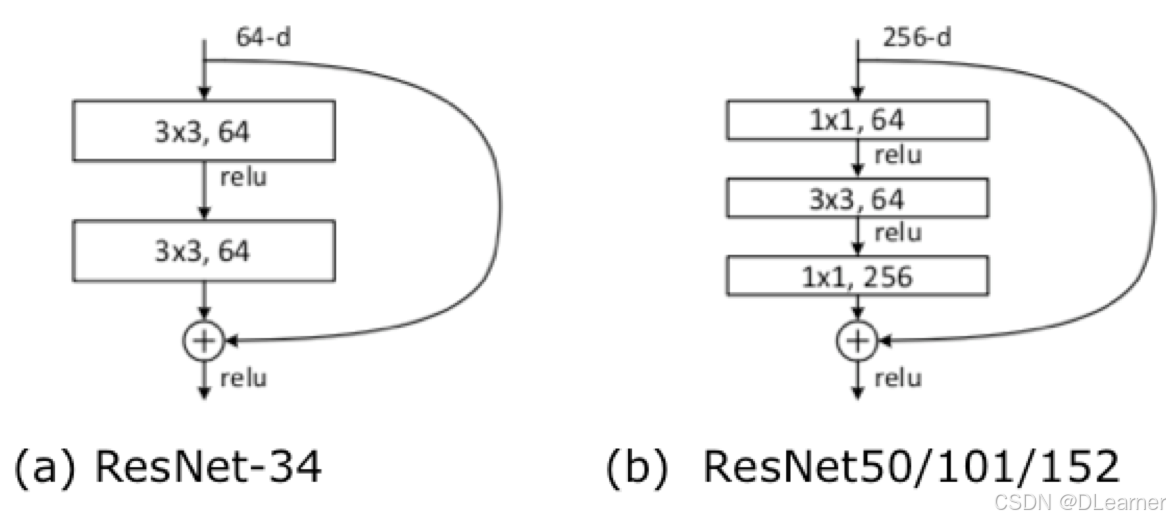
3. 维度匹配(Dimension Matching)
当输入和输出的维度不匹配时,通过1x1的卷积进行降维或升维,以确保输入和输出可以通过捷径连接相加,如下图(b)。
4. Identity Block 恒等块
Identity Block是ResNet中的一种基本构建块,其特点是输入和输出具有相同的维度。这种块的设计允许网络在增加深度时不会降低性能,因为它提供了一个直接的路径(shortcut connection),使得输入可以直接传递到输出,从而避免了梯度消失的问题。
Input ──────────────────────────────────┐
│ │
↓ │
1x1 Conv (filters1) │
│ │
↓ │
BatchNorm + ReLU │
│ │
↓ │
3x3 Conv (filters2) │
│ │
↓ │
BatchNorm + ReLU │
│ │
↓ │
1x1 Conv (filters3) │
│ │
↓ │
BatchNorm │
│ │
↓ ↓
└─────────────── + ──────────────────┘
│
↓
ReLU
Identity Block的结构通常包括:
- 1x1卷积层:用于降低或增加通道数,通常用于降维。
- 3x3卷积层:用于提取特征,保持通道数不变。
- 1x1卷积层:再次用于调整通道数,使其与输入匹配。
- Batch Normalization(批量归一化):在每个卷积层后应用,以加速训练过程并提高性能。
- Activation(激活函数):通常是ReLU,引入非线性。
如果输入和输出的维度相同,Identity Block的shortcut connection直接将输入添加到输出上。如果维度不同,Identity Block不包含额外的卷积层来调整维度,因为输入和输出的维度已经匹配。
5. Convolutional Block(卷积块)
Convolutional Block与Identity Block的主要区别在于,它在shortcut connection中包含一个1x1的卷积层,用于调整输入的维度以匹配输出。这种块通常用于网络中需要改变特征图维度的地方,例如在不同的stage之间。
Input ─────────────────────────────────────┐
│ │
↓ ↓
1x1 Conv (filters1, stride=2) 1x1 Conv (filters3, stride=2)
│ │
↓ │
BatchNorm + ReLU │
│ │
↓ │
3x3 Conv (filters2) │
│ │
↓ │
BatchNorm + ReLU │
│ │
↓ │
1x1 Conv (filters3) │
│ │
↓ │
BatchNorm BatchNorm
│ │
↓ ↓
└──────────────── + ──────────────────┘
│
↓
ReLU
Convolutional Block的结构通常包括:
- 1x1卷积层:用于降维,同时应用stride来下采样。
- 3x3卷积层:用于提取特征。
- 1x1卷积层:用于升维,以匹配shortcut connection的输出维度。
- Batch Normalization:在每个卷积层后应用。
- Activation:通常是ReLU。
在Convolutional Block中,由于输入和输出的维度可能不同,因此需要一个额外的1x1卷积层来调整shortcut connection的维度,以便可以将输入添加到输出上。
2.2 ResNet50中的"50"
- ResNet50中的"50"代表网络的深度,即网络中包含50个卷积层
- 由多个残差块堆叠而成
- 5个阶段的卷积块组成
输入图像(224x224x3)
↓
7x7卷积, 64, /2
↓
3x3最大池化, /2
↓
[1x1卷积, 64 ]
[3x3卷积, 64 ] x 3
[1x1卷积, 256 ]
↓
[1x1卷积, 128 ]
[3x3卷积, 128 ] x 4
[1x1卷积, 512 ]
↓
[1x1卷积, 256 ]
[3x3卷积, 256 ] x 6
[1x1卷积, 1024 ]
↓
[1x1卷积, 512 ]
[3x3卷积, 512 ] x 3
[1x1卷积, 2048 ]
↓
全局平均池化
↓
1000-d 全连接层
↓
Softmax
二、代码运行及截图
1. 数据处理及可视化
import os,PIL,random,pathlib
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data_dir = './bird_photos/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("/")[1] for path in data_paths]
print(classeNames)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:", image_count)
output:

train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
test_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
total_data = datasets.ImageFolder("bird_photos/", transform=train_transforms)
total_data
output:
Dataset ImageFolder
Number of datapoints: 568
Root location: bird_photos/
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=warn)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
batch_size = 32
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True, # 对应 TensorFlow 的 shuffle
num_workers=4, # 多进程加载数据,类似 AUTOTUNE
pin_memory=True, # 将数据直接加载到 GPU 缓存,加速数据传输
prefetch_factor=2, # 预加载的批次数
persistent_workers=True # 保持工作进程存活,减少重新创建的开销
)
test_loader = DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=False, # 验证集不需要打乱
num_workers=4,
pin_memory=True,
prefetch_factor=2,
persistent_workers=True
)
for X, y in test_loader:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: " 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









