




FROM
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
我的环境
- 语言环境:Python 3.10.12
- 开发工具:Jupyter Lab
- 深度学习环境:
- torch==2.3.1+cu121
- torchvision==0.18.1+cu121
一、本周内容
1. ResNeXt 构建思路
ResNeXt 是由何凯明团队在 2017 年提出的一种新型图像分类网络,是 ResNet 的升级版。其核心思想是引入了 cardinality(基数) 的概念,即通过增加转换集合的大小来提升网络性能,而不是单纯地增加网络深度或宽度。ResNeXt 的设计基于以下几点:
- Split-Transform-Merge 策略:ResNeXt 采用了类似于 Inception 的分治思想,将输入特征拆分成多个组(group),每组独立进行卷积操作,最后将结果合并。这种设计在不增加计算复杂度的情况下,提高了特征的多样性。
- Cardinality:通过增加分组的数量(而不是增加卷积核的数量),ResNeXt 能够在保持计算量不变的情况下提升分类精度。
- 聚合残差结构:ResNeXt 的每个残差块聚合了一组具有相同拓扑结构的转换,这种设计使得网络在较深的结构下仍能保持高效的性能。
2.ResNeXt vs ResNet50V2 vs DenseNet
| 特性 | ResNeXt | ResNet50V2 | DenseNet |
|---|---|---|---|
| 核心思想 | 引入 cardinality,通过分组卷积提升特征多样性 | 预激活设计,优化深层网络的训练 | 密集连接,特征重用 |
| 网络结构 | 聚合残差结构,分组卷积 | 改进的瓶颈结构,预激活 | 密集块 + 过渡层 |
| 计算量 | 在相同深度下计算量较低 | 参数量较少,适合超深网络 | 参数利用效率高,但计算量可能较大 |
| 优势 | 在较深网络下精度更高 | 适合超深网络,训练更稳定 | 特征重用,泛化能力强 |
| 适用场景 | 需要高精度且计算资源有限 | 构建非常深的网络 | 数据量较大,需要强特征提取 |
二、核心代码及运行截图
import torch
import torch.nn as nn
import torch.nn.functional as F
class ResNeXtBottleneck(nn.Module):
expansion = 4
def __init__(self, in_channels, out_channels, stride=1, cardinality=32, base_width=4):
super().__init__()
width_ratio = out_channels / (cardinality * base_width)
D = cardinality * int(base_width * width_ratio)
self.conv_reduce = nn.Conv2d(in_channels, D, kernel_size=1, bias=False)
self.bn_reduce = nn.BatchNorm2d(D)
self.conv_conv = nn.Conv2d(D, D, kernel_size=3, stride=stride, padding=1, groups=cardinality, bias=False)
self.bn = nn.BatchNorm2d(D)
self.conv_expand = nn.Conv2d(D, out_channels * self.expansion, kernel_size=1, bias=False)
self.bn_expand = nn.BatchNorm2d(out_channels * self.expansion)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels * self.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * self.expansion)
)
def forward(self, x):
out = F.relu(self.bn_reduce(self.conv_reduce(x)), inplace=True)
out = F.relu(self.bn(self.conv_conv(out)), inplace=True)
out = self.bn_expand(self.conv_expand(out))
out += self.shortcut(x)
return F.relu(out, inplace=True)
class ResNeXt(nn.Module):
def __init__(self, block, layers, cardinality, num_classes=1000, base_width=4):
super().__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], 1, cardinality, base_width)
self.layer2 = self._make_layer(block, 128, layers[1], 2, cardinality, base_width)
self.layer3 = self._make_layer(block, 256, layers[2], 2, cardinality, base_width)
self.layer4 = self._make_layer(block, 512, layers[3], 2, cardinality, base_width)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride, cardinality, base_width):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride, cardinality, base_width))
self.in_channels = out_channels * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
x = self.relu(self.bn1(self.conv1(x)))
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
return self.fc(x)
def resnext50():
return ResNeXt(ResNeXtBottleneck, [3, 4, 6, 3], cardinality=32, num_classes=1000, base_width=4)
# 创建模型实例
model = resnext50().cuda()
model
输出:
ResNeXt(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): ResNeXtBottleneck(
(conv_reduce): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResNeXtBottleneck(
(conv_reduce): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(2): ResNeXtBottleneck(
(conv_reduce): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(layer2): Sequential(
(0): ResNeXtBottleneck(
(conv_reduce): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResNeXtBottleneck(
(conv_reduce): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(2): ResNeXtBottleneck(
(conv_reduce): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(3): ResNeXtBottleneck(
(conv_reduce): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(layer3): Sequential(
(0): ResNeXtBottleneck(
(conv_reduce): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResNeXtBottleneck(
(conv_reduce): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(2): ResNeXtBottleneck(
(conv_reduce): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(3): ResNeXtBottleneck(
(conv_reduce): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(4): ResNeXtBottleneck(
(conv_reduce): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(5): ResNeXtBottleneck(
(conv_reduce): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(layer4): Sequential(
(0): ResNeXtBottleneck(
(conv_reduce): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResNeXtBottleneck(
(conv_reduce): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(2): ResNeXtBottleneck(
(conv_reduce): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv_expand): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
训练结果:

绘制训练历史
输出:
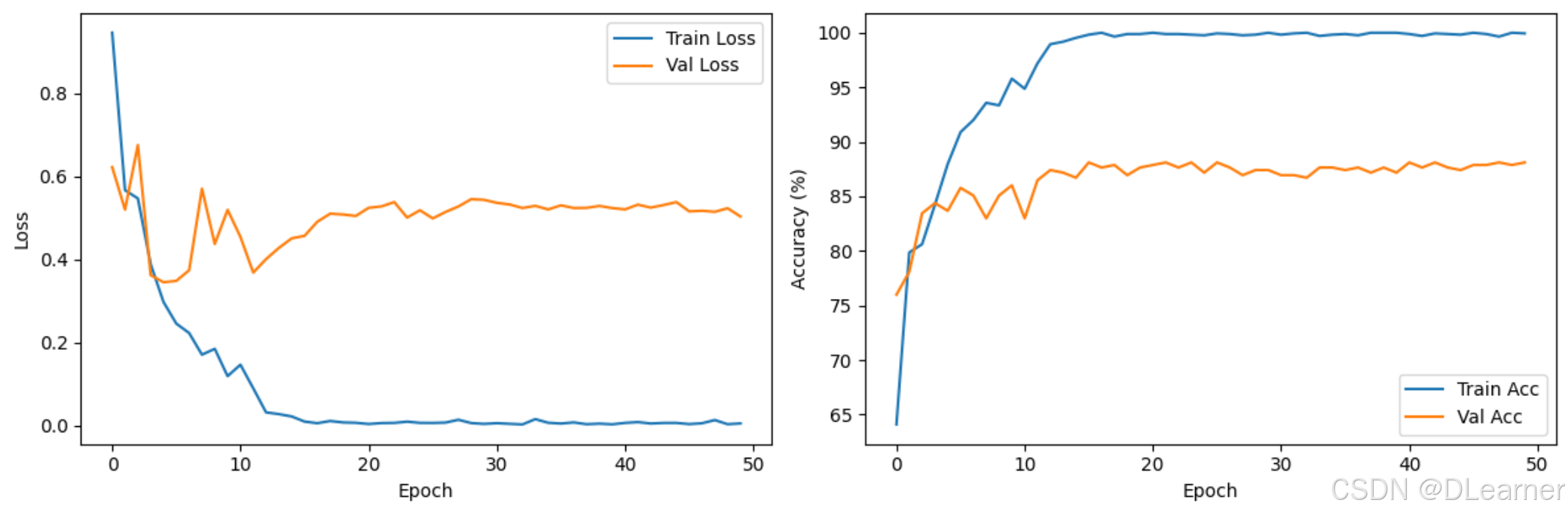
验证
import torch
from torchvision import transforms
from PIL import Image
# 加载模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = resnext50().cuda()
# 加载保存的文件
checkpoint = torch.load('best_resnetxt_model.pth', map_location=device)
# 只加载模型的参数
model.load_state_dict(checkpoint['model_state_dict'])
# 设置为评估模式
model.eval()
# 数据预处理
transform = transforms.Compose([
transforms.Resize(256), # 将图像大小调整为256x256
transforms.CenterCrop(224), # 从中心裁剪出224x224的图像
transforms.ToTensor(), # 将图像转换为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
# 加载图像
img1 = Image.open('./houdou/Monkeypox/M01_03_08.jpg') # 替换为图像路径
img2 = Image.open('./houdou/Others/NM01_01_06.jpg')
img1 = transform(img1).unsqueeze(0) # 添加批次维度
img1 = img1.to(device)
img2 = transform(img2).unsqueeze(0) # 添加批次维度
img2 = img2.to(device)
# 定义标签映射
label_mapping = {0: "猴痘", 1: "others"} # 假设 0 对应猴痘,1 对应 others
# 预测
with torch.no_grad():
outputs1 = model(img1)
_, predicted1 = torch.max(outputs1, 1)
outputs2 = model(img2)
_, predicted2 = torch.max(outputs2, 1)
# 输出预测结果
predicted_class1 = predicted1.item()
predicted_label1 = label_mapping[predicted_class1] # 将索引映射为标签
predicted_class2 = predicted2.item()
predicted_label2 = label_mapping[predicted_class2]
print(f'img1预测结果:{predicted_label1}')
print(f'img2预测结果:{predicted_label2}')
输出:


















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









