




FROM
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
我的环境
- 语言环境:Python 3.10.12
- 开发工具:Jupyter Lab
- 深度学习环境:
- tensorflow==2.13.1
一、本周内容和个人收获
1. DenseNet 基本内容
DenseNet(Densely Connected Convolutional Networks)是一种深度卷积神经网络架构,它通过在每一层之间引入直接连接来提高网络的信息流和参数效率。
1. 基本概念
DenseNet的核心思想: 在每一层,都从前N层接收特征图(feature maps),并将自己的输出作为后续N层的输入。这种连接方式使得每一层都可以直接访问前面所有层的特征,从而增强了特征传递,减少了参数数量。
2. Dense Block
DenseNet由多个Dense Block组成,每个Dense Block内部包含多个卷积层,每个卷积层的输出会直接连接到后续所有层的输入。
Dense Block的构建步骤:
- 输入特征图: 每个Dense Block的输入是前一个Dense Block的输出(对于第一个Dense Block,输入是原始输入数据)。
- 卷积层: 在Dense Block内部,每个卷积层(或称为“密集层”)都会进行卷积操作,并添加批量归一化(Batch Normalization)和ReLU激活函数。
- 特征图合并: 每个卷积层的输出会与之前所有层的输出合并,然后作为下一个卷积层的输入。
3. Transition Layer
在每个Dense Block之后,通常会有一个Transition Layer,用于降低特征图的维度和空间大小,以便控制参数数量和计算复杂度。
Transition Layer的构建步骤:
- 卷积层: 一个1x1的卷积层用于降低特征图的通道数。
- 池化层: 一个平均池化层(Average Pooling)用于降低特征图的空间维度。
2. DenseNet vs ResNetV2
| 特性 | DenseNet | ResNetV2 |
|---|---|---|
| 连接方式 | 每一层都与前面所有层有直接连接,特征图在层之间累积 | 每一层只与前一层有连接,通过残差连接实现 |
| 特征传递 | 特征图在网络中直接累积,信息流更丰富 | 通过跳跃连接传递特征,减少信息丢失 |
| 参数效率 | 由于特征图累积,参数数量相对较少 | 参数数量相对较多,但通过残差连接提高了训练深度 |
| 计算效率 | 由于特征图累积,计算量可能较大 | 通过优化的残差结构,计算效率较高 |
| 训练难度 | 较难训练非常深的网络,因为特征图累积导致维度爆炸 | 通过残差连接,可以训练更深的网络 |
| 批量归一化 | 通常在每个卷积层后使用 | 通常在每个卷积层后使用,且在V2版本中,批量归一化在每个残差块的开头 |
| 激活函数 | 通常在批量归一化后使用ReLU | 通常在批量归一化后使用ReLU |
| 全局平均池化 | 常用于DenseNet的分类任务 | 常用于ResNetV2的分类任务 |
| 压缩策略 | 通过特征图累积实现特征压缩 | 通过残差连接实现特征压缩 |
| 模型变体 | 有DenseNet-BC等变体 | 有ResNet-50, ResNet-101, ResNet-152等变体 |
二、核心代码及运行截图
import tensorflow as tf
from tensorflow.keras import layers, Model
from tensorflow.keras.regularizers import l2
class DenseLayer(layers.Layer):
"""DenseNet中的基本密集层"""
def __init__(self, growth_rate, bn_size, drop_rate=0, **kwargs):
super(DenseLayer, self).__init__(**kwargs)
self.growth_rate = growth_rate
self.bn_size = bn_size
self.drop_rate = drop_rate
self.bn1 = layers.BatchNormalization()
self.conv1 = layers.Conv2D(bn_size * growth_rate, kernel_size=1,
use_bias=False, kernel_initializer='he_normal')
self.bn2 = layers.BatchNormalization()
self.conv2 = layers.Conv2D(growth_rate, kernel_size=3, padding='same',
use_bias=False, kernel_initializer='he_normal')
self.dropout = layers.Dropout(drop_rate)
def build(self, input_shape):
super(DenseLayer, self).build(input_shape)
def call(self, inputs, training=None):
x = inputs
y = self.bn1(x, training=training)
y = tf.nn.relu(y)
y = self.conv1(y)
y = self.bn2(y, training=training)
y = tf.nn.relu(y)
y = self.conv2(y)
if self.drop_rate > 0:
y = self.dropout(y, training=training)
return tf.concat([x, y], axis=-1)
def get_config(self):
config = super(DenseLayer, self).get_config()
config.update({
'growth_rate': self.growth_rate,
'bn_size': self.bn_size,
'drop_rate': self.drop_rate
})
return config
class DenseBlock(layers.Layer):
"""DenseNet中的密集块"""
def __init__(self, num_layers, growth_rate, bn_size, drop_rate, **kwargs):
super(DenseBlock, self).__init__(**kwargs)
self.num_layers = num_layers
self.growth_rate = growth_rate
self.bn_size = bn_size
self.drop_rate = drop_rate
self.layers_list = [
DenseLayer(growth_rate, bn_size, drop_rate)
for _ in range(num_layers)
]
def call(self, inputs, training=None):
x = inputs
for layer in self.layers_list:
x = layer(x, training=training)
return x
def get_config(self):
config = super(DenseBlock, self).get_config()
config.update({
'num_layers': self.num_layers,
'growth_rate': self.growth_rate,
'bn_size': self.bn_size,
'drop_rate': self.drop_rate
})
return config
class TransitionLayer(layers.Layer):
"""DenseNet中的过渡层"""
def __init__(self, out_channels, **kwargs):
super(TransitionLayer, self).__init__(**kwargs)
self.out_channels = out_channels
self.bn = layers.BatchNormalization()
self.conv = layers.Conv2D(out_channels, kernel_size=1,
use_bias=False, kernel_initializer='he_normal')
self.pool = layers.AveragePooling2D(pool_size=2, strides=2)
def call(self, inputs, training=None):
x = inputs
x = self.bn(x, training=training)
x = tf.nn.relu(x)
x = self.conv(x)
x = self.pool(x)
return x
def get_config(self):
config = super(TransitionLayer, self).get_config()
config.update({
'out_channels': self.out_channels
})
return config
class DenseNet121(Model):
"""DenseNet-121模型实现"""
def __init__(self, growth_rate=32, compression_rate=0.5, num_classes=1000, **kwargs):
super(DenseNet121, self).__init__(**kwargs)
self.growth_rate = growth_rate
self.compression_rate = compression_rate
self.num_classes = num_classes
# 初始卷积层
self.conv1 = layers.Conv2D(64, kernel_size=7, strides=2, padding='same',
use_bias=False, kernel_initializer='he_normal')
self.bn1 = layers.BatchNormalization()
self.pool1 = layers.MaxPool2D(pool_size=3, strides=2, padding='same')
# DenseBlock的配置
block_config = [6, 12, 24, 16]
num_features = 64
# Dense blocks
self.blocks = []
for i, num_layers in enumerate(block_config):
block = DenseBlock(num_layers, growth_rate, bn_size=4, drop_rate=0.2)
self.blocks.append(block)
num_features += num_layers * growth_rate
if i != len(block_config) - 1:
out_channels = int(num_features * compression_rate)
trans = TransitionLayer(out_channels)
self.blocks.append(trans)
num_features = out_channels
self.bn_final = layers.BatchNormalization()
self.global_pool = layers.GlobalAveragePooling2D()
self.fc = layers.Dense(num_classes, kernel_initializer='he_normal')
def call(self, inputs, training=None):
x = inputs
x = self.conv1(x)
x = self.bn1(x, training=training)
x = tf.nn.relu(x)
x = self.pool1(x)
for block in self.blocks:
x = block(x, training=training)
x = self.bn_final(x, training=training)
x = tf.nn.relu(x)
x = self.global_pool(x)
x = self.fc(x)
return x
def get_config(self):
config = super(DenseNet121, self).get_config()
config.update({
'growth_rate': self.growth_rate,
'compression_rate': self.compression_rate,
'num_classes': self.num_classes
})
return config
def create_densenet121(num_classes=1000, include_top=True):
"""创建DenseNet-121模型的工厂函数"""
model = DenseNet121(num_classes=num_classes)
return model
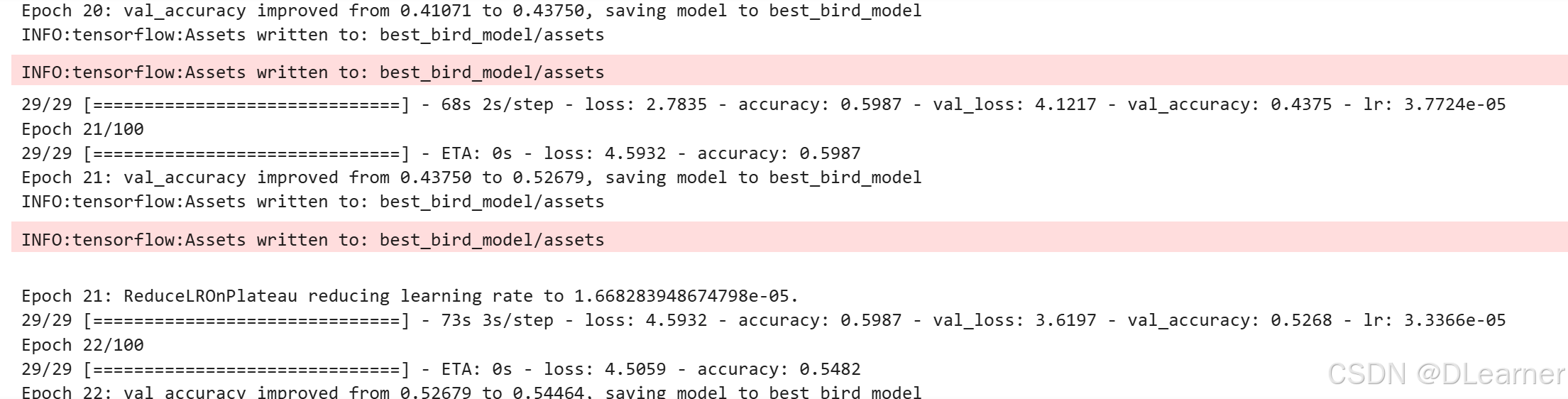
输出:在第42个epoch提前停止,最高的准确率在第20个epoch时

# 绘制训练历史
def plot_training_history(history):
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
# 绘制准确率
ax1.plot(history.history['accuracy'], label='train_accuracy')
ax1.plot(history.history['val_accuracy'], label='val_accuracy')
ax1.set_title('model accuracy')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('accuracy')
ax1.legend()
ax1.grid(True)
# 绘制损失
ax2.plot(history.history['loss'], label='train_loss')
ax2.plot(history.history['val_loss'], label='val_loss')
ax2.set_title('model loss')
ax2.set_xlabel('Epoch')
ax2.set_ylabel('loss')
ax2.legend()
ax2.grid(True)
plt.tight_layout()
plt.show()
# 显示训练结果
plot_training_history(history)
# 评估最终模型
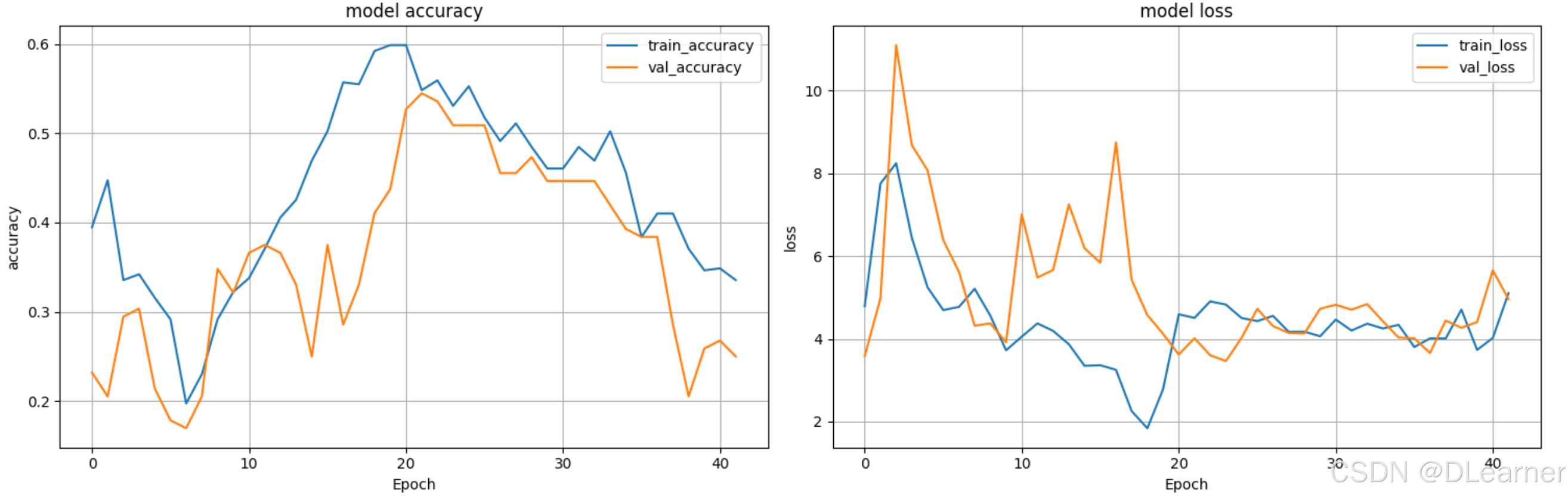
final_results = model.evaluate(validation_generator)
print(f"\n最终测试集准确率: {final_results[1]:.4f}")
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import seaborn as sns
from sklearn.metrics import confusion_matrix, classification_report
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用黑体显示中文
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
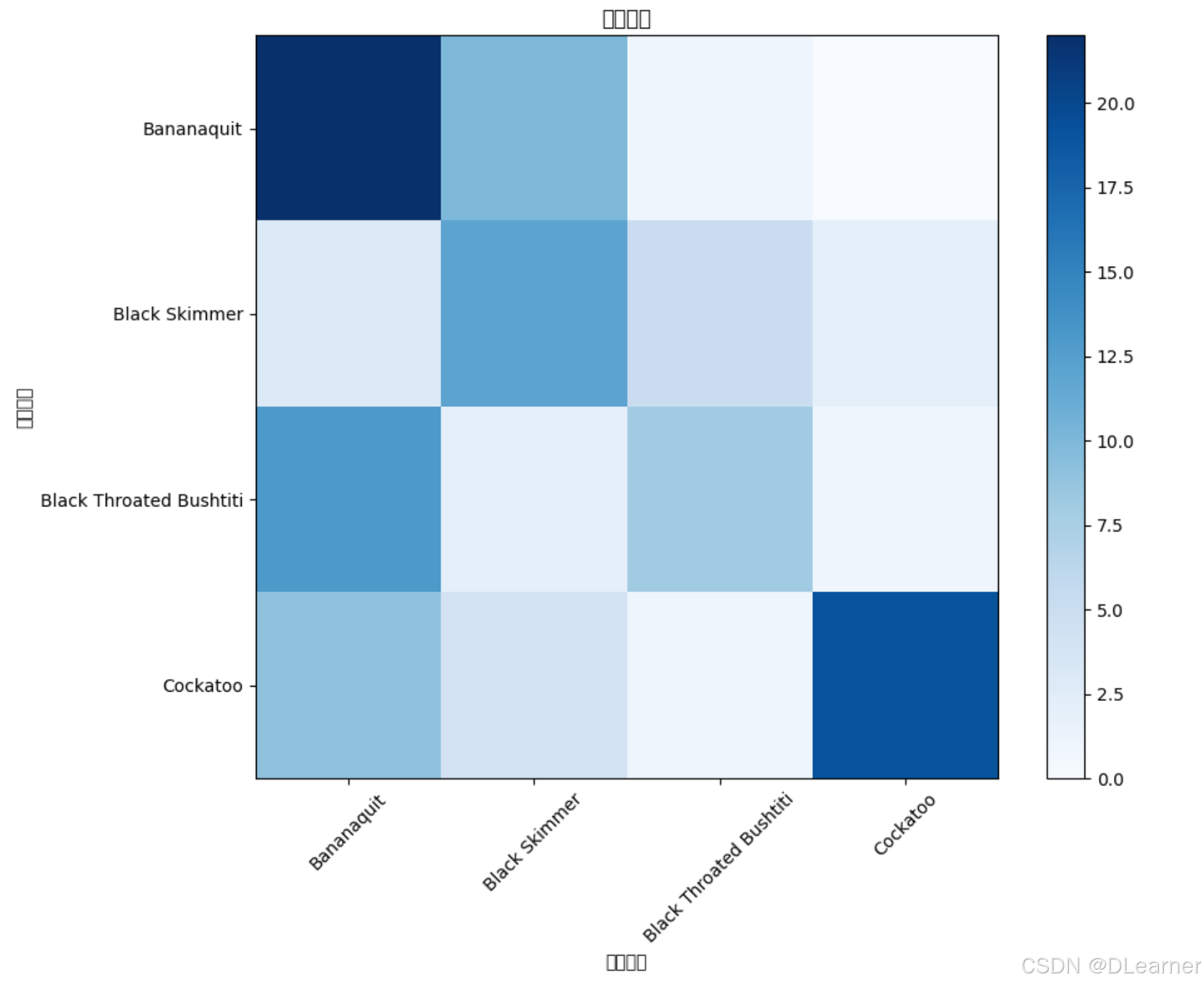
def evaluate_model(model, generator):
predictions = model.predict(generator)
predicted_classes = np.argmax(predictions, axis=1)
true_classes = generator.classes
# 计算混淆矩阵
cm = confusion_matrix(true_classes, predicted_classes)
# 获取类别名称
class_names = list(generator.class_indices.keys())
# 打印分类报告
print("\n分类报告:")
print(classification_report(true_classes, predicted_classes, target_names=class_names))
# 绘制混淆矩阵
plt.figure(figsize=(10, 8))
# 使用seaborn绘制更美观的混淆矩阵
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=class_names,
yticklabels=class_names)
plt.title('混淆矩阵', fontsize=12)
plt.xlabel('预测类别', fontsize=10)
plt.ylabel('真实类别', fontsize=10)
# 调整标签旋转角度以提高可读性
plt.xticks(rotation=45, ha='right')
plt.yticks(rotation=45)
# 调整布局以防止标签被切割
plt.tight_layout()
plt.show()
# 计算每个类别的准确率
print("\n每个类别的准确率:")
for i, class_name in enumerate(class_names):
class_correct = cm[i][i]
class_total = np.sum(cm[i])
accuracy = class_correct / class_total if class_total > 0 else 0
print(f"{class_name}: {accuracy:.4f} ({class_correct}/{class_total})")
# 评估模型性能
evaluate_model(model, validation_generator)
输出:


















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









