







 本文简要介绍了ResNet和DenseNet两种深度神经网络结构。ResNet通过残差学习解决深度网络训练难题,保持了信息传递;DenseNet则采用稠密连接,增强特征复用,降低梯度消失。这两种网络设计都对深度学习领域产生了深远影响。
本文简要介绍了ResNet和DenseNet两种深度神经网络结构。ResNet通过残差学习解决深度网络训练难题,保持了信息传递;DenseNet则采用稠密连接,增强特征复用,降低梯度消失。这两种网络设计都对深度学习领域产生了深远影响。
理论上来说,对神经网络添加新的层,充分训练之后应该更能够有效地降低误差。
因为原模型解的空间只能是新模型解空间的子空间。也就是说,新模型可能会得出更优的解来拟合训练数据。
但是在实践中却不是这样,添加过多的层后训练误差往往不降反升,即使利用批量归一化带来的数值稳定性训练能使训练深层模型更加容易,该问题依然存在。
针对这个问题,何凯明等人提出了残差网络(ResNet)。其在2015年的ImageNet图像识别挑战赛夺魁,并且深刻影响了后来的深度神经网络的设计。后来又出现借鉴残差网络思想的稠密连接网络(DenseNet)。这里只是做一个简单的认识,详细请看论文。
残差网络(ResNet)
顾名思义就是将原本经过神经网络的映射输出由f(x)变为f(x) - x,并且在神经网络旁将输入的数据x直接跨层之后与残差f(x) - x相加得到需要的映射f(x)。其中的基础块如下图所示:
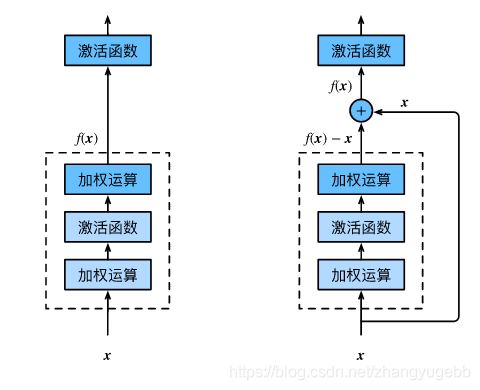
可以看出,这样做的优点是能够很好地保留上一层的正确信息,即在训练的时候不会出现训练误差因为模型的深度增加而增大的问题。并且跨层的连接设计让神经网络更加便于训练。
残差块(residual block)如下:
import time
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device(' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









