 DeepMVS:学习多视图立体声
DeepMVS:学习多视图立体声





 本文介绍了一种名为DeepMVS的网络,它能从任意数量的输入图像中预测高质量的视差图。该方法在真实数据集上进行预训练,并在无序图像集合中收集信息,利用VGG-19网络融合多层特征。在ETH3D数据集上的实验显示,DeepMVS在接近无纹理和薄结构区域的表现尤为突出。
本文介绍了一种名为DeepMVS的网络,它能从任意数量的输入图像中预测高质量的视差图。该方法在真实数据集上进行预训练,并在无序图像集合中收集信息,利用VGG-19网络融合多层特征。在ETH3D数据集上的实验显示,DeepMVS在接近无纹理和薄结构区域的表现尤为突出。
《DeepMVS: Learning Multi-view Stereopsis》
主要解决的问题:输入任意数量的姿态图像来预测高质量的视差图
主要描述
主要包含三部分:(1)在真实统一数据集上进行有监督的预训练;(2)提出一个有效的方法在无序的图像数据集中收集信息;(3)使用预训练的VGG-19网络来融入多层的特征。通过在 ETH3D数据集上对论文中提出的DeepMVS网络,进行对比实验,表现出良好的结果,尤其在接近没有纹理和薄结构上。
系统架构
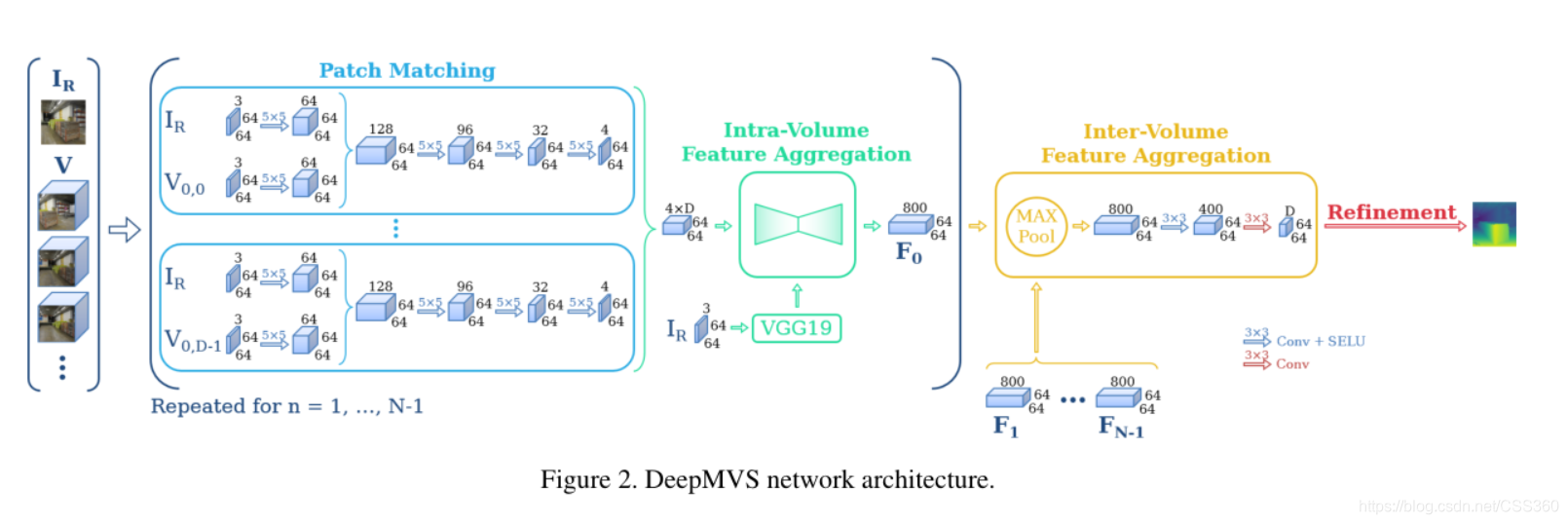
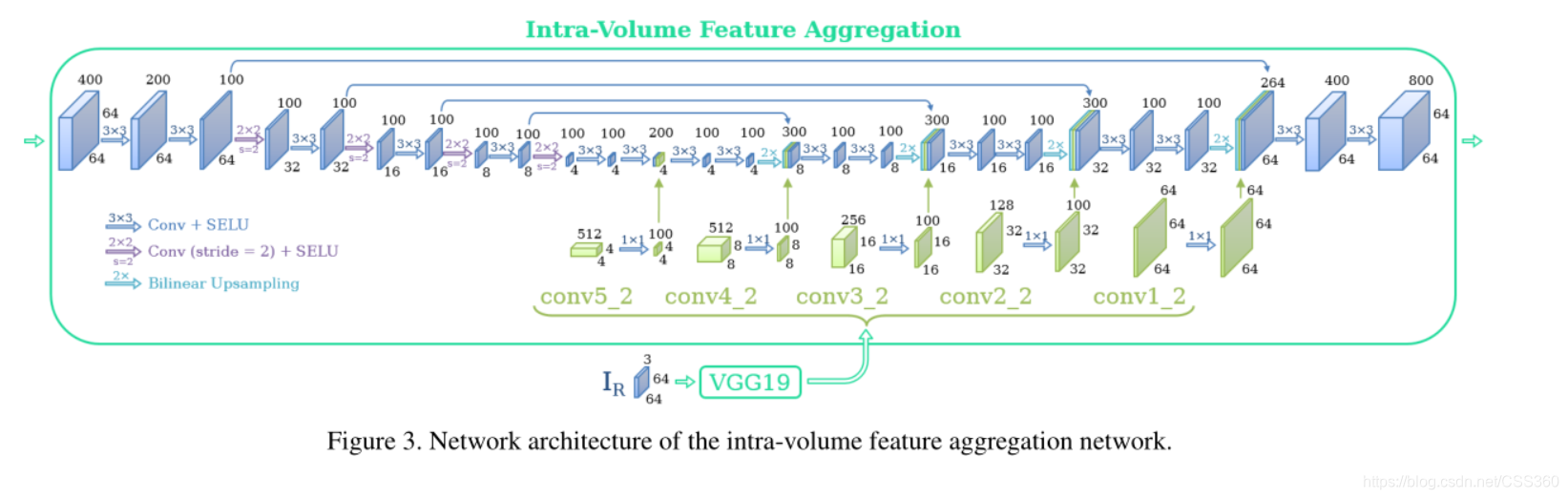
特征聚集
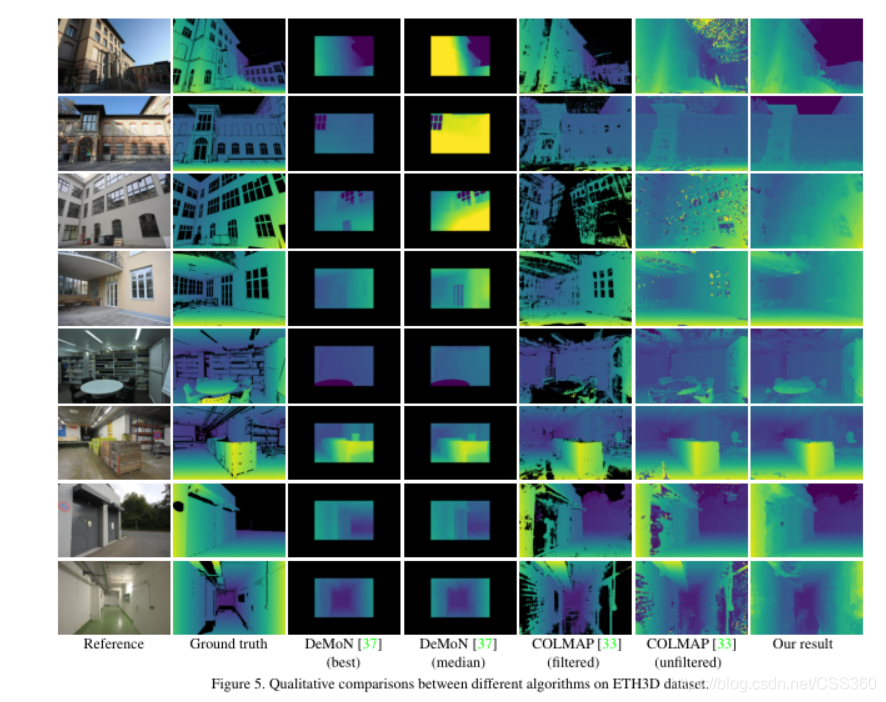
实验效果对比
结论
了解更多关于《计算机视觉与图形学》相关知识,请关注公众号:

下载我们视频中代码和相关讲义,请在公众号回复:计算机视觉课程资料

















 1545
1545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









