




 本文介绍了一种参数化控制人体姿态与形状,并将其自然嵌入3D场景中的技术框架。该方法通过统一的人像模型,结合3D场景的几何和语义信息,实现了人体与场景的无缝融合,有效避免了视觉伪影。实验在DeepFashion数据集上的表现良好。
本文介绍了一种参数化控制人体姿态与形状,并将其自然嵌入3D场景中的技术框架。该方法通过统一的人像模型,结合3D场景的几何和语义信息,实现了人体与场景的无缝融合,有效避免了视觉伪影。实验在DeepFashion数据集上的表现良好。
《Human Synthesis and Scene Compositing》
主要解决的问题:参数化控制人体姿态和形状,并将生成的人体嵌入到3D背景中
主要描述
本论文提出的框架主要包含三部分:(1)一个人像图像统一模型在控制姿态和外观,基于一个参数的展示;(2)一个人像插入处理,利用几何和语义的3D场景;(3)一个现实组成处理来创造一个无缝的融合在场景颜色和生成人体图像,以及避免视觉伪影。并在DeepFashion数据集上进行测试,得到比较好的结果。
系统框架

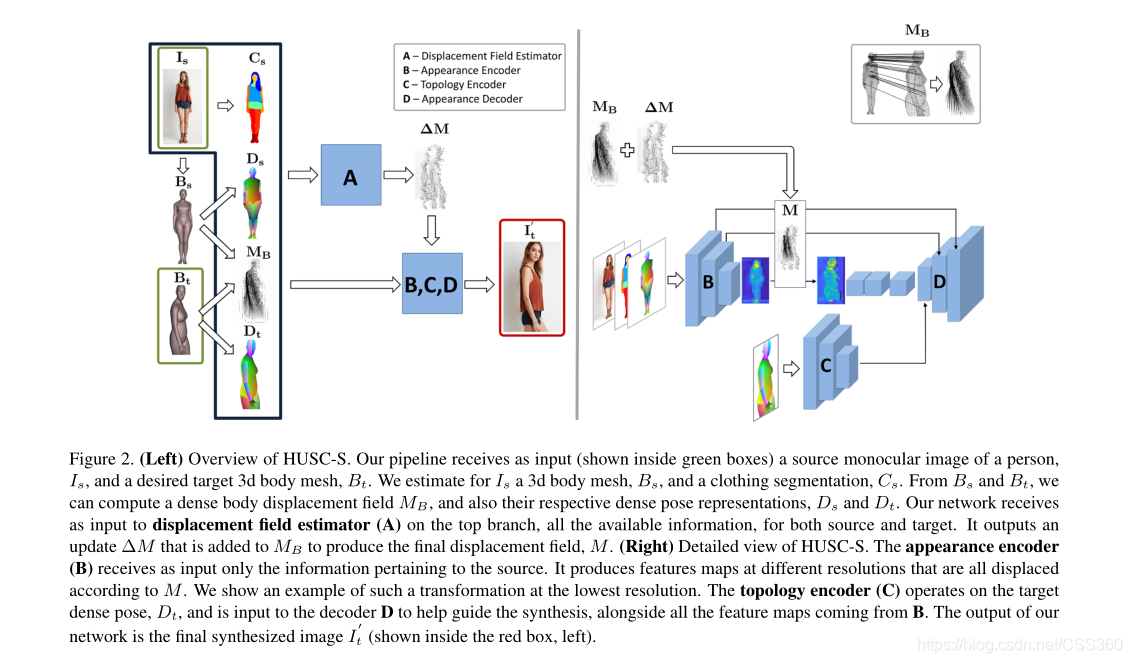
框架流程:输入一张人体的前景图,一个背景场景包含深度图和语义标签,以及一个目标的3D身体模型。首先,本论文使用北京场景来估计地面模板。在几何合成阶段,本论文给目标人体确定一个固定的3D位置,以及进行相关的视点转换,使用支持面法向进行对齐。通过HUSC-S网络,将新更新的目标人体形状和输入图像一起进行编码到目的表面。统一的前景图像结果在背景图中进行渲染,通过适当考虑深度排序约束。最后,它的外观使用论文中的外观组成网络来选择,为了得到最终的结果。
HUSC-S网络详解
指标对比

实验效果

主要工作
(1)在3D背景空间进行处理和操作;
(2)为解决空间尺度和模型闭合,引入场景的语义信息;
(3)使用参数化的3D人体和稠密几何对应关系,来较好的控制外观转化处理;
了解更多关于《计算机视觉与图形学》相关知识,请关注公众号:

下载我们视频中代码和相关讲义,请在公众号回复:计算机视觉课程资料

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









