



前言
多模态长文生成的一个思路,重点是怎么做图文的插图,以及细粒度的引用,所以,看一个工作。
核心还是要梳理清楚逻辑,多思考,多借鉴。
多模态长文写作的一个思路DeepWriter
最近看到一个工作,用多模态做长文写作的一个工作,《DeepWriter: A Fact-Grounded Multimodal Writing Assistant Based On Offline Knowledge Base》,https://arxiv.org/pdf/2507.14189,代码并未开源,但思路可借鉴。
1、任务设定
给定一个收集到的特定领域语料库 K {D1,…,D m} 和一个用户提供的查询或主题Q,目标是生成具有以下特征的长篇文档P,有几个要求:
包含多模态内容,文档应包括从语料库中抽取出来的相关图片、表格和图表;
具有事实依据,所有主张、数据和关键观点都必须附上引用,指向语料库中它们的来源;
语义要有连贯性,文档必须是逻辑一致的,并且从一个部分自然过渡到下一个部分。
2、设计思路
从设计思路看,有几点: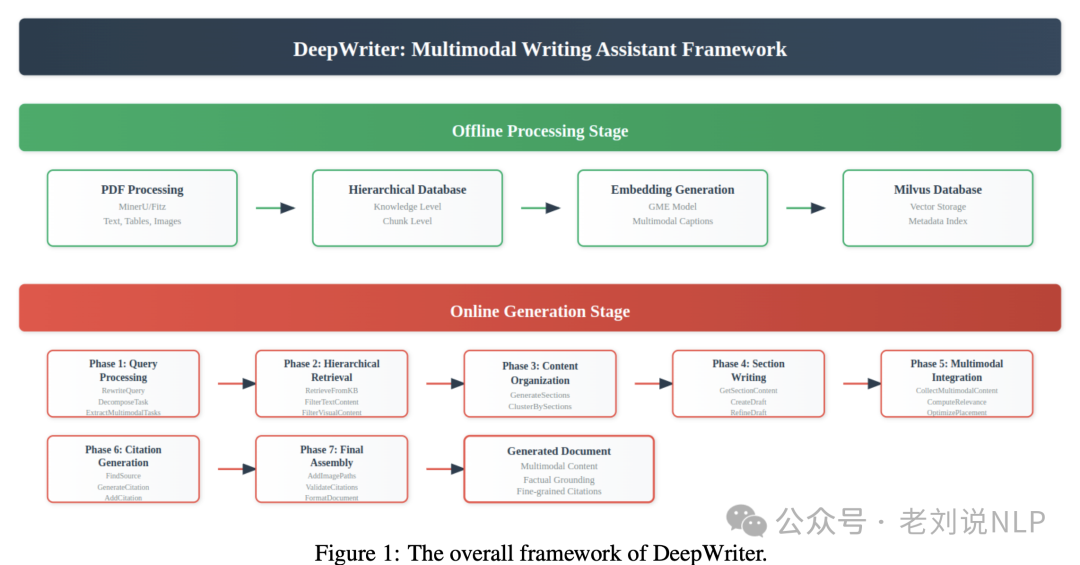 一个是分层知识表示(文档-页面-段落三级结构),支持高效多粒度检索与精准溯源;
一个是分层知识表示(文档-页面-段落三级结构),支持高效多粒度检索与精准溯源;
一个是结构化写作流程,涵盖任务分解、大纲生成、多模态检索、分节写作与反思机制;
一个是多模态内容融合,通过相关性评分与位置优化算法实现图文无缝集成;
一个是细粒度引用(文档级、段落级、句子级),确保生成内容可验证。
3、离线知识库构建
离线知识库构建上,收集PDF报告(如WTO年度贸易报告2001-2024);
工具采用MinerU/PyMuPDF提取文字、表格、图像,然后Qwen2.5-VL 7B生成图/表描述;
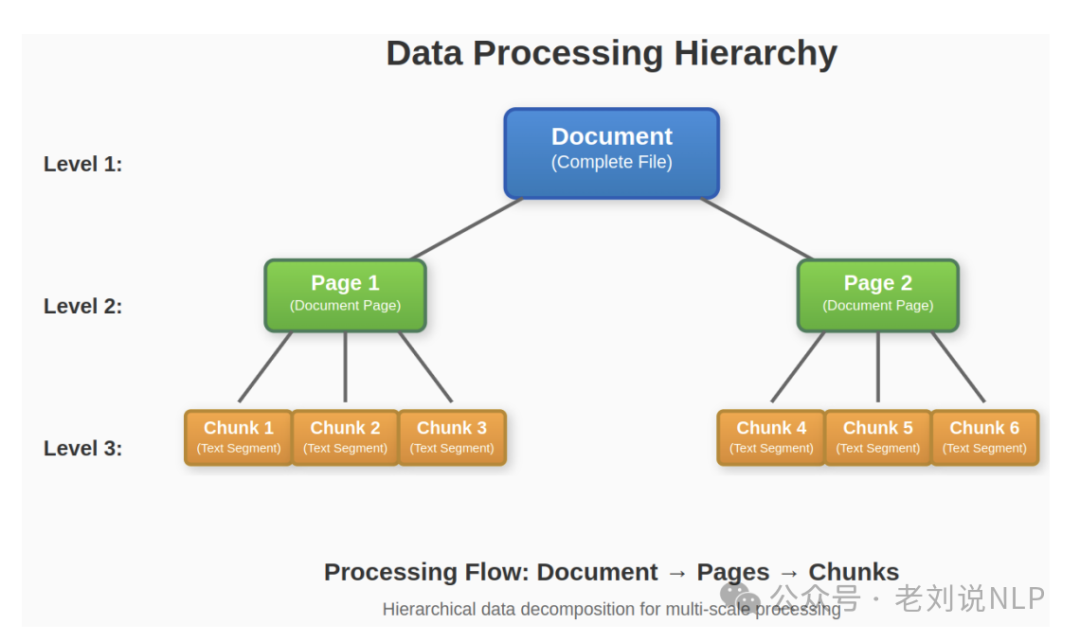
三层索引设置文档→页→知识块(chunk),"文档"顶级包含抽象概念,如年份或领域息;"页面"级别是一个中间级别,它在检索效率和粒度之间进行权衡;最终的"块"级别由知识片段组成,保存原始来源信息。
4、写作流程中的三个核心点
在线写作流程上包括7步:

其中重点看几个:
1)查询改写与任务分解:消除歧义,对初始用户查询Q进行重写和扩展,以更好地反映用户的意图,这有助于减少歧义,例如使用缩写或一般性问题。
然后,重写用户查询后,根据事实、数据点和观点来分解任务。

2)根据知识库分解的子任务或子查询进行多模态检索。
为了实现统一的多模态检索,利用GME(gme-Qwen2-VL-2B-Instruct),支持图像和文本作为输入的多模态嵌入模型,使用余弦相似度作为度量标准来选择前k个相关文档。
然后基于预先生成的章节标题对相关文档进行聚类,这降低了生成章节内容时的信息检索成本。

然后进行写作,这个也是依靠prompt实现:

以及章节内容写作的prompt:

以及全文摘要的内容:

3)文本-图像多模态插入
对于图像、表格和图表等多模态内容,确定它们在文本中的最佳位置需要对内容相关性和上下文流程进行复杂的推理。
所以,采用两阶段方法:内容相关性评分和上下文位置优化。
首先,使用相同的GME嵌入模型计算每个多模态元素与生成文本中每个段落之间的相关性分数。
然后,采用了一种考虑相关性分数和文档流程约束的位置优化算法,该算法确保图像被放置在与其最相关的文本描述附近,同时保持文档的逻辑结构。

做下解读,其核心任务是将图像等视觉元素自动插入到文档中的最佳段落位置,使得图文搭配更自然、语义更相关。
输入:M:一组视觉元素(如图表、图片等)以及P:文档中的段落集合,输出:每个视觉元素mk的最优插入位置posk
阶段1:图文语义相关性计算(1~7行),计算每个视觉元素mk与每个段落pi的语义相关度。使用GME_Similarity(mk,pi)(可能是图文跨模态相似度模型,如CLIP)打分;结果存入二维数组Sim[k][i],表示第k个图与第i段的相关性。
阶段2:最优位置选择与约束检查(8~17行),为每个图找到最佳段落位置,并检查排版约束。
首先,初筛最优位置:对每个图mk,选择与其最相关的段落best_pos=argmax(Sim[k][i])。其次,约束检查:调用CheckFlowConstraints验证该位置是否满足:排版规则(如是否会导致分页断裂、段落间距是否合理等),最后调整策略:若满足约束,直接将该位置作为posk,若不满足,调用FindAlternativePosition寻找次优解(如相邻段落或调整图文顺序)。
核心点为,跨模态语义对齐:通过GME_Similarity实现图文语义匹配(如图片内容与段落主题的契合度);约束驱动优化:不仅考虑相关性,还通过CheckFlowConstraints保证排版合理性(如避免图片覆盖文字、保持阅读流畅性);容错机制:当最优位置不可行时,自动退而求其次,避免算法失效。
4)引用生成
引用生成,也是要做成三层,文档级别、段落级别和句子级别,算法如下:

每个引用包括元数据,如源文件名、页码和块边界框,以实现精确的来源验证。
对于多模态内容,引用还包括图像和表格的边界框坐标。
输入:c:声明(claim),需要被引用的内容。R:检索到的内容集合,可能包含多个文档或文档片段;输出:citation:包含精确源位置的引用对象。
阶段1:最佳匹配项选择(1~9行),在检索到的内容中找到与声明最相关的项。初始化best_match为∅(空),highest_score为0。遍历每个检索到的项r,计算声明c与项r内容的语义相似度score。如果score高于highest_score,则更新highest_score和best_match。
阶段2:引用创建与粒度确定(10~18行),根据最佳匹配项创建引用,并确定引用的粒度(文档、段落或句子)。调用CreateCitation(best_match)创建引用对象。调用DetermineGranularity(best_match)确定引用的粒度。
根据粒度设置引用的详细信息:文档级别:仅包含文件名;段落级别:包含文件名和段落ID。句子级别:包含文件名、段落ID和句子ID。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1272
1272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









