



前言
检索增强生成(RAG)的兴起改变了 AI 和搜索领域的范式,通过将向量搜索与生成模型的力量融合在一起。然而,这项技术并非没有局限性。所谓搜索增强生成,首先必须有搜索这一步,而搜索这一步有很多难点:向量召回准确率的提升很难,所以一般会考虑传统的BM25搜索和向量搜索一起进行搜索。但有时候依然效果不好,自己想要的没被召回来。
这时候我们来借鉴一下传统的搜索技术看看有什么可以进行优化的。在真正的搜索之前其实有 查询词处理与文本理解 这一步,其涉及到很多NLP技术,比如分词,NER,同义词,词权重,意图识别,查询词的改写等一系列的NLP任务。这样可以丰富搜索信息让搜索更加准确。
我们可不可以借用大模型去优化 查询词处理与文本理解 这一重要步骤呢。接下来笔者介绍的RAG-FUSE 就是利用大模型对query进行改写,丰富了搜索信息。所以其实当RAG效果不好时,在query预处理上做文章也能收到效果。
RAG-Fusion方案
RAG-fusion 方案其实简单来说就是使用 LLM 将 用户原始查询 改写成N个不同的查询,然后分别进行检索,最终汇众多路检索的结果,进行重新排列,以选择最相关的答案。
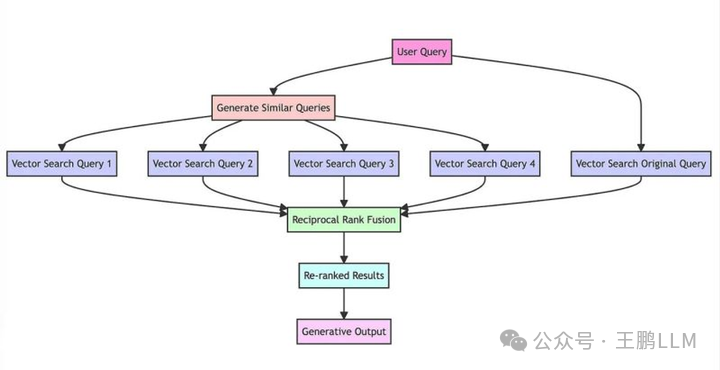
主要流程如下图所示:
查询生成/改写:使用 LLM 模型对用户的初始查询,进行改写生成多个查询。
向量搜索:对每个生成的查询进行基于向量的搜索,形成多路搜索召回。
倒数排序融合RRF:应用倒数排名融合算法,根据文档在多个查询中的相关性重新排列文档。
重排: 使用更高精度的排序模型对上一步RRF排序结果进行重排。
输出生成:然后可以参考重新排列后的TOPK搜索结果,生成最终输出。
RAG-Fusion
倒数排序融合 Reciprocal rank fusion (RRF)
RRF一个将各个不同的召回路中序列进行融合排序的方案。混排公式如下:
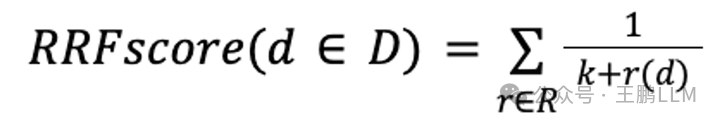
RRF
- D - 文档集
- R - 文档在某路召回路的排名
- K - 通常默认设置为 60
一言以蔽之就是:将文档在每个序列中 排名的倒数是相加 作为最终的排序得分,然后倒序排列。这个公式主要是想衡量一个文档是不是在N个序列中都排在前面,如果在每一个召回序列中都排在前面,在混合过程中也将它排在前面。
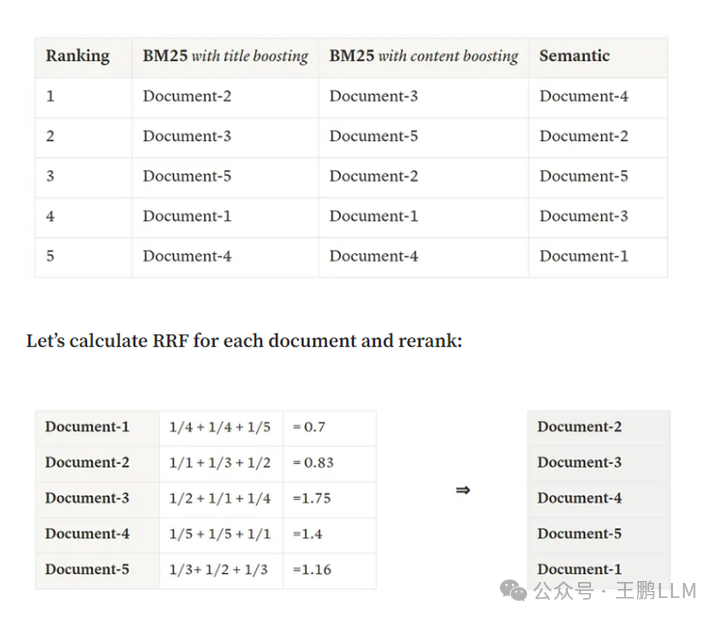
比如下图是一个搜索query,通过三种不同的召回方式进行了搜索召回:
1.title的BM25得分
2.content的BM25得分
3.语义相似性得分
这3路召回中,每路召回的序列都不一样,然后对这3个序列进行混合的案例 其中docment-2在3个序列中分别排在1,3,2。综合得分 1/1 + 1/3 +1/2 = 1.83
RAG-Fusion实战
这里的代码来自于https://github.com/Raudaschl/rag-fusion,整个流程就是:
查询改写—>多路搜索召回(内部逻辑没实现)—>倒数排序融合—>结果输出。
并没有重排步骤,以及基于搜索结果的生成过程。
import os
import openai # 导入 openai 库
import random # 导入 random 库
# 初始化 OpenAI API
openai.api_key = os.getenv("OPENAI_API_KEY") # 从环境变量中获取 OpenAI API 密钥,也可以直接在 main.py 中设置
if openai.api_key is None: # 如果没有找到 OpenAI API 密钥,抛出异常
raise Exception("No OpenAI API key found. Please set it as an environment variable or in main.py")
# 定义一个函数,使用 OpenAI 的 ChatGPT 模型来生成多个查询
def generate_queries_chatgpt(original_query):
response = openai.ChatCompletion.create( # 调用 OpenAI 的 ChatCompletion 接口,创建一个聊天对话
model="gpt-3.5-turbo", # 使用 gpt-3.5-turbo 模型
messages=[ # 设置聊天消息
{"role": "system", "content": "You are a helpful assistant that generates multiple search queries based on a single input query."}, # 系统角色的消息,介绍自己的功能
{"role": "user", "content": f"Generate multiple search queries related to: {original_query}"}, # 用户角色的消息,输入一个原始查询
{"role": "user", "content": "OUTPUT (4 queries):"} # 用户角色的消息,指定输出的查询个数
]
)
generated_queries = response.choices[0]["message"]["content"].strip().split("\\n") # 从响应中获取生成的查询,去掉首尾空格,按换行符分割
return generated_queries # 返回生成的查询
# 定义一个模拟函数,用于模拟向量搜索,返回随机的分数
def vector_search(query, all_documents):
available_docs = list(all_documents.keys()) # 获取所有文档的键(文档名)
random.shuffle(available_docs) # 随机打乱文档的顺序
selected_docs = available_docs[:random.randint(2, 5)] # 随机选择 2 到 5 个文档作为搜索结果
scores = {doc: round(random.uniform(0.7, 0.9), 2) for doc in selected_docs} # 为每个文档生成一个 0.7 到 0.9 之间的随机分数,保留两位小数
return {doc: score for doc, score in sorted(scores.items(), key=lambda x: x[1], reverse=True)} # 按分数降序排序,返回文档和分数的字典
# 定义一个函数,实现互换排名融合算法
def reciprocal_rank_fusion(search_results_dict, k=60):
fused_scores = {} # 创建一个空字典,用于存储融合后的分数
print("Initial individual search result ranks:") # 打印初始的各个查询的搜索结果排名
for query, doc_scores in search_results_dict.items(): # 遍历每个查询和对应的文档分数
print(f"For query '{query}': {doc_scores}") # 打印每个查询和对应的文档分数
for query, doc_scores in search_results_dict.items(): # 再次遍历每个查询和对应的文档分数
for rank, (doc, score) in enumerate(sorted(doc_scores.items(), key=lambda x: x[1], reverse=True)): # 按分数降序排序,遍历每个文档和对应的排名
if doc not in fused_scores: # 如果文档不在融合分数的字典中
fused_scores[doc] = 0 # 初始化文档的融合分数为 0
previous_score = fused_scores[doc] # 获取文档的之前的融合分数
fused_scores[doc] += 1 / (rank + k) # 根据互换排名融合算法,更新文档的融合分数
print(f"Updating score for {doc} from {previous_score} to {fused_scores[doc]} based on rank {rank} in query '{query}'") # 打印更新文档分数的过程
reranked_results = {doc: score for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)} # 按融合分数降序排序,返回重新排名的结果
print("Final reranked results:", reranked_results) # 打印最终的重新排名的结果
return reranked_results # 返回重新排名的结果
# 定义一个模拟函数,用于模拟生成输出
def generate_output(reranked_results, queries):
return f"Final output based on {queries} and reranked documents: {list(reranked_results.keys())}"# 返回一个字符串,包含生成的查询和重新排名的文档
# 预定义的文档集合(通常这些文档会来自搜索数据库)
all_documents = {
"doc1": "Climate change and economic impact.",
"doc2": "Public health concerns due to climate change.",
"doc3": "Climate change: A social perspective.",
"doc4": "Technological solutions to climate change.",
"doc5": "Policy changes needed to combat climate change.",
"doc6": "Climate change and its impact on biodiversity.",
"doc7": "Climate change: The science and models.",
"doc8": "Global warming: A subset of climate change.",
"doc9": "How climate change affects daily weather.",
"doc10": "The history of climate change activism."
}
# 主函数
if __name__ == "__main__":
original_query = "impact of climate change"# 设置原始查询为“影响气候变化”
generated_queries = generate_queries_chatgpt(original_query) # 调用 generate_queries_chatgpt 函数,生成多个查询
all_results = {} # 创建一个空字典,用于存储所有查询的搜索结果
for query in generated_queries: # 遍历每个生成的查询
search_results = vector_search(query, all_documents) # 调用 vector_search 函数,对每个查询进行向量搜索
all_results[query] = search_results # 将每个查询的搜索结果存入字典
reranked_results = reciprocal_rank_fusion(all_results) # 调用 reciprocal_rank_fusion 函数,对所有查询的搜索结果进行互换排名融合
final_output = generate_output(reranked_results, generated_queries) # 调用 generate_output 函数,生成最终的输出
print(final_output) # 打印最终的输出
结语:
当然这样利用大模型去进行搜索query改写,虽然能够带来更丰富的搜索信息,但是性能上会受到损失,产品上的设计一定要考虑这一点。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









