






前言
直接以官方训练结果为例,简单介绍一下yolov8在 jetson orin nx部署过程。方便大家学习参!
一、板端环境配置
1、Jetson Orin NX 硬件介绍
NVIDIA® Jetson Orin™ NX 算力高达 100 TOPS,性能是上一代产品的 5 倍,适用于多个并发 AI 推理管道,此外它还可以通过高速接口连接多个传感器,因此可为新时代机器人提供理想的解决方案。Jetson Orin NX 模组极其小巧,但可提供高达 100 TOPS 的 AI 性能,功率可在 10 W到 25 W之间进行配置。此模组的性能可高达 Jetson AGX Xavier 的 3 倍、Jetson Xavier NX 的 5 倍。
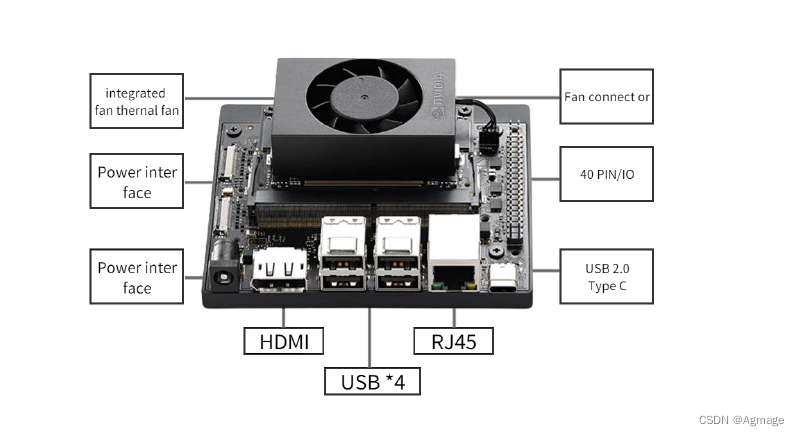
更多详情可以查看链接:https://qr.1688.com/s/g49cgwQc
2、进行刷机处理,刷好相应的NVIDIA Jetson orin nx环境
- CUDA 11.4
- CUDNN 8.6.0
- TensorRT 8.5.2
- Opencv 4.2.0 without Cuda
3、安装ros nostic
# 1、设置sources.list
sudo sh -c 'echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list'
# 或清华源
sudo sh -c '. /etc/lsb-release && echo "deb http://mirrors.tuna.tsinghua.edu.cn/ros/ubuntu/ `lsb_release -cs` main" > /etc/apt/sources.list.d/ros-latest.list'
# 2、设置密钥
sudo apt-key adv --keyserver 'hkp://keyserver.ubuntu.com:80' --recv-key C1CF6E31E6BADE8868B172B4F42ED6FBAB17C654
# 3、安装
sudo apt update
sudo apt install ros-noetic-desktop-full
# 4、设置环境
echo "source /opt/ros/noetic/setup.bash" >> ~/.bashrc
source ~/.bashrc
二、转换模型
1、(可选)去ultralytics下载官方模型yolov8n.pt 、yolov8n-seg.pt和yolov8n-pose.pt模型(电脑里完成)使用yolov8的环境即可。
git clone https://github.com/linClubs/YOLOv8-ROS-TensorRT.git
# 1 进入scripts目录
cd YOLOv8-ROS-TensorRT/scripts
# 2 det
python export-det.py --weights ../weights/yolov8n.pt --iou-thres 0.65 --conf-thres 0.2 --topk 100 --opset 11 --sim --input-shape 1 3 640 640 --device cuda:0
# 3 seg
python export-seg.py --weights ../weights/yolov8n-seg.pt --opset 11 --sim --input-shape 1 3 640 640 --device cuda:0
# 4 pose 修改export-pose.py的模型路径 model = YOLO("../weights/yolov8n-pose.pt")
python export-pose.py
# 生成的onnx与对应的pt在同级目录
2、板端下载代码并编译
mkdir yolov8_ws && cd yolov8_ws
git clone https://github.com/linClubs/YOLOv8-ROS-TensorRT.git -b noetic-devel ./src/YOLOv8-ROS-TensorRT
catkin_make
3、进行模型转换,分别转换三个模型
# pc上
~/software/TensorRT-8.5.3.1/bin/trtexec --onnx=yolov8l-seg.onnx --saveEngine=yolov8l-seg.engine
# orin上
/usr/src/tensorrt/bin/trtexec --onnx=yolov8n-seg.onnx --saveEngine=yolov8n-seg.engine
三、运行
1、修改对应的launch文件的参数,对应bag里的话题
- topic_img 待检测的图像话题
- topic_res_img 结果图像发布话题
- weight_name 权重名称,权重放入weights目录下
2、启动算法运行对应launch即可
# detect
roslaunch yolov8_trt detect.launch
# pose
roslaunch yolov8_trt pose.launch
# segment
roslaunch yolov8_trt segment.launch
注:此时我们需要bag包作为输入,本人使用的是kitti数据集生成的bag包
官网:http://www.cvlibs.net/datasets/kitti/raw_data.php
选择自己想要的场景,下载[synced+rectified data] [calibration] 两个即可
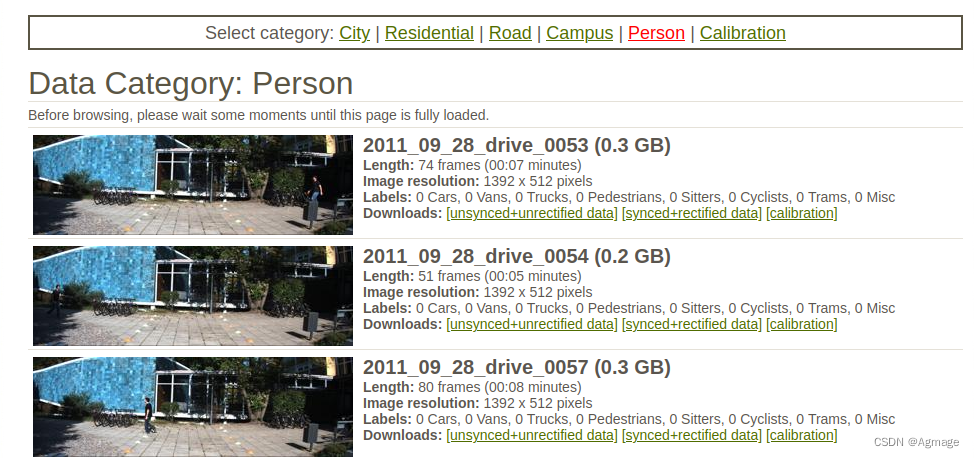
安装kitti2bag
pip install kitti2bag
将下载的两个压缩包分别解压后复制到对应目录
├─2011_09_28_drive_0053_sync
│ ├─2011_09_28
│ │ ├─calib_cam_to_cam.txt # 2011_09_28_calib.zip 解压后复制过来
│ │ ├─calib_imu_to_velo.txt
│ │ ├─calib_velo_to_cam.txt
│ │ ├─2011_09_28_drive_0053_sync
│ │ │ └─image_00
⁞
然后就可以使用kitti2bag工具将KITTI数据集转化为rosbag包
切换到2011_09_28文件夹所在目录
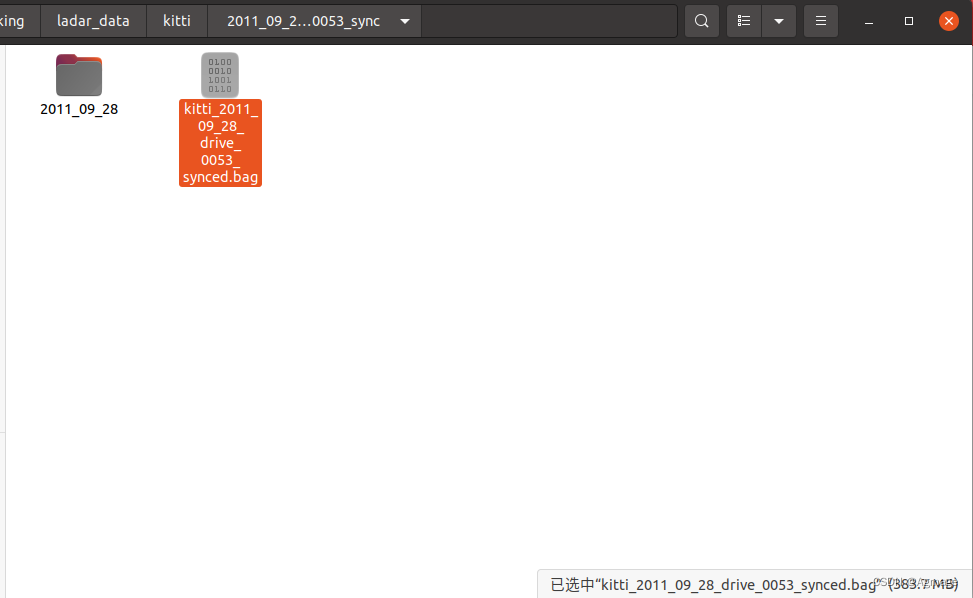
3、执行kitti2bag命令
kitti2bag -t 2011_09_28 -r 0053 raw_synced
注意:0053是第多少次drive,注意自己下载的数据集的drive
转换后的bag包
4、此时修改launch文件的topic_img为/kitti/camera_color_left/image_raw后运行。
source devel/setup.bash
roslaunch yolov8_trt detect.launch
# 新建终端
rosbag play kitti_2011_09_28_drive_0053_synced.bag -l
# 新建终端 查看结果
rviz
结果图片如下

四、结束语
到这NVIDAIJetson Orin NX 基于 ros部署 yolov8完成啦,大家可根据自己的需求进行开发学习了。需了解更多内容,扫描了解更多详情。



















 2561
2561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











