




引子

Google’s Gemini 2.5 paper has 3295 authors
2025年7月7日,Google DeepMind 在 arXiv 上正式发布了题为 “Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities” 的技术报告,竟然有3295名作者,堪称史上最拥挤的作者群。该报告详细介绍了 Gemini 2.5 Pro 和 Flash 模型在内建链式思考(built-in reasoning)、原生多模态处理(文本、图像、视频、音频)及超长上下文(最高支持 1,000,000 Token)方面的关键技术创新 Google Cloud Storageblog.google。该报告介绍新一代 Gemini 2.5 Pro 在常见 AI 基准测试中大幅领先,尤其在高级推理和代码生成任务上展现了显著优势;同时,Gemini 2.5 Flash 提供了在成本与延迟间可控的“思考”预算,满足不同场景需求。之前,媒体普遍关注其突破性性能,但也对安全框架披露不足提出批评;AI 社区专家既认可其多模态与长上下文处理能力,又呼吁更透明的安全评估细节。本文主要借助该论文的发表,收集相关报道并进一步分析一下Gemini 2.5的深入细节和模型对比。
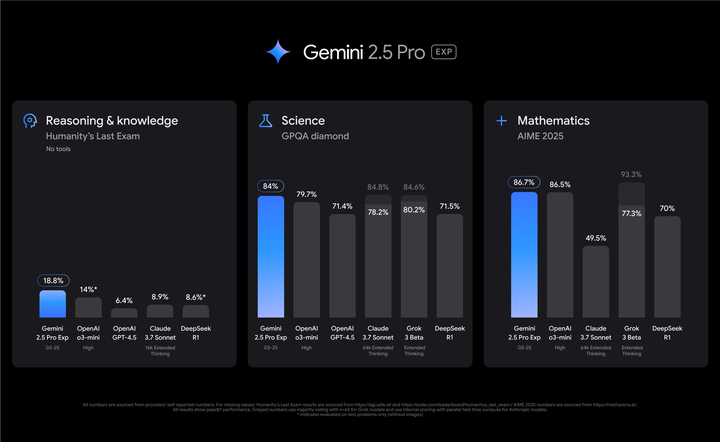
Gemini 2.5 Pro evaluation
媒体评价
-
正面报道:技术能力与商业化前景
-
Google Cloud 博客指出,Gemini 2.5 Pro 和 Flash 的扩展能力,可助力企业构建更复杂且安全的 AI 驱动应用和代理系统 Google Cloud。
-
在 Google I/O 2025 上,官方进一步公布了 Deep Think 增强推理模式和优化更新,强调开发者社区对 2.5 Pro 在代码生成领域的广泛好评 blog.google,IQ智商测试也是最高的(参考下图)。
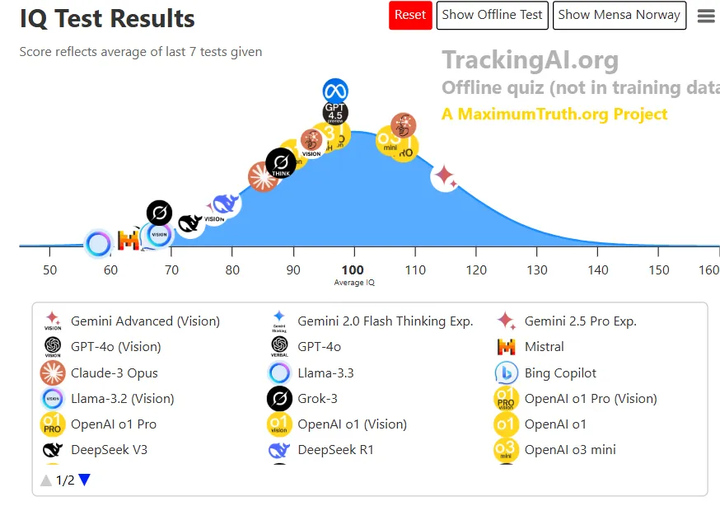
添加图片注释,不超过 140 字(可选)
-
多家技术媒体测评显示,Gemini 2.5 Pro 在 LM Arena 排行榜上遥遥领先,且在实际应用中能解决以往模型难以触及的高级场景 Medium。
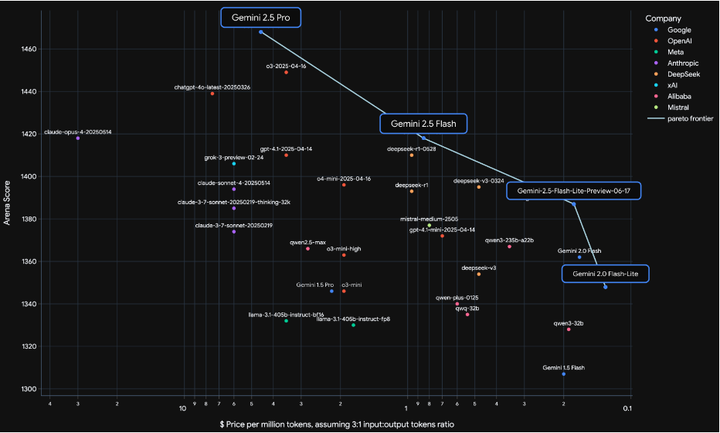
LMArena score
-
批评声音:安全与透明度不足
-
TechCrunch 报道中,多位受访专家对官方报告中 Frontier Safety Framework(FSF)的细节披露不够表示失望,认为应提供更完整的安全评估数据 TechCrunch。
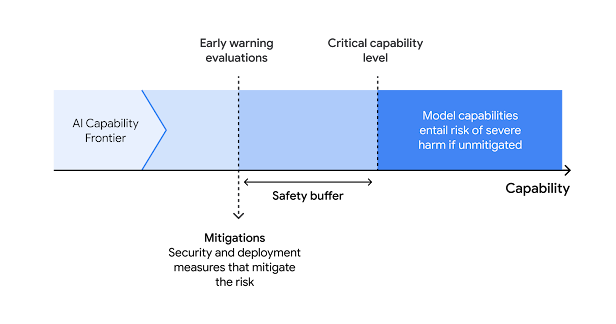
Frontier Safety Framework(FSF)
-
Fortune 的 AI 治理评论家指出,Google 在发布模型时未同步公布详细的安全评估文档,这种“空白”可能加大后续风险管理难度 财富杂志。
-
The Times 指出,随着 AI Overview 功能集成,Gemini 系列也面临生成错误信息(hallucination)的批评,影响用户信任度 泰晤士报。
专家观点
-
模型能力认可
-
多位 AI 研究者在 arXiv 版本的论文评论中肯定了 Gemini 2.5 Pro 在多模态推理与长上下文处理上的巨大进展,认为这为通用 AI 助手愿景迈出了关键一步 arXiv。
-
TechRadar 的使用者评价则强调,Deep Research 工具配合 2.5 Pro 能提供意想不到的深度探索结果,尽管有时会“过度思考”,但仍展现出显著潜力
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1820
1820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









