



“AI infra 课程”在大学里一般不会直接叫 “AI Infrastructure”(涉及内容比较繁多,单从软件stack就很复杂,如下图按照市场角色划分),而在大学中一般分散在几类:MLSys / ML systems、AI data center / HPC、生产级 ML / MLOps、ML 硬件与加速器等课程中涉及。为此,本文主要收集世界名校最新的相关课程,便于系统性补充AI infra 领域相关知识。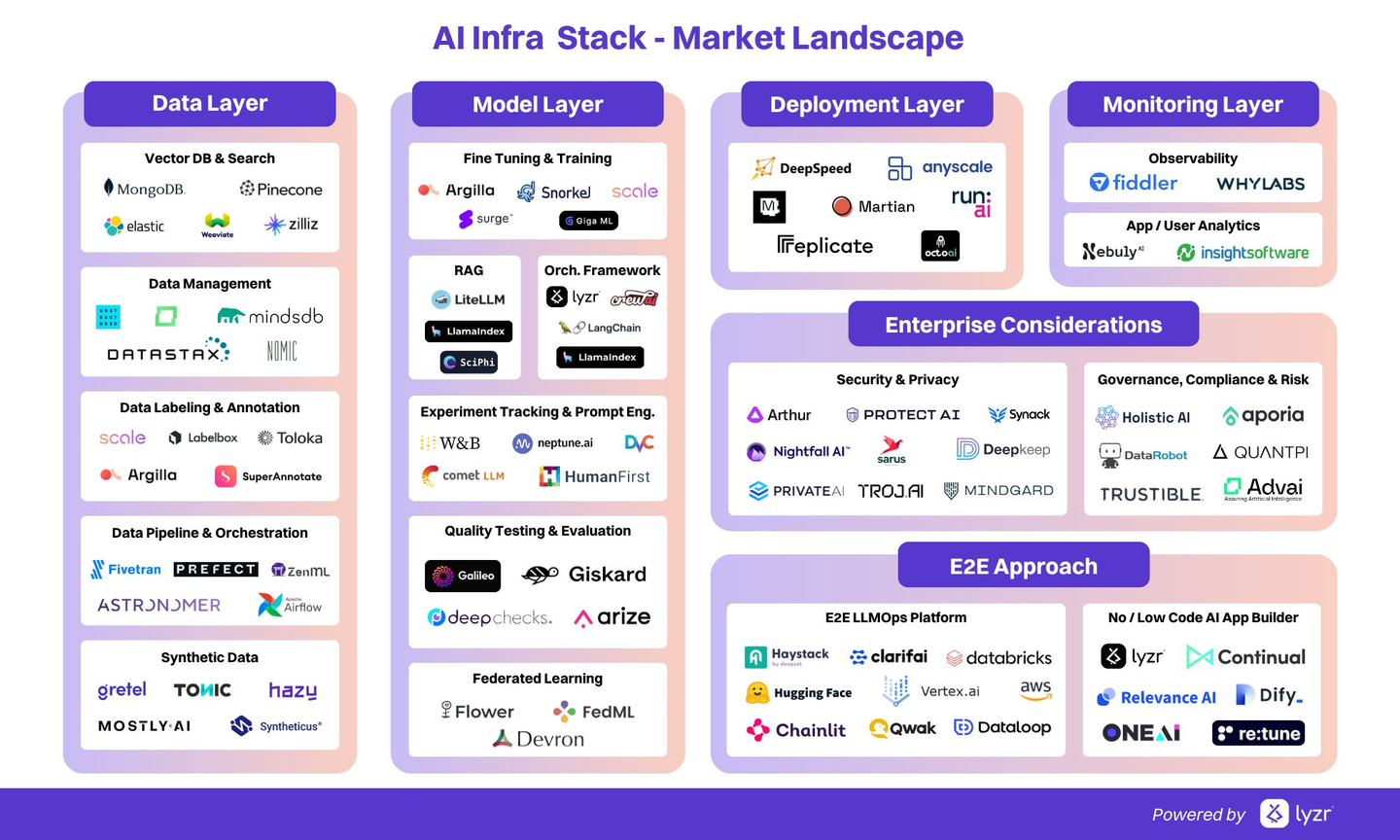
UC Berkeley -CS294: Machine Learning Systems (AI Systems)
- 学校: UC Berkeley
- 课程中内容:本课程由伯克利 RISELab 开设,介绍支撑新一代 AI 应用的最新系统设计趋势,以及利用 AI 改进计算机系统的前沿应用。课程首先讨论各种硬件和软件 ML 系统(包括 GPU 及 TPU 等新型加速器硬件,以及 Theano、TensorFlow、PyTorch、MXNet、Horovod、Ray 等开源 ML 系统框架)如何让越来越复杂的模型在海量数据上进行训练,并简化模型开发流程。随后探讨 AI 反哺系统 的案例,例如将 ML/RL 应用于硬件设计、作业调度、程序优化等系统问题。上课形式为讲座与研讨相结合,学生需阅读论文并完成实践项目。课程主题包括:大数据系统架构(如Spark 数据流水线)、深度学习硬件设计、分布式深度学习(含 Microsoft DeepSpeed 案例)、AutoML 和 ML 模型优化等。
- 与 AI infra 的关系: 该课程覆盖了 AI 基础设施广泛的层面:既包括支持大规模模型训练的系统架构(硬件加速器、分布式训练框架、大数据处理平台等),也讨论机器学习对系统优化的应用。学生将了解诸如分布式训练系统、模型部署框架、大规模数据处理与存储(数据湖、Spark 等)、以及硬件加速和自动优化等 AI 基础设施核心议题。
Cornell — CS 4787/5777 Principles of Large-Scale Machine Learning Systems (FA25)
- 学校:康奈尔大学计算机科学系
- 课程中内容:大规模 ML 中的优化:随机梯度下降(SGD)、小批量训练、加速 / 自适应学习率、超参数搜索; 并行与分布式训练:数据并行、参数服务器、通信开销; 量化与模型压缩:低比特权重、剪枝、蒸馏、稀疏化 ; 高效推理:如何让模型在实际系统里“算得快、占得少” 。
- 与 AI infra 的关系: 把“优化算法视角”和“系统实现视角”打通:从 SGD 数学式到 mini-batch kernel,到多 GPU 分布式训练; 量化、压缩、并行训练这些主题,就是当前 训练平台 / 推理集群 的核心技术; 更偏“算法驱动的 MLSys 基础课”:适合作为你以后读 MLSys 论文、做 LLM 训练/蒸馏/服务的理论+直觉底座。
Purdue — CS 59200-MLS Machine Learning Systems (Fall 2025, 研究生)
- 学校:普渡大学计算机科学系
- 课程中内容: 以 LLM 等生成式模型为核心案例,教“高层 ML 程序如何被拆成低层 kernel 并在 GPU 集群上执行”: 神经网络与反向传播;自动微分与计算图;深度学习加速器(GPU / 专用芯片); 分布式训练(数据并行、模型并行、通信优化) ;kernel 自动生成、算子编译、内存优化等 。
- 与 AI infra 的关系: 课程核心就是现代 ML 框架 ↔ 硬件 之间的那层“系统胶水”:计算图编译、kernel 调度、异构加速器协同。项目通常是 真·MLSys 研究:比如实现一个新型 kernel 优化、自动并行策略或内存调度策略,可以直接投 MLSys/OSDI/NSDI 风格的方向。 是典型的“AI infra 内核开发视角”课程,比普通 ML 课更接近你真实在写的 runtime / compiler。
Brown — CSCI 1390 Systems for Machine Learning (Spring 2025)
- 学校: 布朗大学计算机科学系
- 课程中内容:解决大规模 ML / 数据处理系统中的 延迟、吞吐和硬件效率 问题。 主题:高效训练与推理、GPU 编程与 CUDA、Transformer 架构与 KV cache、MoE、量化、向量数据库与检索、集群调度、ML 编译器(如 XLA/TVM 等)。 项目: Project 1 – Parallelism(数据并行 / 模型并行) ; Project 2 – Attention & KV Caching ;Project 3 – Cuda Kernels ; Project 4 – Vector Databases 。
- 与 AI infra 的关系:实打实地让学生上手 GPU kernel、集群调度、向量检索后端,体感“AI 服务”整条链路。 很适合作为 LLM 推理后端 / embedding 检索 / GPU kernel 优化 的“带项目训练营”。 如果你在看 FlashAttention、PagedAttention、各种 KV cache 优化,这门课几乎是一条线讲过去的。
MIT – 6.5930 / 6.5931 Hardware Architecture for Deep Learning
- 学校:MIT EECS (2024年lecture)
- 课程中内容: 深度学习计算本质:矩阵乘、卷积、张量运算( i. 硬件架构: GPU、AI 专用芯片里的 systolic array(阵列矩阵乘);量 / 张量指令(比如 “一条指令算一整行向量”)ii. 性能与能耗:算力(FLOPS)怎么量化;数据搬运占了多少能量(HBM、cache、片上 SRAM); iii. 算法与硬件协同: 量化、剪枝、稀疏化怎么减少访存、提高吞吐。 )。
- 在 AI Infra 中的层次与关系: 主要层级:硬件层(accelerator 设计) + 系统/框架层(如何把 DL kernel 映射到硬件);站在芯片 + 微架构视角理解 “为什么 LLM 推理/训练这么吃显存和带宽”,和 “为什么有时算力够但被内存拖死”。给 PyTorch/XLA 这类框架提供算子实现与性能模型,影响芯片指令集、on-chip 网络、SRAM/HBM 配置。
Stanford – CS229S Systems for Machine Learning
- 学校:Stanford Systems for Machine Learning – 斯坦福大学(研究生课程)
- 课程中内容 : 立足于 “真实世界部署大规模 ML/LLM 系统” 的问题: 分布式训练:同步/异步、参数服务器、all-reduce ; 在线推理服务:延迟、吞吐、Autoscaling ; LLM/推荐系统等典型 workload 的系统设计 。 本课程聚焦深度学习系统的性能效率和可扩展性,重点讨论如何优化大型模型(尤其是Transformer架构和LLM)的训练和推理效率。课程涵盖高效模型训练、微调和推理的方法,包括分布式训练、多节点加速器异构计算等主题。学生通过项目实践 Transformer 语言模型的实现与优化,以及大模型推理加速等。强调硬件—系统—算法 一体化: 如何根据硬件选择并行策略;如何在生产环境里做弹性伸缩、容错。
- 在 AI Infra 中的层次与关系:主要层级:集群/训练 & 推理系统层 + 系统软件层; 直接服务于:多机多卡大模型训练 + 在线大规模推理 的整体架构设计。课程集中于大规模模型训练与服务所需的系统优化,例如分布式训练框架、模型并行与加速、内存/计算优化等,是典型的“训练+系统”方向 AI 基础设施课程。
Cambridge — L46 Principles of Machine Learning Systems(MPhil / Part III, 2025–26)
- 学校 剑桥大学 Computer Laboratory(现 Department of Computer Science and Technology)。
- 课程中内容: ML 系统 landscape:从小规模单机,到移动端,再到数据中心分布式训练。 模型压缩与高效推理:剪枝、量化、蒸馏与硬件映射。 自动微分与“训练内部结构”:计算图、反向传播如何在系统层实现。
- GPU 与 CUDA、硬件加速器:算力、存储层级、算术强度等。 关注“同一个模型从手机到数据中心”的设计权衡(功耗 vs 吞吐)。
- 与 AI infra 的关系:很明确地贯穿 edge–cloud 一体化 ML 系统 的思路: Edge:如何在手机 / 嵌入设备上做模型裁剪、低功耗推理。 Cloud:如何在 GPU/TPU 集群上高效训练与服务大模型。 对于做“端云协同推理 / 模型压缩 / 硬件感知训练”的人,这门课提供的是系统+算法一体的思维框架。
Rochester — CSC 290/420 Machine Learning Systems for Efficient AI (Fall 2025)
- 学校 罗切斯特大学计算机科学系 cs.rochester.edu
- 课程中内容 : Systems:共享内存 vs 分布式内存、数据布局(数组/数值)、CPU/GPU 组织结构、各类并行形式与 out-of-order pipeline、多线程与超线程。 Memory & Storage:多级 cache、DMA、预取、一致性、SRAM/DRAM/HBM、虚拟内存与页表、磁盘/SSD/NAS。 Network:网络拓扑、collective 通信。 Programs:DAG 型 ML 编程模型、高性能 kernel 生成(DSL + autotuning)、并行执行与分布式执行、调度与 checkpoint。 Efficiency:性能模型、功耗模型、Amdahl 定律、非冯·诺依曼加速器(TPU、Groq 等)。
- 与 AI infra 的关系: 这是少见的“从硬件与系统底抽筋地讲 ML 性能”的课,专注于: 内存层级与算子性能; 网络与 collective 对分布式训练/推理的影响 非传统加速器(TPU/Groq)对 AI infra 设计的启发 ; 对你理解“为什么 NVLink / HBM / topology 这么重要”非常有帮助,是偏 AI data center / accelerator architecture 的视角。
UIUC — CS 498 Machine Learning System (Spring 2025)
- 学校 伊利诺伊大学香槟分校(UIUC)计算机科学系
- 课程中内容 : 针对现代大模型(Transformer / Diffusion): 分析模型的性能特性(算子 FLOPs、内存、通信) ; 训练与推理的计算 / 内存 / 通信优化 ; 模型压缩与加速(让模型更小更便宜) 。 案例研究: LLM 训练与服务:从 pipeline 设计到系统实现 ; 主流 ML 框架背后的设计 rationale 。 课程包含 open-ended 的研究项目,鼓励你做真正的 MLSys 优化 / 新方法。
- 与 AI infra 的关系: 明确对标 大模型训练+推理 infra: 学性能分析:算子级 profile、瓶颈定位 ; 学系统优化:并行策略、cache locality、I/O、跨 CPU/GPU/存储层的协同 ; 学压缩与框架设计:怎么在现有 DeepSpeed/其他框架上落地优化。 如果你打算做未来的 “LLM 训练/推理平台工程” 或 “MLSys 研究”,这门课是非常典型的训练路线。
UMD — CMSC 828G Systems for Machine Learning / High Performance Systems for AI
- 学校: 马里兰大学 College Park,计算机科学系。
- 课程中内容 : 并行计算原理在 ML 中的应用(数据并行、模型并行、pipeline 并行等) ; 高性能通信与分布式训练(collective、拓扑感知调度) ; GPU/多核 CPU 的高效利用(kernel 优化、内存层级) ;高性能 kernel 编程(例如 Triton kernel)、大规模训练 / 推理任务的加速项目 。项目要求用学到的系统概念去加速某个 ML 工作负载,这是非常典型的 HPC-style course project。
- 与 AI infra 的关系:课程站位是“HPC for AI”:站在高性能计算和并行系统角度看 ML。 对于想做: 大规模训练的 并行策略设计;HPC 集群上 AI 工作负载的性能调优;高性能 kernel / runtime的人,这门课会直接对应到实际的 AI data center & training infra 问题。
Harvard – CS249r / Introduction to Machine Learning Systems
- 学校:Harvard SEAS
- 课程中内容 :“Introduction to Machine Learning Systems” 对应的开源教材 Machine Learning Systems: Principles and Practices of Engineering Artificially Intelligent Systems(2025 年 11 月更新)ML 项目的全生命周期:问题定义 → 数据 → 模型 → 实验管理 → 部署 → 监控; 工程主题: 数据验证 (data validation)、特征存储 (feature store) ; 实验跟踪 (experiment tracking);部署策略(灰度发布、影子部署 (shadow) 、A/B test ); 可靠性:可重现性、回滚、技术债; 材料在 2025-09/11 大幅更新,强调 LLM/RAG 时代的 MLOps 实践。
- 在 AI Infra 中的层次与关系:主要层级:MLOps/工程层 + 系统/框架层; 是一个“把 ML 项目当工程系统建”的课程:业务需求、产品; 云 infra、数据平台、容器编排等。
UC San Diego – CSE 234: Data Systems for Machine Learning(Winter 2025)
- 学校:UC San Diego
- 课程中内容: 深入 GPU 与 CUDA、张量格式和矩阵乘运算,并通过阅读 GPU 性能和 MI300X vs H100 的文章来理解加速器的算力、带宽和瓶颈。 算子编译与图优化,系统介绍 Triton、TVM 以及深度学习编译器,讲如何自动生成高性能 kernel、做算子融合和计算图重写。讨论“Memory”,围绕激活和参数的显存占用、重计算等主题,强调内存管理对大模型训练规模和速度的决定性影响。并行化与 collective 通信,从并行化总览到数据并行、模型并行、流水线并行,再到 inter-op / intra-op 并行等高级主题。Transformer 和注意力结构,并结合 GPT-3、Chinchilla scaling law 等论文来说明大模型 scaling 与算力、数据关系。课程中既有单独的量化专题,又在 LLM 系统部分重点讲 FlashAttention、Paged Attention、continuous batching、disaggregated prefill & decoding 以及 Orca、Speculative Decoding、DistServe、Eagle 等前沿推理技术。
- 与 AI infra 的关系:它几乎覆盖了 AI infra 的核心技术栈:加速器与显存带宽(GPU/MI300X)、算子与编译器(TVM/Triton/TASO)、分布式训练与并行策略(Megatron/GPipe/Alpa)、以及 LLM 推理系统(FlashAttention、Paged Attention、continuous batching、disaggregated prefill+decode 等)。
HKUST – Advanced Large-Scale Machine Learning Systems for Foundation Models
- 学校:香港科技大学 HKUST(CSE 系)
- 课程中内容: 梯度下降与自动微分(Gradient Descent & Autodiff); 现代 ML 系统框架如何工作(以 PyTorch 为代表); Nvidia GPU 计算与通信的基本机制。 大模型训练并行: 大规模预训练流程总览(Large-Scale Pretrain Overview); 各类并行策略:数据并行、流水线并行、张量/模型并行、优化器并行、序列并行、MoE 并行等; 推理与部署: 生成式推理总览(Generative Inference Overview); 面向延迟的推理:拆分 + 低精度压缩(Disaggregation & low-precision compression); 面向吞吐的推理:大规模 batching、offloading 策略; 现实世界中的 FM / LLM 部署案例、研究汇报和计划(学生展示)。
- 与 AI infra 的关系: 课程几乎就是“FM/LLM 训练 + 推理的系统基础设施”: 从单机 GPU 到多 GPU / 多节点集群的并行范式全覆盖; 针对 FM/LLM 训练、推理的 性能瓶颈分析(算子、显存、网络、通信); 讲解如何用数据/模型/管线/序列/MoE 等多种并行组合设计大规模训练集群; 部署环节讨论低精度、分布式 KV cache、disaggregation 等典型 LLM infra 课题。 如果你在搭建或研究「训练 GPT/DeepSeek 这种超大模型的集群」,这门课就是站在 系统层 + 集群层 + 硬件层 来教你如何把算力、网络、内存真正“组织起来”服务 FM/LLM 工作负载。
NUS – CS6216 Advanced Topics in Machine Learning 2025 (Systems)
- 学校:NUS School of Computing,CS6216 Advanced Topics in Machine Learning (Systems)
- 课程中内容:云上的训练/推理系统设计;数据系统与 ML pipeline;LLM 后训练(对齐、蒸馏)与系统支持。
- 在 AI Infra 中的层次与关系:集群/云训练 & 推理层 + 数据/平台层;更偏“研究+工程前沿”,贴近云厂商/大厂 ML infra 的逻辑。

















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









