




引言
面向“机器人 × 机器学习”交叉的旗舰型会议之一的CoRL 2025(Conference on Robot Learning)定于 2025 年 9 月 27–30 日在韩国首尔举行(在 Google Scholar Metrics(Robotics 类) 中,CoRL 与 RA-L、ICRA 等并列位居前列,体现出稳健的学术可见度与引用表现)。今年与 IEEE-RAS Humanoids 2025 同馆同周联办,形成“机器人学习 + 人形机器人”的组合场景,便于学术与产业在同一平台上交流与展示。官方日程安排为:9 月 27 日为工作坊,9 月 28–30 日为主会议程;CoRL 2025主题包含 Manipulation、Perception、Planning & Safety、Locomotion、Humanoid & Hardware 等。

Seoul, Korea
截至本文时点,官方虽然尚未在站内给出 2025 年的总投稿量与接收率,但是可以估算出:接收论文数755篇(主会):≈ 270 篇,总体接收率:≈ 35.7%【斯坦福相关研究者个人页写明 35.77%,另有作者在 LinkedIn 公告称 35.7%。两者数值一致】,(由上两项推算的)投稿总量:≈ 755 篇(按 270/35.77% 计算,四舍五入))
已公布“Award Finalists(奖项入围名单),这些paper无疑是最值得关注的。其中,UCB(伯克利)存在感爆棚:8 个入围里,至少 4 个与 UCB 关联:VideoMimic、MultiGen(作者群含 Darrell/Abbeel等)、DSRL(署名含 UC Berkeley)、π₀․₅(合作者名单含 Sergey Levine)。这既反映了伯克利在“视频→人形”“多模态仿真”“部署后适应”“通用 VLA”四条主线上长期深耕。

Who are they ?
另外,π₀․₅ 由 Physical Intelligence 牵头,联合学术大牛(如 Finn/Levine)与产业作者(如 Hausman、Springenberg 等),产学协同范式鲜明。我国的研究机构BIGAI/BUPT做“无力传感下的统一位置/力的控制”,MIT/ETH/Autodesk 做“双臂装配”,Pathak 团队主打“通才运动”,斯坦福阵营在 DexUMI 上给“灵巧操作数据采集”提供了漂亮解法。
为此本文详实解析一下这些入围的论文,按照问题,解决思路(对比已有方法或模型),创新点的直觉思考及潜在价值与应用等维度去分析。
批注:ICRA/IROS:覆盖面最广的综合机器人学会议;方法、系统与应用全面,规模最大。CoRL:把“学习方法 + 真实机器人验证/落地”作为主线,审稿指引明确要求评审具备机器人学习与机器学习双重背景;目标是“选择性强的顶级会议”。RSS(Robotics: Science and Systems)与 CoRL在“强调研究前沿、选题聚焦、单点质量”上相似;CoRL 的区别在于更强的 ML 社群链接与开放出版传统(PMLR/OpenReview)。
Learning Unified Force and Position Control for Legged Loco-Manipulation
Learning Unified Force and Position Control for Legged Loco-Manipulation
Peiyuan Zhi1,∗, Peiyang Li1,2,∗, Jianqin Yin2, Baoxiong Jia1,†, Siyuan Huang1,†1 State Key Laboratory of General Artificial Intelligence, Beijing Institute for General Artificial Intelligence (BIGAI)2 Beijing University of Posts and Telecommunications
https://unified-force.github.io/
1) 文章要解决什么问题?
问题本质:腿足+机械臂的“行走—操作一体化”(loco-manipulation)往往是接触密集的:既要到位(位置/速度跟踪),又要合力(接触/外力调节与顺应)。既有视觉运动策略多聚焦位置或力单一路径,很少在一个统一策略里共同学习两者;同时真实硬件上缺少力传感器,导致数据集与模仿学习多只含轨迹而缺“接触信息”,在擦拭、按压开关、推拉抽屉等任务上性能受限。本文要在无外力传感器条件下,用单一策略同时实现位置与力控制,并把“隐式力感知”带进模仿学习数据采集,提高接触场景的成功率(如下图)。
A unified force-position policy for legged robots
2) 解决思路是什么?与既有思路有何不同?
统一控制框架:作者以阻抗控制为形(弹簧—阻尼—质量),将末端/机体在外力、主动力指令与位置指令共同作用下的目标补偿项写出,并对机体速度给出类似的速度目标式,形成“位置—力混合”的统一控制指标。策略网络内置外力估计器,只用历史本体状态估计外力,然后通过位置/速度补偿去实现位置跟踪、力跟踪、顺应与混合模式。整个策略用 RL(Isaac Gym 并行仿真)在随机的力/位指令与扰动组合上训练,两阶段学习先稳定全身到达/行走,再加入力指令与扰动(如下图)。
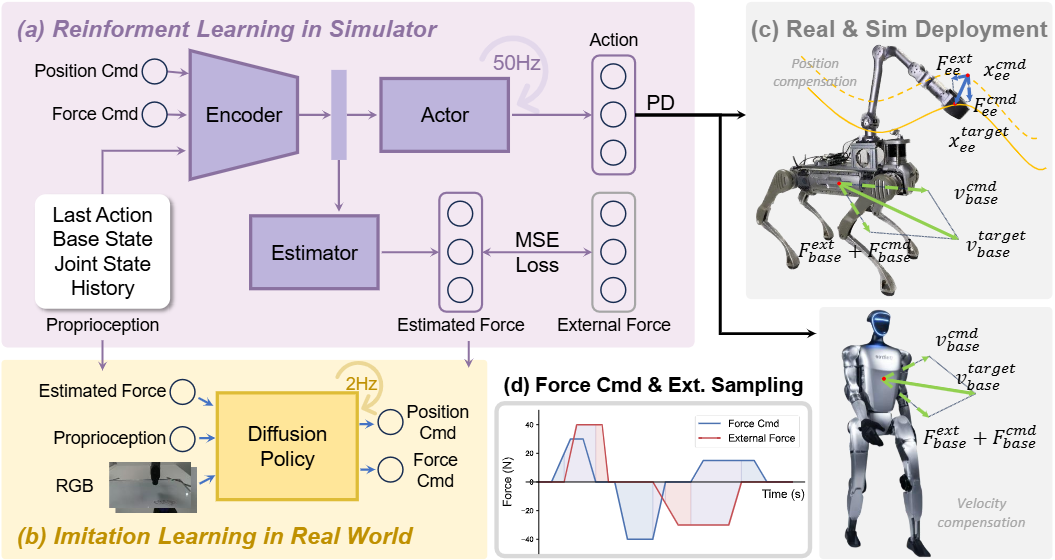
Method Overview
与已有思路的差异参考如下表:
| 方法(年/源) |
核心思路 |
是否用力传感 |
“位+力”是否统一 |
典型平台/任务 |
与本文的主要差异 |
|---|---|---|---|---|---|
| Hybrid Position/Force Control(Raibert & Craig) |
显式通道分解:受限轴做力控制、其余轴做位置 |
常需/依赖环境建模 |
统一否(解耦而非共学) |
经典机械臂接触任务 |
纯模型式;不学习、无隐式估力;不产出可用于示教的数据流。 |
| Impedance Control(Hogan) |
以虚拟弹簧-阻尼调节与环境的交互“顺应性” |
可不强制;多依赖模型/调参 |
部分(力通过阻抗间接体现) |
机械臂/接触调节 |
无统一“位+力”学习策略与估力器;不向上游提供“力感知演示”。 |
| Operational Space Control(Khatib) |
任务空间/零空间分解,受控方向力/位置解耦 |
依赖动力学/接触模型 |
统一否(解耦) |
人形/腿足 WBC |
需高保真模型与接触约束;非学习式、无无传感器估力与数据赋能。 |
| TSID/任务空间逆动力学(Del Prete & Mansard 等) |
QP 优化满足任务/接触/力约束的全身控制 |
依赖模型与接触估计 |
统一否(优化解耦多任务) |
人形/四足全身控制 |
高建模依赖;未在单一策略内共学“位+力”,无力感知示教数据。 |
| Learning Force Control for Legged Manipulation(Portela+ 2024) |
RL 直接学“力控制”,无需力传感,实现顺应/重力补偿 |
否(无力传感) |
偏力向(非显式“位+力”共学) |
四足+臂 全身力控制 |
侧重“学力”,未把位+力在同一策略中联合指令化,也未把估力用于示教数据增益。 |
| FACET(2025) |
RL 模仿阻抗:跟踪虚拟弹簧-阻尼参考,获得可调顺应 |
不强制 |
部分(顺应可调,非显式“位+力”联合) |
四足/人形 全身顺应 |
强调“学阻抗”与冲击鲁棒;未做无传感器估力→上层模仿数据增益这一路闭环。 |
| Learning Visual Quadrupedal Loco-Manip from Demos(IROS 2024) |
视觉示教学习,腿做操作 |
通常无 |
否(以位姿/动作模仿为主) |
视觉引导的腿式操作 |
视觉-行为管线强,但缺力通道;本文补上“估力→补偿→示教力标签”的缺口。 |
3) 创新点的直觉是什么?如何解决问题?
(a) “无传感器力估计”+“统一补偿”的直觉。 直觉上,接触—顺应行为的关键是“感到多大外力并补偿到恰当位姿/速度”(如下图,评估统一力–位置策略的“位置估计/位置跟踪/力跟踪”三方面表现)。若能从历史本体状态(关节/基座姿态、速度、上一步动作等)中回归外力,则可把力看作“隐变量”,统一映射为位置/速度补偿量,从而在同一策略里覆盖位置跟踪、力控制、力跟踪、阻抗/混合模式。这等价于让策略学会“何时像弹簧那样让步,何时像致动器那样顶住”。
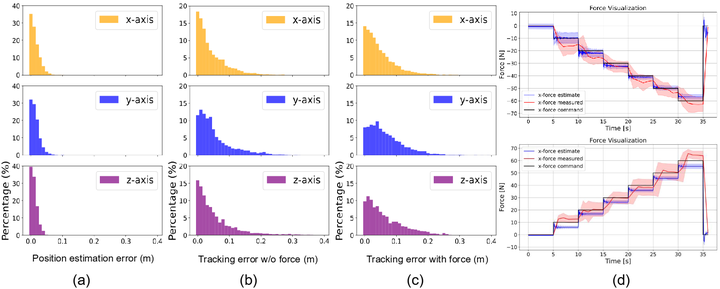
Force and position control evaluation
(b) “力感知演示”的直觉(数据侧)。 多数模仿学习数据只有姿态/图像,缺接触维度。本文用学得的力估计器,在遥操作采集时同步记录(估计的)接触力,把“隐形接触”显式化,让上层扩散式策略输出力+位指令,最终在 4 个接触任务中平均成功率提升约 39.5%。这说明“补上力通道”可以显著缓解仅靠视觉/轨迹造成的触觉不可观测与力阈值不明问题(如按压机关、遮挡下开抽屉,下图为擦白板的实验)。
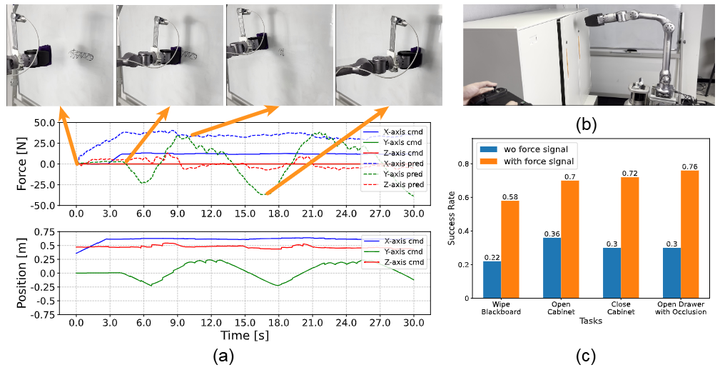
Force-aware imitation learning
(c) 与同类工作的边界。 近期也有用 RL“模仿阻抗”的统一合力控制(如下图 2025 年 FACET,arXiv),但更偏向把策略等效为虚拟弹簧-阻尼以获得“可调顺应”;本文额外强调(i)位置—力在一个低层策略里的共同学习与任务模式自适配,(ii)力感知演示对上层视觉模仿策略的显著收益。两者在接口与数据管线上有所区分。
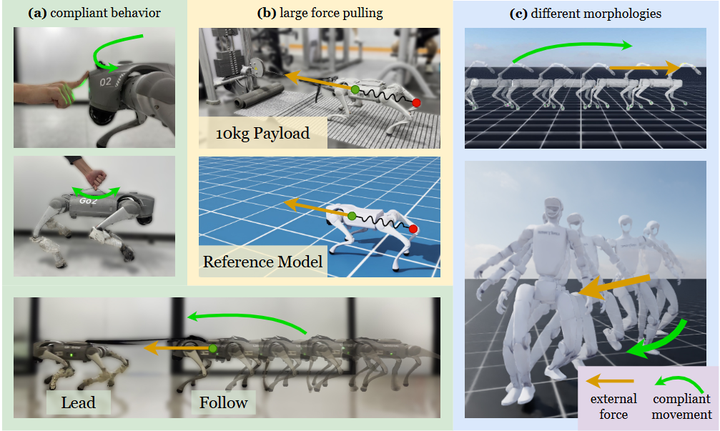
Inspired by impedance control, FACET enables task-space variable compliance and force adaptive control on legged robots by imitating a reference spring-mass-damper mode
4) 潜在价值与应用场景
-
统一低层接口,简化系统集成。同一策略可在位置—力—混合/顺应间按指令切换,为上层(VLA、任务规划)提供稳健、可调的合力接口;对比传统 WBC/混合控制,这种学习式“软阻抗”在跨域/不完美建模时更鲁棒。
-
降低硬件门槛与数据稀缺。无需外置力传感器即可获得“力通道”,并把它注入到模仿学习数据,显著提升接触任务成功率(+~39.5%),对成本敏感平台和遮挡/无纹理环境尤其重要。
-
面向人形/全身交互与工业落地。跨形体验证显示其在人形与四足移动操作间的可迁移性,契合当下“具身大模型/通用机器人”趋势;与近作(如 FACET 的 RL-阻抗、Portela 的学习式力控制)一起,构成学习型顺应控制的产业路径:更安全的人机协作、更稳的装配/擦拭/按压、复杂门/抽屉/弹簧机构操作等。
LocoFormer: Generalist Locomotion via Long-context Adaptation
LocoFormer: Generalist Locomotion via Long-context Adaptation
Min Liu Deepak Pathak Ananye Agarwal Skild AI
1) 文章要解决什么问题(What)
现实中的行走控制器大多是面向单一机体的专用策略:要么依靠精细系统辨识并在狭窄的随机化范围内调参,要么只在几百毫秒的短历史里做“近视”的在线自适应,因此遇到形态差异(双足/四足/轮足)、动力学漂移(负载、摩擦、故障)或极端 OOD 条件时容易失效。LocoFormer的目标是:不需要已知的具体机构学/动力学参数,用同一个低层策略在未见过的多种机体上(含损坏/锁死关节等)实现稳健行走,并且能在多秒甚至跨回合的时间尺度上“用经历来适应”(如下图)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









