




为什么World Model 在Robotics领域中非常重要?
从理论与认知科学角度,Schmidhuber 等人长期主张“智能 = 学会一个可压缩、可预测的世界”;Ha & Schmidhuber 2018 的 World Models 实验证明:仅靠学习到的生成式世界模型,就能在“梦境”中训练策略并成功迁回真实环境,说明内在模拟器本身足以支撑决策。

在强化学习与控制领域,Hafner 的 Dreamer 系列(V1–V4)通过“在世界模型里做 RL”系统性地展示:在 Atari、连续控制乃至跨 150+ 复杂任务上,基于世界模型的 agent 同时取得更高样本效率和更强泛化,最新 Nature 2025工作已超过大量专门算法。
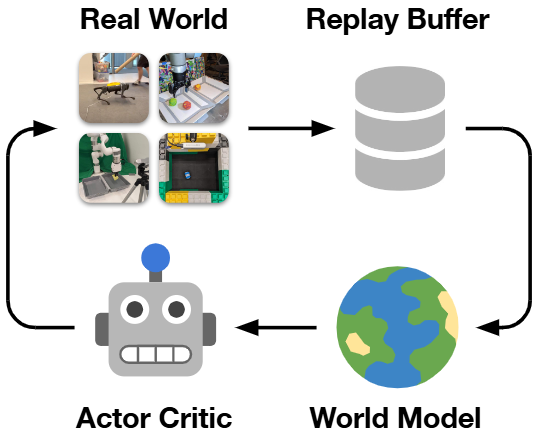
对真实机器人而言,DayDreamer等工作已经在机械臂和移动平台上实证:世界模型可以大幅减少真实交互次数,通过“在模型中想象未来”规避昂贵甚至危险的试错,这是任何要落地的机器人系统都绕不过的安全与成本约束。
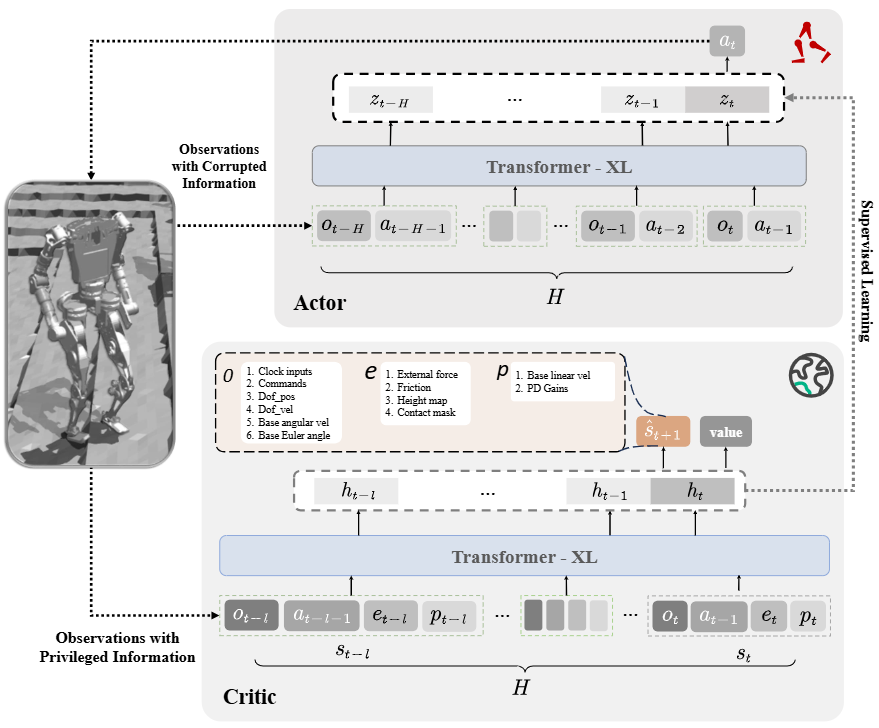
新一代专为机器人设计的世界模型(如 ICLR 2025 的 HuWo、DREMA)将机器人–环境的物理接触、组合技能和“数字孪生”统一到一个可学习模型中,使同一世界表征可复用于行走、操作、模仿学习等多种能力。
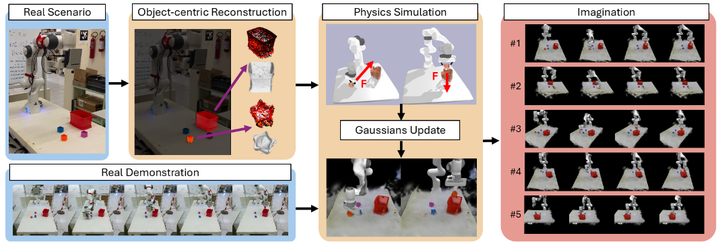
从研究版图看,ICLR 2025 专门设立 “World Models: Understanding, Modelling and Scaling” 与 “Generative Models for Robot Learning” 等工作坊,聚焦 embodied AI、视频世界模型与机器人控制,表明“世界建模”已被视为通往通用机器人与 AGI 的主线之一,而非边缘话题。
同时,在更广泛的 AI 社区,LeCun、Fei-Fei Li 等一线学者及工业界不断强调 world model 是突破纯文本 LLM 局限的关键方向,媒体对 DeepMind Genie 等系统的报道也在强化一个共识:如果没有可靠世界模型,很难获得可信且可行动的智能。 Business Insider

综上,对于追求高样本效率、可解释性、安全性与通用性的机器人系统而言,系统性研究 world model 不再是“锦上添花”,而几乎等价于:这套机器人体系是否具备可扩展的智能潜力。
World Model × Robotics最新论文解读
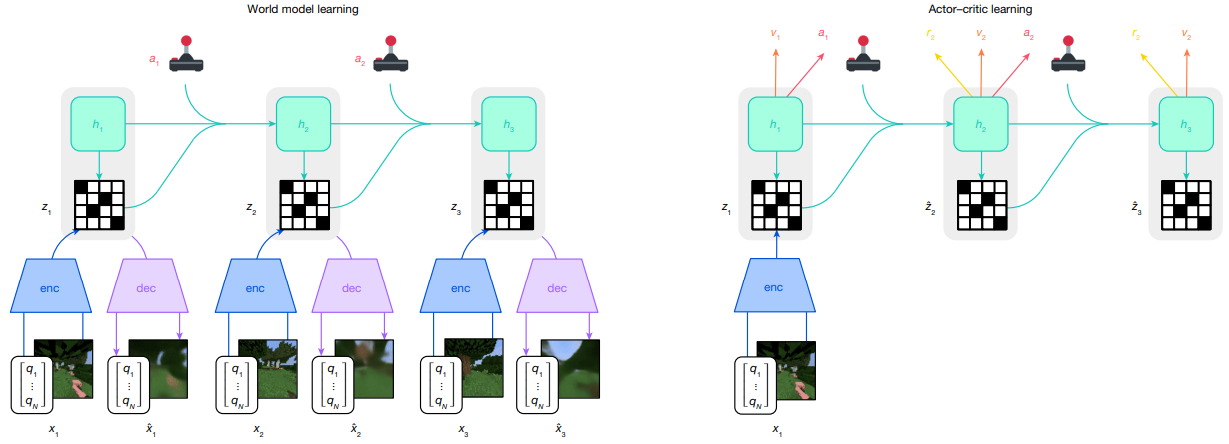
World model 的核心想法,是让机器人先在“脑内模拟器”里预测未来观测与结果,再据此做决策或评估策略——即用一个可微的“环境”取代昂贵、难以建模的真实世界或传统仿真器。最近,这条线出现了几个显著变化:
- 从小模型到视频级生成器:基于 Conditional Diffusion Transformer / Flow Matching 的视频世界模型成为主流,可以在高分辨率视觉上做条件生成与规划,如 Navigation World Models (NWM)、Genie、Vid2World等。
- 从 task-specific 到 foundation-style:如 Unified World Models (UWM)、Humanoid World Models (HWM)、1X World Model,把“大量机器人数据 + 互联网视频”统一进一个 world model 平台,为多任务、多机器人提供基座。
- 更紧地和 RL / VLA 策略耦合:Robotic World Model、GPC、FLARE、RLVR-World等把 world model 看成 RL 的“动态模型 + rollout 引擎 + evaluator”,逐渐实现“训练策略前先炼一个世界”的范式。
已有两篇 最新的survey 对整体格局有系统梳理,非常值得作为背景阅读: A Comprehensive Survey on World Models for Embodied AI,以及聚焦操作任务的 A Step Toward World Models: A Survey on Robotic Manipulation。
下面按四个主题,把代表性论文和发展脉络串起来: 平台 / Foundation World Models for Robotics; Manipulation; Locomotion / Navigation; RL & Policy Adaptation。文章选取举个最新代表性的文章,采样“一段话一个图”的简易解析方式,便于快速浏览或阅读。
平台:World-Model-as-a-Platform & Robot Foundation World Models
这一方向关注的是:能不能有一个通用世界模型当“仿真云”,机器人任务只是在上面做微调 / 规划 / 评估?
通用世界模型与机器人数据的融合
- Genie / Genie Envisioner:
DeepMind 的 Genie 3 系列把大规模视频世界模型做成“环境引擎”;其上的 Genie Envisioner 更进一步,用 action-conditioned video generation 做机器人操作任务的世界模型,并展示了可作为统一基座支撑多种 manipulation 场景。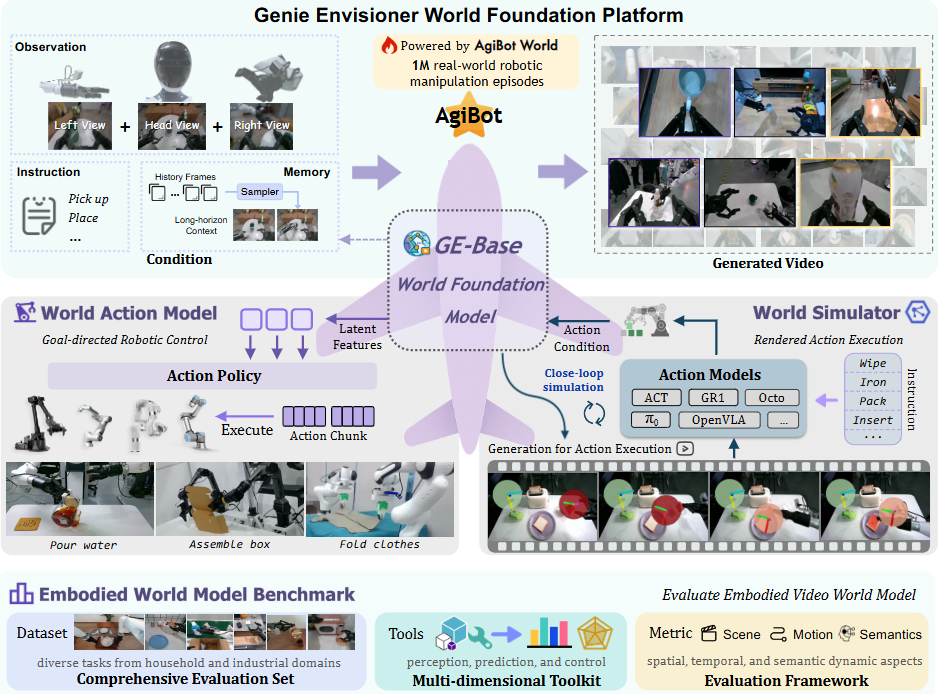
如上图所示,围绕 GE(Genie Envisioner )-Base 世界模型,搭了一个同时支持“想象世界(生成视频)+ 决策行动(控制机器人)+ 标准评测”的完整平台:输入 & GE-Base 世界模型: 多视角相机观察(左/头/右视角)+ 文字指令 + 历史记忆 → 作为条件输入。 这些数据来自 AgiBot World 的 100 万条真实机器人操作轨迹。中间的 GE-Base World Foundation Model 根据这些条件生成未来的视频(右上),相当于在“脑海里”想象接下来会发生什么。两条主线——行动模型 & 世界模拟器: 从 GE-Base 提取的“latent features”生成具体的 Action Policy / Action Chunk,直接控制各种机器人执行任务(倒水、装箱、叠衣服等)。 World Simulator(右中): 用 GE-Base 预测出的世界状态,驱动一个视频级仿真器,渲染机器人执行动作的画面。 这里可以接入不同风格的已有动作模型(ACT、GR1、Octo、OpenVLA 等),形成闭环仿真和执行。 Embodied World Model Benchmark(基准评测): 提供一个包含多种家庭 / 工业操作任务的数据集。提供感知、预测、控制等工具,和场景
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









