







目录
1.业务背景
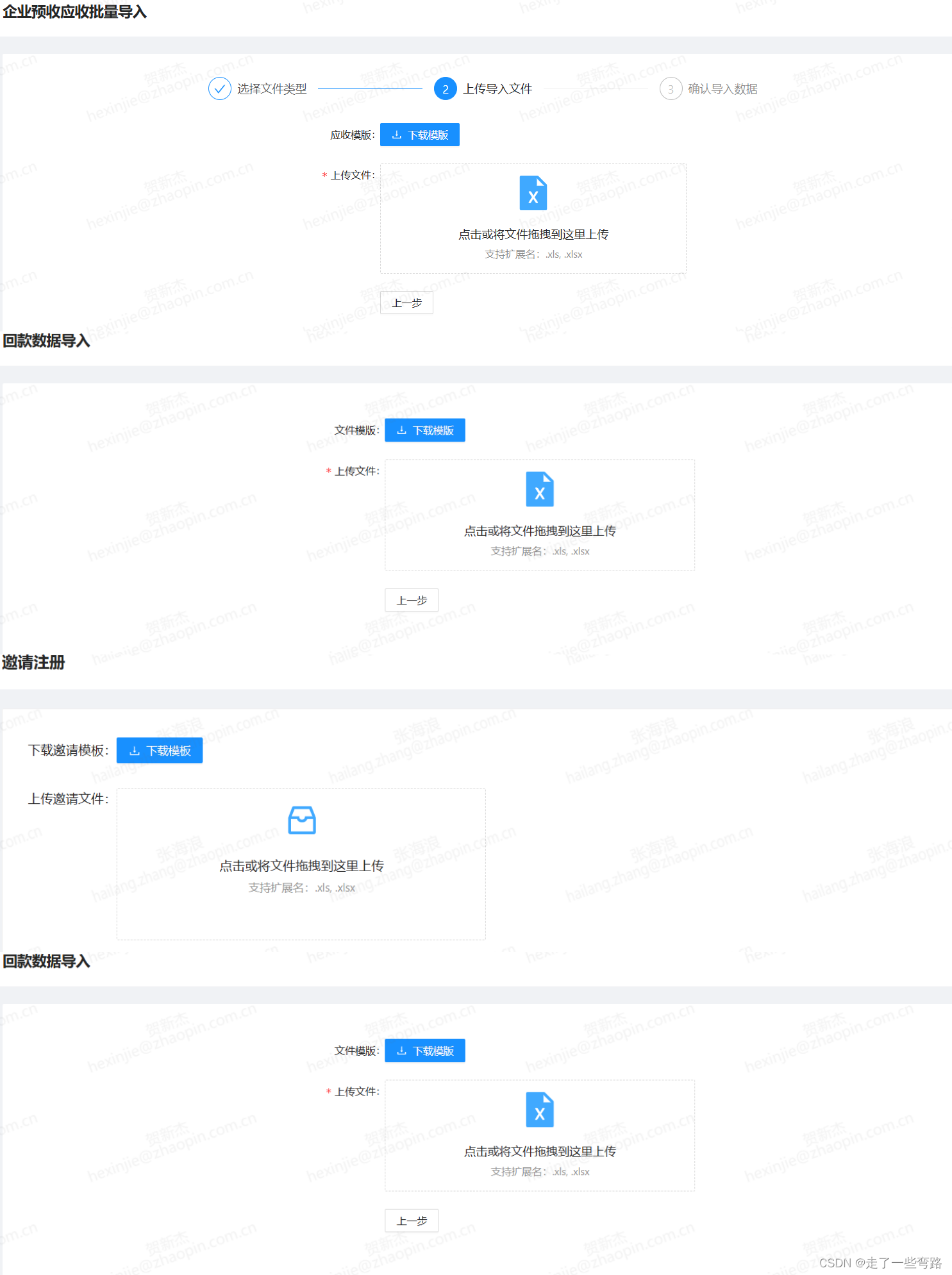
对于一个内部使用的交付系统来说,业务场景大多需要录入数据,时常的导入Excel业务数据是常态,交付人员通过批量的导入业务数据替代页面表单录入,可大幅提升工作效率。
业务的多样性往往也会伴随着个性化的导入Excel逻辑,例如我们的业务系统来说,导入数据场景是最常见的case,而且随着业务的不断发展,场景也在逐步增加。
导入财务数据,导入人员数据,导入众包订单数据,导入外包人员发薪数据等等。导入完毕后需要数据进行校验,然后回显校验结果。
2.业务导入流程
对于我们的业务系统来说,导入数据一般需要以下的步骤:
- 解析Excel
- 校验Excel
- 展示校验结果
- 校验成功后确认导入数据
还需要两类表模型:
1.导入数据的临时表
数据可以多次导入,然后进行校验,只有校验成功的数据才能进入下一步。
2.导入数据的实际业务数据表
导入校验成功后,生成业务数据,如果导入数据有唯一编码,业务数据表只会生成一条
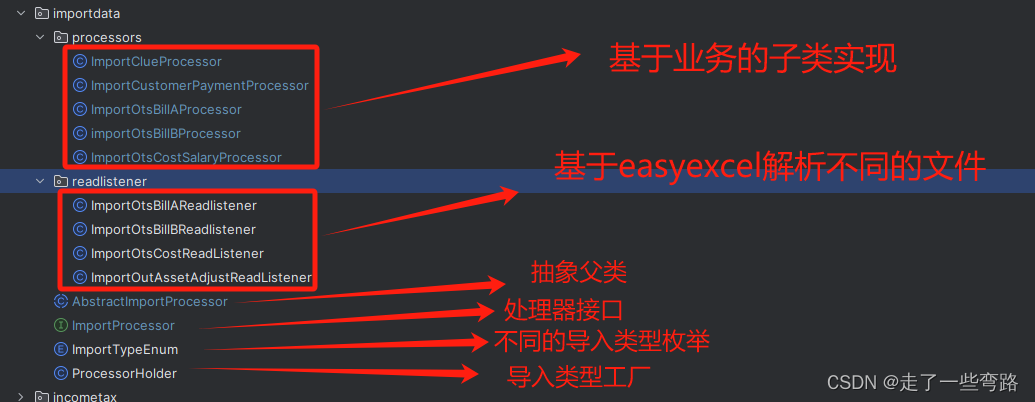
每种业务场景如果都单独写一遍导入流程,再单独建立临时表的话,对于程序员来说无疑是一种折磨。
如何将上述场景流程通用化,当新增导入数据场景时,可以忽略通用部分,只需要聚焦于实际的业务逻辑呢?
3.流程优化
对于复杂的业务场景,如果要做到模块化、低耦合,我理解大部分时候还是需要围绕封装和抽象来进行。
封装不变部分,抽象不变部分来用于后续的拓展。
就本文讨论的业务场景,核心不变的部分是整体的导入流程,无论业务场景怎么多变,数据进入到系统中的如下步骤是固定的。
- 解析Excel
- 校验Excel
- 展示校验结果
- 校验成功后确认导入数据
3.1 模板模式
设计模式中模板模式无疑是解决重复代码的一大利器,应用在当前场景再合适不过了。
主要实现
在父类中定义了算法的骨架,并允许子类在不改变算法结构的前提下重定义算法的某些特定步骤。
设计意图
解决在多个子类中重复实现相同的方法的问题,通过将通用方法抽象到父类中来避免代码重复。
整体代码
通用的临时表模型
所有导入的数据在解析、校验后都会存储到此表中,不同的业务实体转为json后存储在Import_data字段中。
不同的业务表需要根据相应的业务进行创建,此处就不进行展示了。
create table import_data_tmp
(
id bigserial
primary key,
batch_id varchar(50) not null,
operator_id bigint not null,
operation_time timestamp with time zone not null,
line_num bigint,
import_data text not null,
import_result integer,
import_description varchar(500),
create_time timestamp with time zone not null,
update_time timestamp with time zone not null
);
comment on table import_data_tmp is '导入信息临时表';
comment on column import_data_tmp.id is '主键ID';
comment on column import_data_tmp.batch_id is '批次号';
comment on column import_data_tmp.operator_id is '操作人Id';
comment on column import_data_tmp.operation_time is '操作时间';
comment on column import_data_tmp.line_num is '导入文件行号';
comment on column import_data_tmp.import_data is '导入数据';
comment on column import_data_tmp.import_result is '导入结果';
comment on column import_data_tmp.import_description is '导入描述';
comment on column import_data_tmp.create_time is '创建时间';
comment on column import_data_tmp.update_time is '更新时间';
create index import_data_tmp_batch_id
on import_data_tmp (batch_id);
create index import_data_tmp_operator_id
on import_data_tmp (operator_id);
3.1.1 导入处理器接口ImportProcessor
ImportProcessor在此类中,定义抽象父类方法的处理函数ImportResultDTO process(String url, R r);定义一些子类需要自己实现的方法(这些方法也可在抽象父类中定义)。
public interface ImportProcessor<T, R> {
/**
* 核心导入处理流程
* @param url 导入的excel地址
* @param r 请求入参数据
* @return 处理结果
*/
ImportResultDTO process(String url, R r);
/**
* 生成批次号
* @return 批次号
*/
String createBatchId();
/**
* 读取excel数据
* @param r – 请求入参数据
* @return 解析出的数据
*/
List<T> readData(R r);
/**
* 组装需要存储的实体
* @param dataList 解析出的数据
* @param r 请求入参数据
* @return 需要存储的实体
*/
List<ImportDataTmpDO> assembleData(List<T> dataList, R r);
/**
* 导入成功的数据,生成真正的业务数据
* @param batchId 成功的批次号
* @return 导入结果
*/
boolean doImportSuccessData(String batchId);
}
3.1.2 抽象父类 AbstractImportProcessor
核心类AbstractImportProcessor,process方法定义算法骨架,即导入流程。
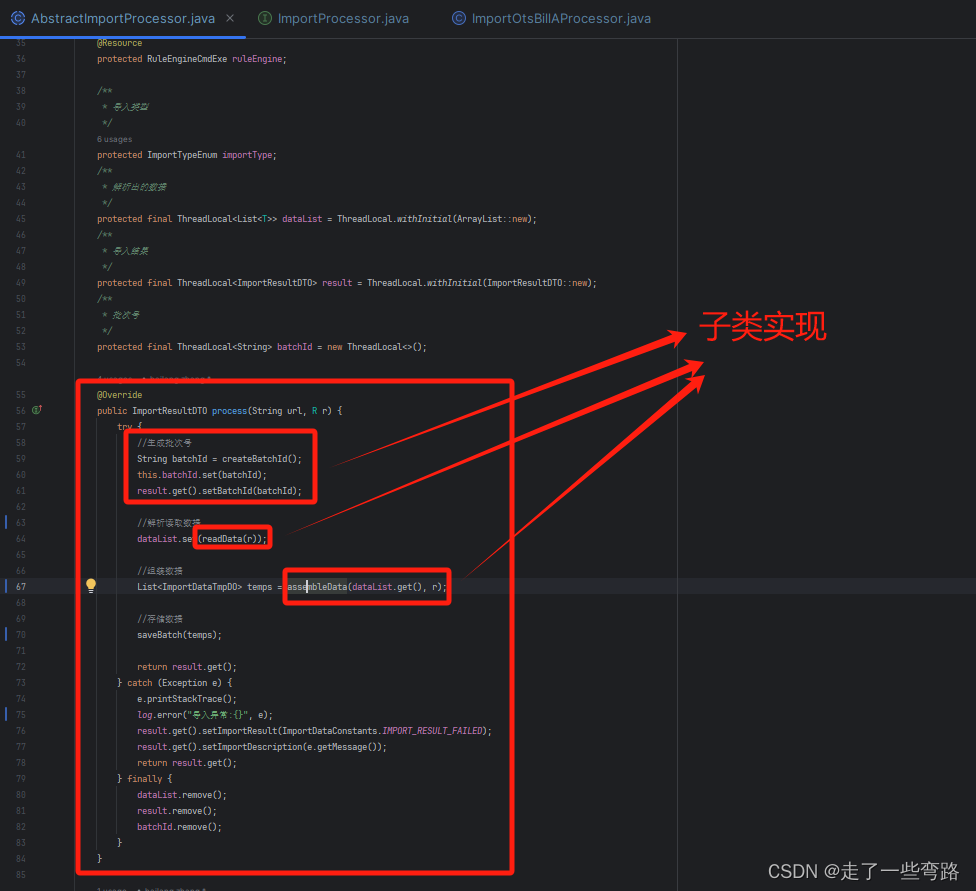
根据不同的业务,子类需要实现的方法。
整体代码如下:
@Component
@Slf4j
public abstract class AbstractImportProcessor<T, R> implements ImportProcessor<T, R> {
@Resource
private ImportDataTmpGateway importGateway;
@Resource
protected DistributeIDGenerator idGenerator;
@Resource
protected RuleEngineCmdExe ruleEngine;
/**
* 导入类型
*/
protected ImportTypeEnum importType 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 190
190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









