




Janus-Pro-1B 模型介绍
Janus-Pro是一种新颖的自回归框架,它统一了多模态的理解和生成。该框架通过将视觉编码分解为独立的路径,解决了以往方法的局限性,同时仍然使用单一的统一Transformer架构进行处理。这种解耦不仅缓解了视觉编码器在理解和生成中的角色冲突,还增强了框架的灵活性。Janus-Pro超越了以往的统一模型,并在性能上与特定任务的模型相当甚至超过它们。Janus-Pro的简洁性、高灵活性和有效性使其成为下一代统一多模态模型的有力候选。
-
github:
-
性能
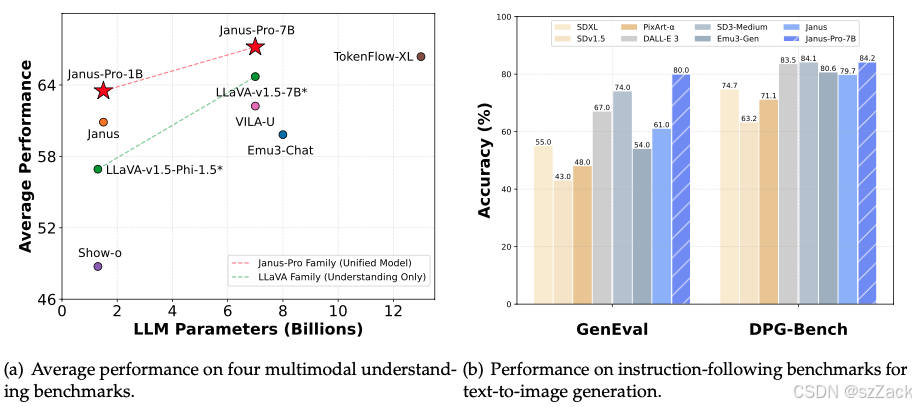
-
生成效果示例

-
Model Summary
Janus-Pro是基于DeepSeek-LLM-1.5b-base构建的。
在多模态理解方面,它使用SigLIP-L作为视觉编码器,支持384×384像素的图像输入。在图像生成方面,Janus-Pro使用了这里的标记器,下采样率为16。 -
发布时间
2025年1月28日
下载
model_id: deepseek-ai/Janus-Pro-1B
下载地址:[https://hf-mirror.com/deepseek-ai/Janus-Pro-1B](https://hf-mirror.com/deepseek-ai/Janus-Pro-1B) 不需要翻墙
运行环境安装
git clone https://github.com/deepseek-ai/Janus
cd Janus
pip install -e . -i https://pypi.mirrors.ustc.edu.cn/simple
模型推理示例
-
Multimodal Understanding
import torch from transformers import AutoModelForCausalLM from janus.models import Mult
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2687
2687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











