



在数字化转型深入推进的当下,企业积累的知识资产(文档、数据、经验等)正成为核心竞争力的关键载体。然而,笔者在服务近百家企业的实践中发现,多数企业仍面临“知识沉睡”“安全失控”“应用脱节”等共性问题——数据分散在OA、CRM、本地服务器等多端,检索效率不足30%;敏感信息在外部工具传输中存在泄露风险;大量结构化与非结构化数据难以转化为业务决策依据。这些痛点背后,本质是“知识管理”与“AI能力”的脱节:企业缺乏一个能整合数据、激活价值、安全可控的智能中枢。
予非・睿知企业AI知识引擎平台正是为解决这一问题而生。作为深度融合DeepSeek等主流大模型的私有化平台,其核心价值在于将“数据仓库”升级为“智慧引擎”,让企业无需从零构建AI能力,即可快速定制贴合业务需求的智能应用。本文将从技术架构、实践路径、集成示例、行业案例四个维度,拆解如何基于该平台落地私有化AI工具链。
一、企业知识管理的核心痛点与行业困境
在深入平台技术前,需先明确企业知识管理的核心矛盾——“数据量大但可用度低”“安全需求高但管控难”“业务需求杂但落地慢”,具体可归纳为四类痛点:
- 数据整合困境:分散、混乱、难检索
企业数据多分散在各部门系统(如研发部的设计文档、人事部的培训资料、销售部的客户案例),跨系统检索需反复切换工具;文件版本频繁更新却缺乏统一管理,员工误用旧版导致工作返工;同时,数据格式涵盖文本、表格、图片、视频等,传统检索工具兼容性不足,近50%的非结构化数据无法被有效识别。 - 安全风险凸显:泄露、误操作、不合规
核心数据(如合同条款、客户信息)通过微信、邮件等外部工具传输时,缺乏加密与审计机制;员工误删除、误共享文件的操作难以追溯;部分行业对数据本地化存储有强制要求,但多数平台无法满足私有化部署与信创适配需求。 - 价值挖掘不足:沉睡数据难转化
企业存储的历史项目文档、客户反馈、行业报告等,仅用于简单统计分析,未深入挖掘关联关系(如“某类客户的投诉多与产品某功能相关”);知识传承依赖“师徒制”,资深员工离职带走关键经验,新员工需3-6个月才能掌握核心业务流程。 - 应用落地缓慢:AI能力与业务脱节
多数企业虽意识到AI的价值,但受限于技术门槛(需算法工程师、开发工程师协同)、成本投入(自建大模型需数百万级预算)、系统适配(难以对接现有OA/ERP),导致AI应用仅停留在“试点阶段”,无法规模化服务业务。
二、予非睿知平台的技术架构与核心能力
予非睿知的核心设计理念是“分层解耦、能力复用、安全可控”,其技术架构从下至上分为“数据层-AI底座-能力层-应用层”四级,确保企业可按需调用能力、快速组装应用。
1.平台技术架构:从数据接入到智能应用的全链路支持

架构的核心是“统一AI底座”,串联数据处理与应用落地,各层功能如下:
- 数据层:多模态接入与安全存储
支持全格式数据接入(文本、图片、音频、视频、结构化数据等),兼容HDFS、OSS、关系数据库、非关系数据库等存储介质;采用云原生架构支撑EB级存储,通过区块链指纹校验、多副本容灾、数据脱敏(如身份证号替换为“****”)保障安全,数据可靠性达99.9999%。 - AI底座:四大引擎驱动智能能力
这是平台的核心技术中枢,包含:
-
- NLP引擎:基于BGE预训练模型实现文本深度语义编码,支持关键词提取、实体识别(如合同中的“甲方”“金额”)、情感分析、文本纠错等,语义相似度匹配准确率达97.2%;
- 大模型引擎:深度集成DeepSeek、通义千问等主流模型,支持本地私有化部署;
- 搜索引擎:采用HNSW层次化索引,支持千万级向量在400ms内检索,动态微调机制将语义漂移率控制在<0.5%/月;
- 图谱引擎:基于Neo4j图数据库构建知识网络,通过GNN实现多源数据自动对齐,支持实体关系抽取、路径推理(如“某项目的负责人→关联客户→历史合作案例”)。
- 能力层:开箱即用的核心功能模块
- 基于AI底座封装四大核心能力,无需二次开发即可直接调用:
-
- 多模态知识库:提供灵活、强大的树状分类功能,支持企业根据自身的业务逻辑和知识脉络,自由搭建多层级的知识目录,能帮助企业构建起一套结构清晰、逻辑严谨、独一无二的专属知识体系;提供强大的智能搜索功能,用户可以通过输入关键词,快速在海量的知识库中进行检索;支持多种筛选和排序方式,帮助用户更精准地定位所需信息支持多种内容展示形式;可以根据自己的偏好,在清晰的“列表视图”、直观的“摘要视图”和美观的“卡片视图”之间自由切换,获得最佳的阅读体验。
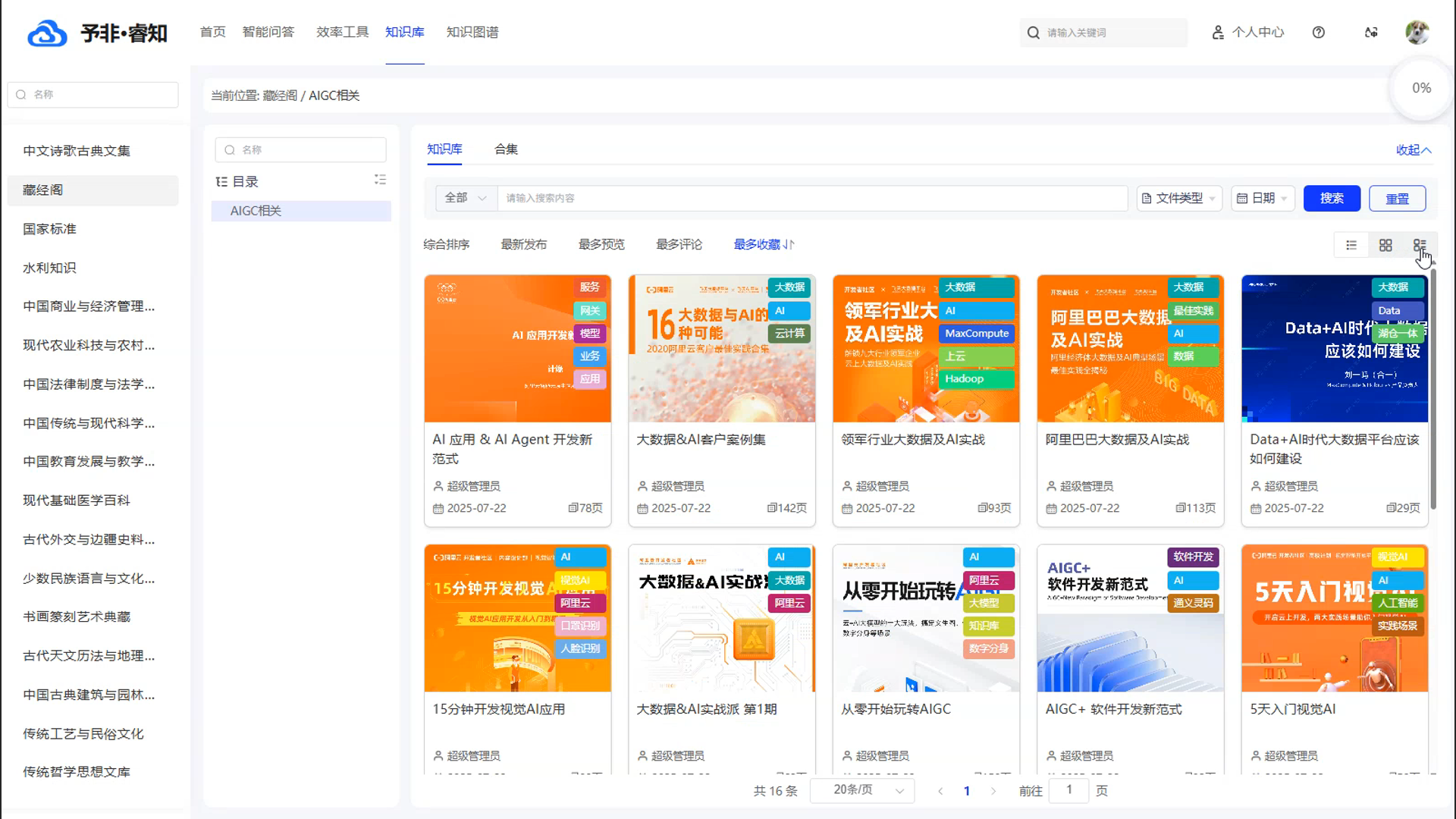
-
- 智能问答:深度融合DeepSeek、通义千问等业界领先的大模型,具备强大的知识理解与推理能力。能够准确识别用户问题的意图,即使是复杂的、口语化的表达,也能提供专家级的精准解答,助力企业进行快速、准确的智能决策;
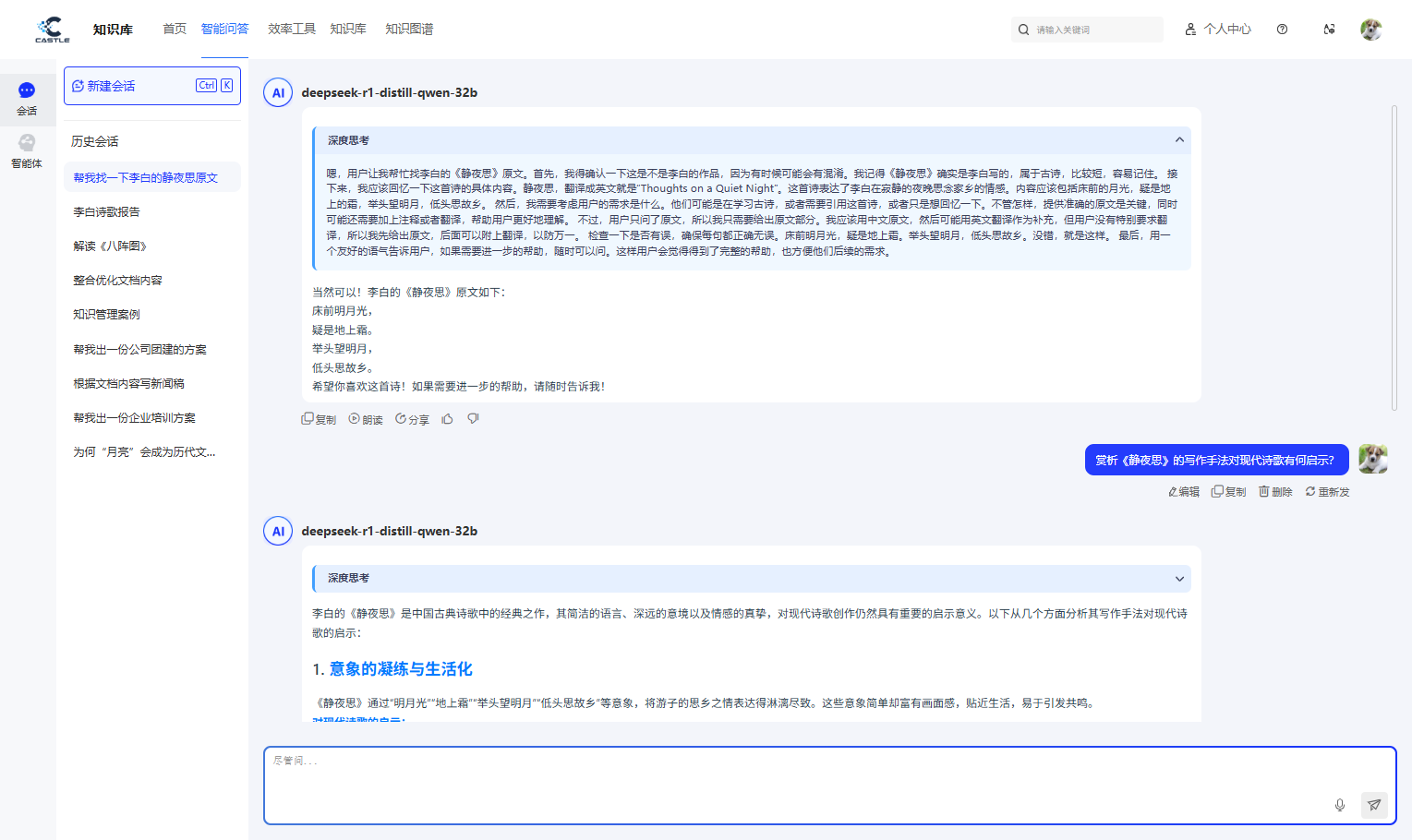
-
- 知识图谱:支持自动化的知识构建与关联,能够自动从海量的非结构化文档中,精准识别并抽取关键实体,智能分析这些实体之间的内在联系,将过去散落在各个角落的信息点连接成一张逻辑清晰、关系明确的知识网络,支持可视化关系探查。
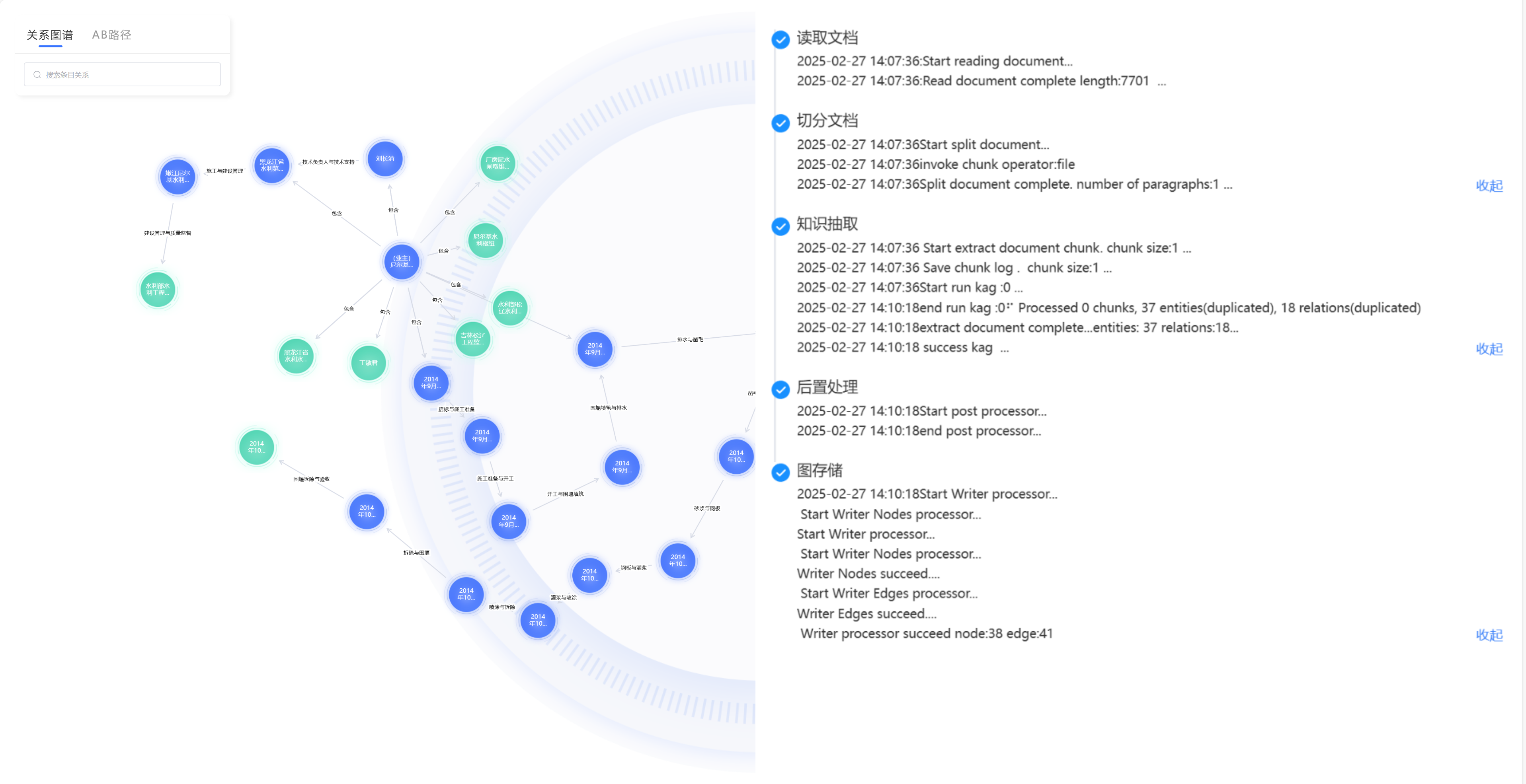
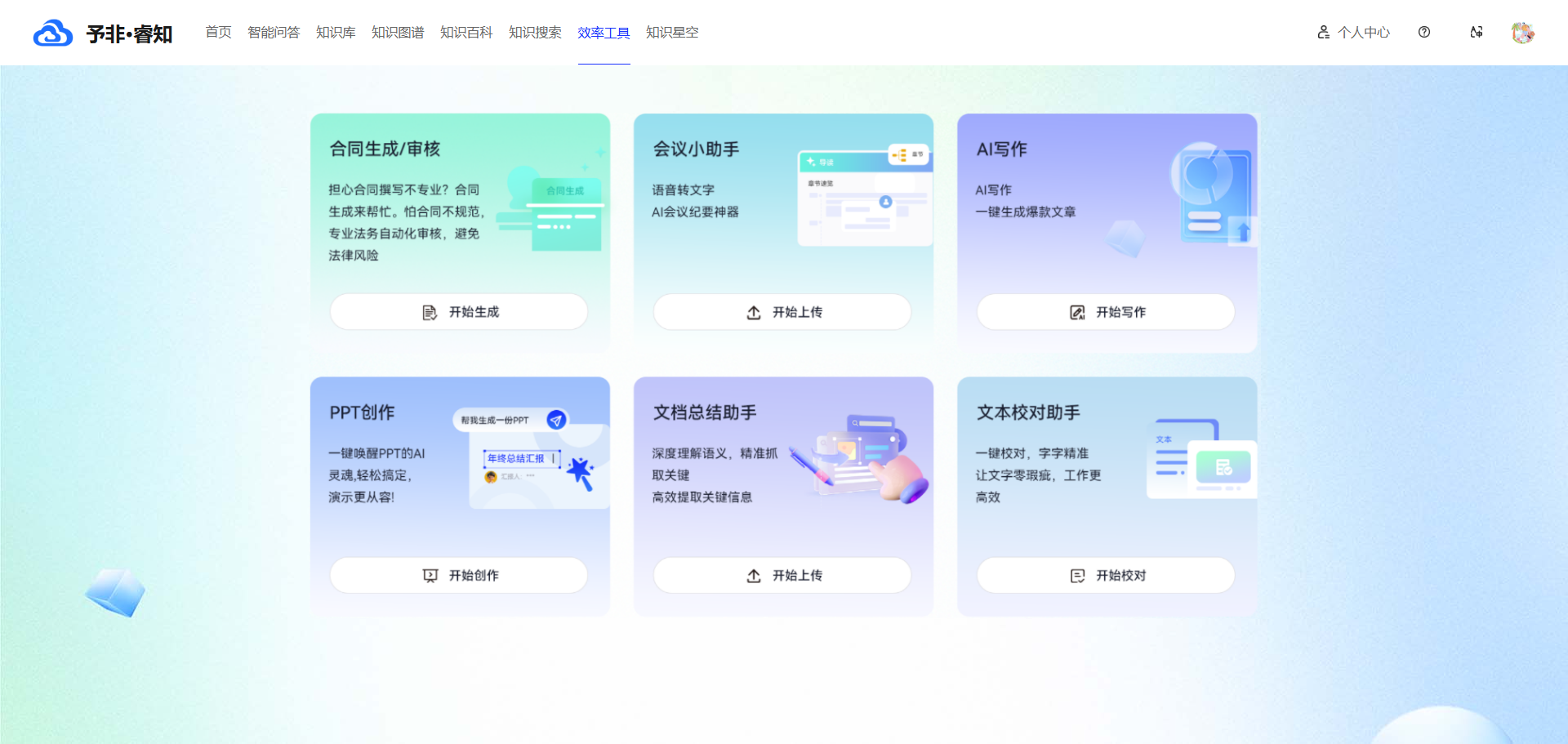
- 应用层:对接业务场景与现有系统
生成智能应用包含PPT创作、会议小助手(语音转文字+纪要生成)、AI写作、合同生成、文本校对等模块化工具,支持私有化定制(如为律所定制“法律文书纠错”功能)。
2.核心能力差异化优势
与通用AI平台相比,予非睿知的核心竞争力集中在三点:
- 全栈私有化:支持内网部署、公网部署两种模式,数据不脱离企业边界,满足政务、金融、医疗等行业的合规要求;
- 主流模型全支持:支持主流所有平台的大模型接入,支持私有化模型,支持模型参数可调可配;
- 国产信创适配:全面兼容国产芯片(中科曙光)、操作系统(麒麟、统信)、数据库(达梦、人大金仓)、中间件(宝兰德、普元),符合国家信创战略要求。
三、基于平台快速定制AI应用的实践路径
企业定制AI工具链的核心是“从业务需求出发,拆解功能模块,复用平台能力”。笔者以“合同审核”为例,拆解落地步骤:
定制“合同审核”(法务/销售部门需求)
需求痛点:销售部签订合同前需法务审核,人工核对条款需1-2小时,且易遗漏风险点(如“付款期限模糊”“违约责任缺失”);同时需对接CRM系统,自动关联客户历史合作记录(如是否有逾期付款记录)。
定制步骤:
- 需求拆解与能力匹配
合同审核需三大功能:文本提取→风险识别→条款比对→结果输出,对应平台能力:
-
- 文本提取:调用多模态知识库的PDF解析能力,提取合同中的甲方、乙方、金额、期限等实体;
- 风险识别:调用NLP引擎的“敏感信息识别”与“规则匹配”功能,预设风险关键词(如“无明确违约责任”“付款期限>90天”);
- 条款比对:调用知识图谱引擎,关联企业标准合同模板,标记差异条款;
- 系统对接:通过平台API接口关联CRM,获取客户历史合作数据。
- 数据准备与配置
-
- 上传数据:将企业标准合同模板、法律法规文档(如《民法典》合同编)、历史风险合同案例上传至私有知识库,开启“版本控制”功能;
- 配置规则:在NLP引擎界面添加“风险识别规则”,如“当合同中出现‘最终解释权归甲方所有’时,标记为‘不公平条款’”;
- 权限设置:仅法务部可修改风险规则,销售部仅拥有“提交审核”“查看结果”权限。
- 工作流编排(零代码)
进入“超级智能体”模块,通过拖拽组件生成审核流程:
[开始]→[上传合同文件(调用文档解析接口)]→[提取合同实体(调用NLP引擎)]→[风险识别(匹配预设规则+关联CRM客户数据)]→[生成审核报告(包含风险点、修改建议、客户历史记录)]→[结束]
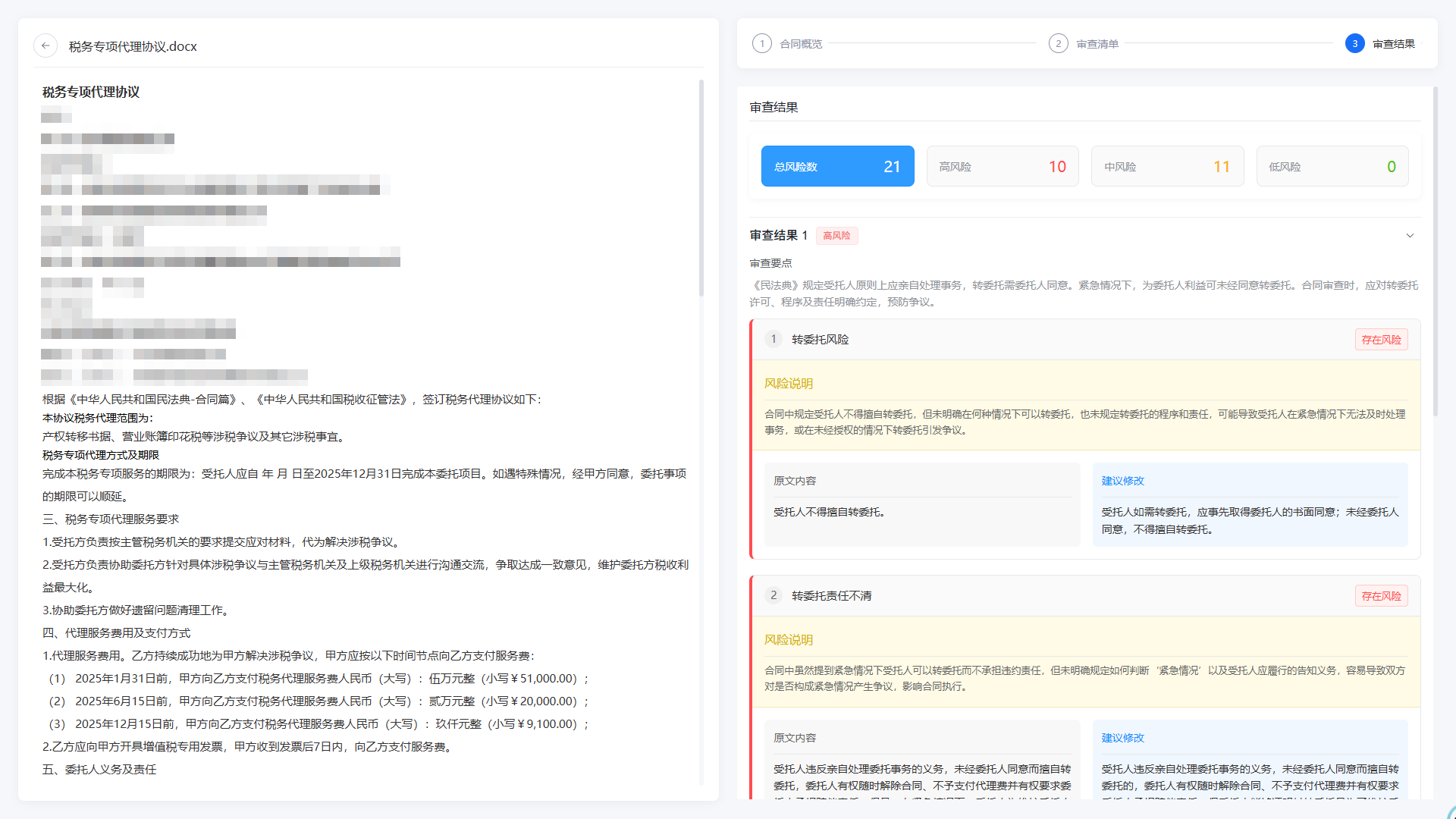
([图5:合同审核工作流编排界面]) - 测试与迭代
上传10份样本合同(含3份高风险合同),验证风险识别准确率(目标>95%);根据测试结果微调规则(如补充“质保期未明确”为风险点),最终将审核时间从1小时缩短至5分钟。
四、企业系统集成示例:RESTAPI调用知识库问答服务
对于有开发能力的企业,予非睿知提供标准化RESTAPI,可快速对接现有系统(如OA、CRM、企业微信)。以下以“在OA系统中嵌入‘知识库问答’功能”为例,提供代码示例(Python),实现“员工在OA中查询企业政策”的需求。
1.集成前提
- 已在予非睿知平台创建“企业政策知识库”(KB_ID:kb-xxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx);
- 已获取平台访问令牌(ACCESS_TOKEN,通过“企业管理-API权限”模块生成,权限范围为“只读知识库”)。
2.代码示例:调用知识库问答接口
importrequests
importjson
#1.接口配置(私有化部署后替换为企业内网地址)
API_URL="https://your-private-ruizhi-platform.com/api/v1/knowledgebase/qa"
ACCESS_TOKEN="eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.xxxxxx"#企业私有令牌
KB_ID="kb-xxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"#政策知识库ID
defget_policy_answer(question):
"""
调用知识库问答接口,查询企业政策
:paramquestion:员工问题(如“出差住宿标准是多少?”)
:return:问答结果(含答案、来源文档、置信度)
"""
#2.构造请求头与参数
headers={
"Authorization":f"Bearer{ACCESS_TOKEN}",
"Content-Type":"application/json;charset=UTF-8"
}
payload={
"knowledgebase_id":KB_ID,
"question":question,
"top_k":2,#返回TOP2相关答案(避免单答案偏差)
"with_context":True,#返回答案对应的文档上下文(便于员工溯源)
"with_confidence":True#返回答案置信度(用于筛选高可信度结果)
}
#3.发送请求并处理响应
try:
response=requests.post(API_URL,headers=headers,data=json.dumps(payload),timeout=10)
response.raise_for_status()#抛出HTTP错误(如401权限不足、404知识库不存在)
result=response.json()
ifresult["success"]:
returnformat_answer(result["data"])#格式化结果
else:
returnf"查询失败:{result['message']}"
exceptExceptionase:
returnf"接口调用异常:{str(e)}"
defformat_answer(answer_list):
"""格式化问答结果,便于OA界面展示"""
format_str="企业政策查询结果:\n"
foridx,answerinenumerate(answer_list,1):
ifanswer["confidence"]<0.6:#过滤低置信度结果(<60%)
continue
format_str+=f"{idx}.答案:{answer['content']}\n"
format_str+=f"来源:{answer['source']['document_name']}(第{answer['source']['page']}页)\n"
format_str+=f"置信度:{answer['confidence']:.2%}\n\n"
returnformat_striflen(format_str)>20else"未查询到相关政策,请联系行政部补充"
#4.示例:查询“出差住宿标准”
if__name__=="__main__":
question="2024年企业员工出差住宿标准是多少?一线城市和二线城市有区别吗?"
answer=get_policy_answer(question)
print(answer)
3.集成效果
将上述函数嵌入OA系统的“政策查询”模块:
- 员工在OA中输入问题(如“出差补贴怎么申请?”),点击“查询”后,OA调用接口获取答案;
- 答案展示时包含“来源文档”与“置信度”,员工可点击来源文档查看完整政策;
- 若答案置信度<60%,自动提示“联系行政部补充”,避免误导。
五、总结与实践建议
在AI技术快速迭代的今天,企业无需追求“大而全”的自建AI体系,而是应聚焦“业务价值”,通过私有化平台复用成熟能力,快速定制工具链。基于予非睿知平台的实践经验,笔者建议:
- 从“单一痛点”切入:避免一开始就落地复杂场景(如全业务链智能决策),可先解决“知识检索效率低”“会议纪要耗时”等具体问题,验证价值后再逐步扩展;
- 重视“数据准备”:AI应用的效果依赖数据质量,建议先梳理企业核心知识资产(如标准流程、历史案例、行业法规),确保数据结构化后再上传平台;
- 平衡“技术自主”与“效率”:非技术团队可优先使用零代码工具(如工作流编排、模板应用),技术团队可通过API对接现有系统,最大化复用企业既有IT架构;
- 关注“安全与合规”:对于政务、金融、医疗等行业,需优先确认平台的私有化部署能力与信创适配性,避免数据合规风险。
未来,随着大模型与知识图谱的深度融合,企业AI工具链将从“单一功能应用”升级为“全链路智能协同”。予非睿知平台的价值,正是为企业提供一个“可生长”的智能中枢——无论是今天的合同审核、会议纪要,还是未来的智能审批、客户洞察,都能在此基础上快速落地,让AI真正服务于业务增长。


















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









