



一、序章:当技术债演变成“知识债”
对于每一个技术管理者和开发者来说,“技术债”是个再熟悉不过的名词。但今天,我想聊一种更隐蔽、破坏力却同样惊人的债务——“知识债”。
想象一下你的团队是否正面临这些场景:
- API文档地狱:一个核心服务的API文档,散落在Git仓库的Markdown和某些资深工程师的本地笔记里。新人调用时,不得不像侦探一样,在多个信息源之间交叉验证,祈祷自己找到的是最新版本。
- 新兵训练营的黑洞:新来的后端工程师,需要花费数周时间才能理清公司微服务架构的脉络。在此期间,他会不断打断高级工程师的工作,反复询问那些“本该有文档”的基础问题。
- 午夜的On-call惊魂:生产环境告警,值班工程师需要快速定位问题。但他必须手动翻阅Jenkins的部署日志、在Grafana上费力地关联指标、再去Confluence上找那篇不知是否过期的应急预案。这个过程的每一秒,都在增加着MTTR。
当团队规模尚小时,这些问题可以通过口口相传来弥补。但当团队扩张到百人以上,这种“知识债”就会集中爆发,形成巨大的“信息内耗”,成为制约团队战斗力的核心瓶颈。
我们今天要分享的,就是如何利用AI技术,偿还“知识债”,并最终实现“弯道超车”。
二、破局:我们的目标——构建一个开发团队的“第二大脑”
面对日益严重的“知识债”,就要构建一个真正服务于开发团队的“第二大脑”。这个大脑的核心目标有三:
- 权威性:所有技术知识,无论格式,都有一个统一的入口。
- 即时性:能听懂开发者的自然语言提问,并直接给出精准答案,而非一堆文档链接。
- 关联性:能揭示知识之间的深层联系,比如某个服务和哪个数据库关联,负责人是谁。
三、技术架构揭秘:这个“大脑”是如何思考的?
整个系统的核心,可以概括为一套“知识图谱”与“检索增强生成”双引擎驱动的架构。

1. 知识的“消化吸收”:全域数据接入与解析
第一步是将散落的知识喂给系统。我们通过“予非·睿知”提供的可配置连接器,实现了对公司主要知识源的纳管:
- Confluence/Wiki:通过API定期同步页面内容。
- GitLab/GitHub:拉取指定仓库的Markdown文档、代码注释。
- 共享盘:挂载并实时索引PDF、Word、PPT等格式的文档。特别地,对于扫描版的技术方案和图纸,平台内置的OCR服务起到了关键作用。
2. 双引擎检索:当向量搜索遇上知识图谱
这是整个系统最核心的部分。单纯的向量搜索或知识图谱都有其局限性,我们将两者结合,实现了1+1>2的效果。
a) 向量检索
负责处理模糊的、语义化的查询。所有被解析的文档内容,都会被切片并经过BGE等业界领先的Embedding模型,转化为高维向量,存储在向量数据库(如Milvus)中。
当开发者提问:“如何解决K8s中服务发现延迟的问题?”
系统会执行一个典型的RAG流程:
b) 知识图谱检索
负责处理精确的、结构化的关系查询。在数据解析的同时,“予非·睿知”的知识抽取模块会识别出代码、文档中的关键实体(如:服务、API、数据库、开发者、Bug单号)及其关系,构建一个庞大的知识图谱(基于Neo4j)。
当开发者提问:“支付服务依赖了哪些数据库?负责人是谁?”
这种问题用向量搜索很难得到精准答案,但知识图谱查询轻而易举。
四、功能展示:予非·睿知帮你“弯道超车”
多模态知识库
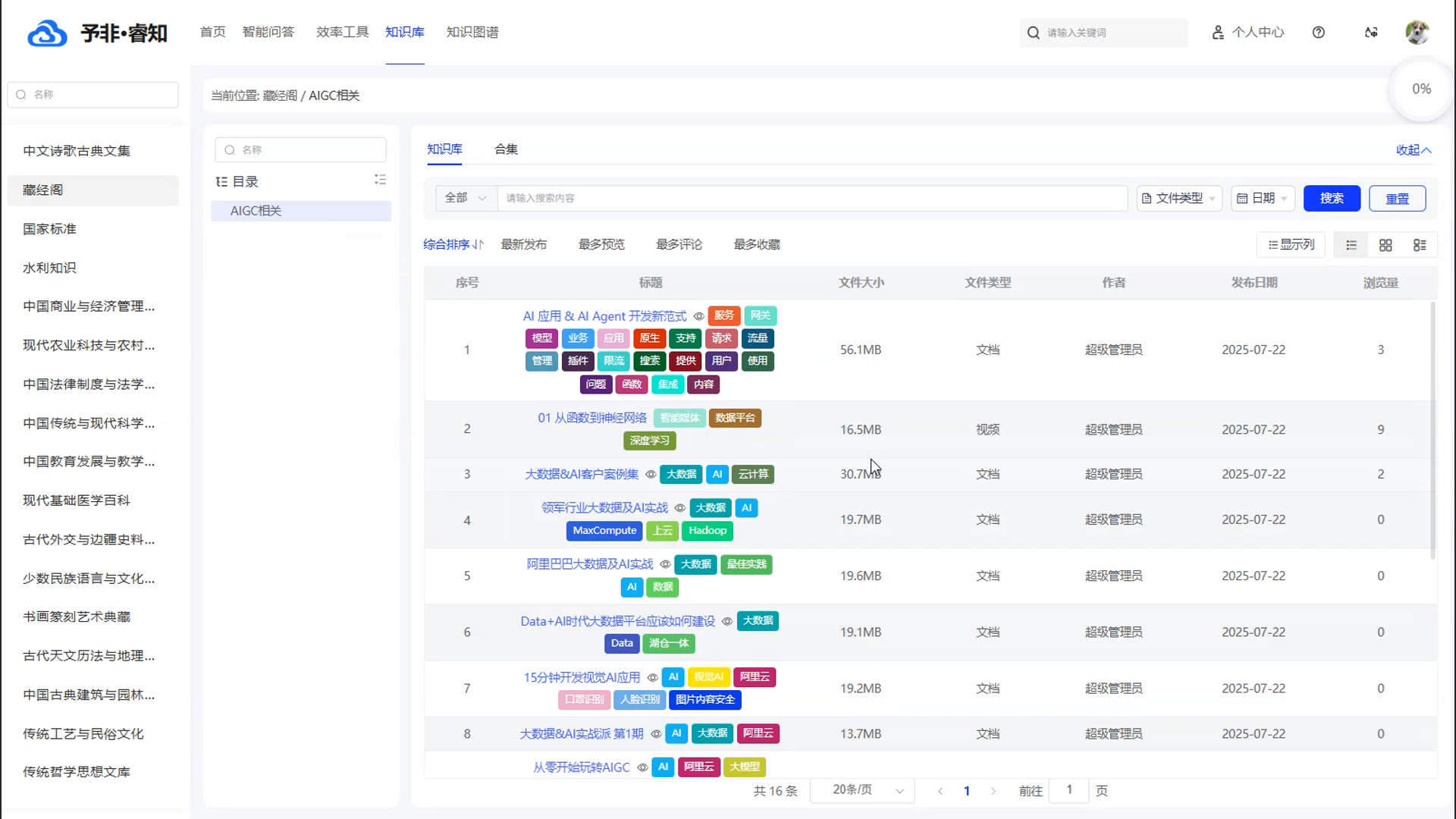
智能化的知识检索与筛选: 产品提供强大的智能搜索功能,用户可以通过输入关键词,快速在海量的知识库中进行检索。同时,系统支持多种筛选和排序方式,例如“综合排序”、“最新发布”、“最多浏览”和“最多收藏”,帮助用户更精准地定位所需信息。
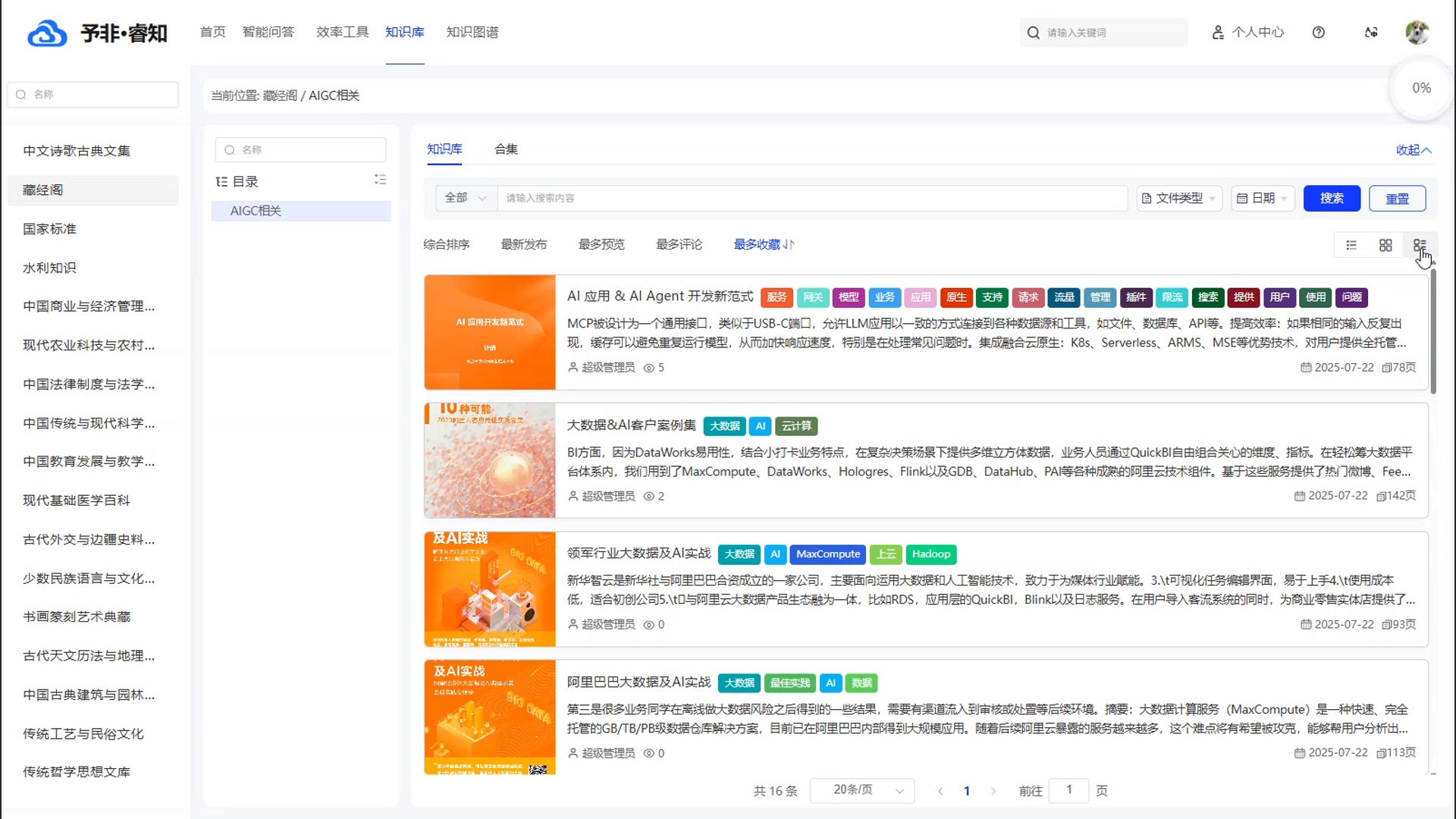
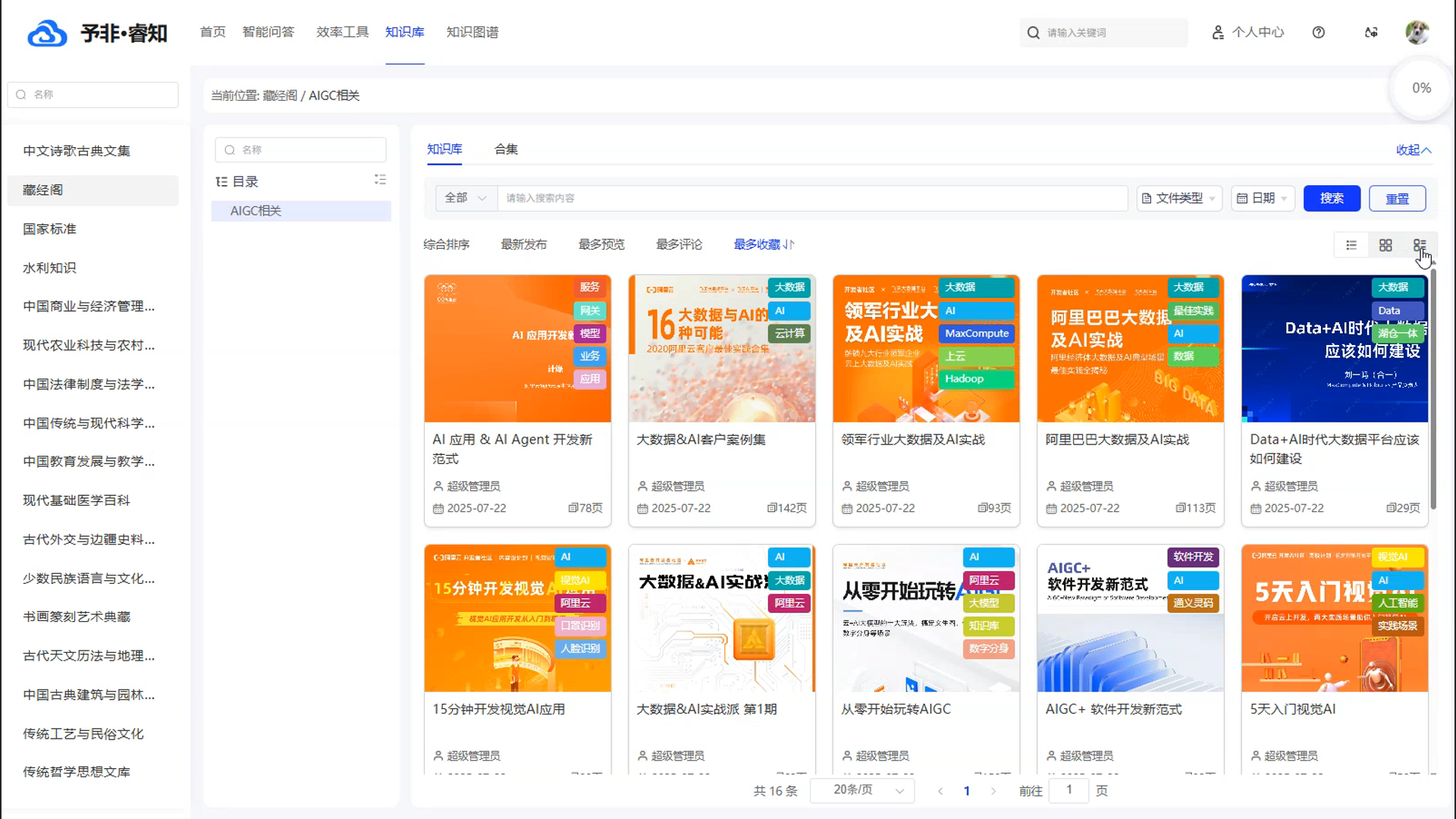
多模态内容呈现: 为了满足不同场景下的浏览需求,产品支持多种内容展示形式。用户可以根据自己的偏好,在清晰的“列表视图”、直观的“摘要视图”和美观的“卡片视图”之间自由切换,获得最佳的阅读体验。
结构化的知识分类: 平台提供灵活、强大的树状分类功能,支持企业根据自身的业务逻辑和知识脉络,自由搭建多层级的知识目录。这能帮助企业构建起一套结构清晰、逻辑严谨、独一无二的专属知识体系,让信息资产井然有序。

AIGC 与大模型深度赋能: 本产品并非简单的知识存储容器,而是深度融合了前沿 AIGC 与大模型技术的智能工作伙伴。它能够实现文档自动摘要、智能问答、内容关联推荐等高级功能,将沉睡的数据和文档激活为可以对话、可以思考的动态知识,极大提升知识的应用效率与创新价值。
知识图谱
自动化的知识构建与关联:平台能够自动从海量的非结构化文档中,精准识别并抽取关键实体,例如“项目”、“客户”、“技术规格”、“核心人员”等。更重要的是,它能智能分析这些实体之间的内在联系,将过去散落在各个角落的信息点连接成一张逻辑清晰、关系明确的知识网络。
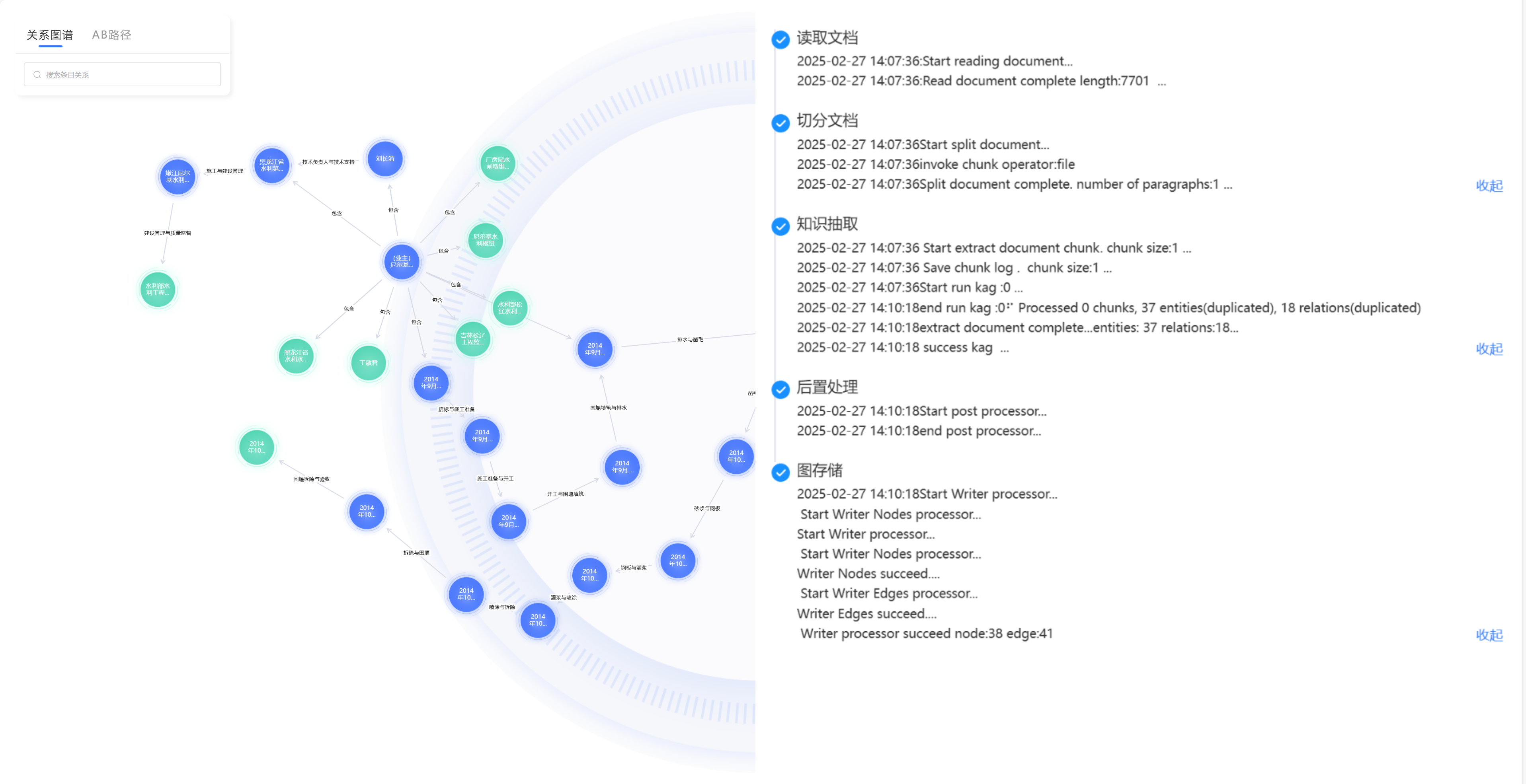
可视化的关系探索与发现:知识图谱将复杂的知识关系以直观、动态的图形化方式呈现。用户可以轻松地在图谱上进行漫游、钻取和分析,一目了然地看清某个项目涉及的所有人员、文档和技术节点,或某个技术在公司所有产品线中的应用情况,从而发现过去难以察觉的深层联系与潜在价值。
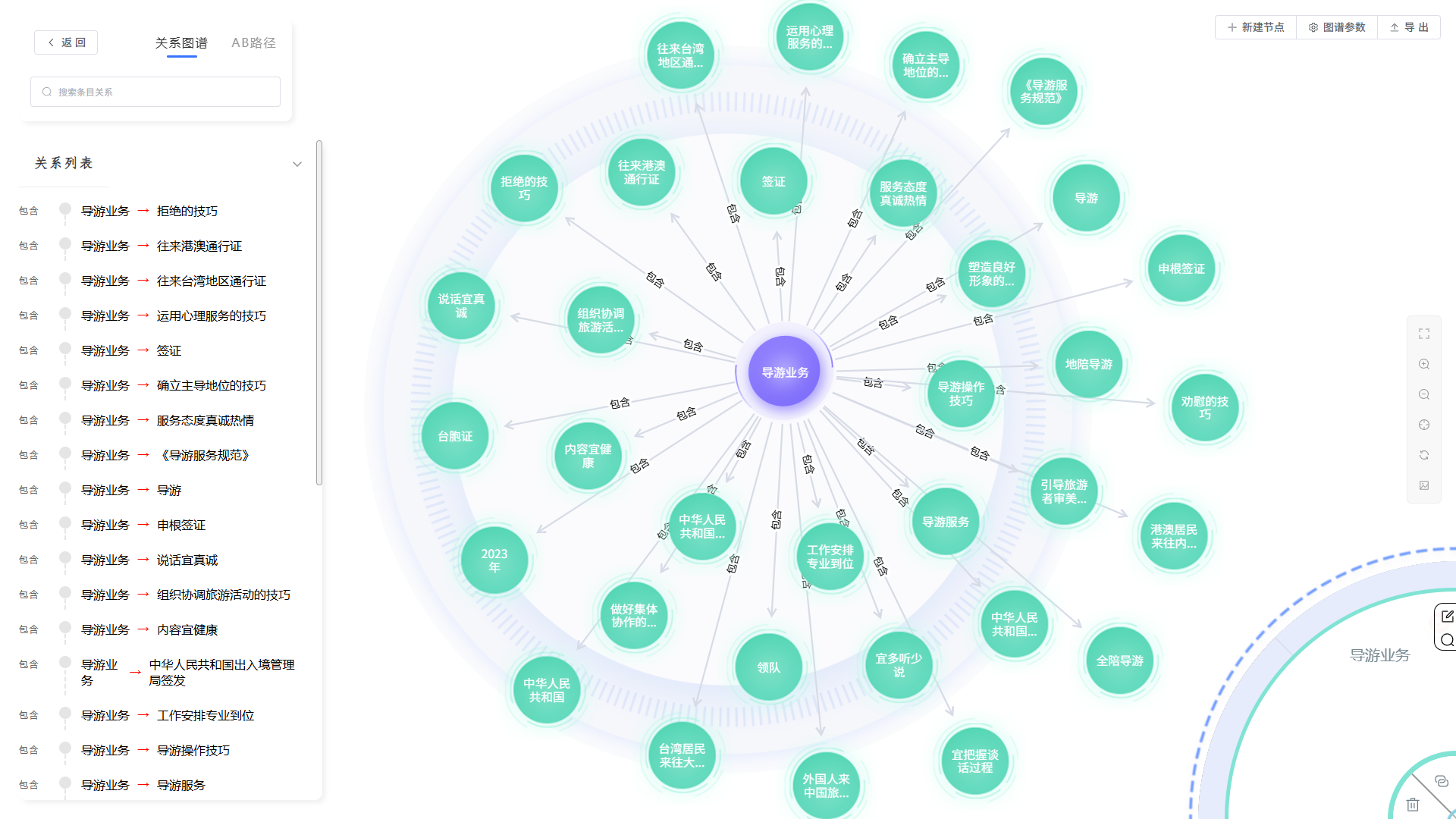
深度的智能推理与分析: 基于已构建的知识网络,系统能够进行复杂的路径查找与智能推理。例如,它可以帮助您分析“某个技术专家的变更对哪些关联项目可能产生风险”,或“与A客户有相似需求特征的还有哪些潜在客户”,为企业的战略决策、风险预警和业务创新提供强有力的数据支持。
知识问答
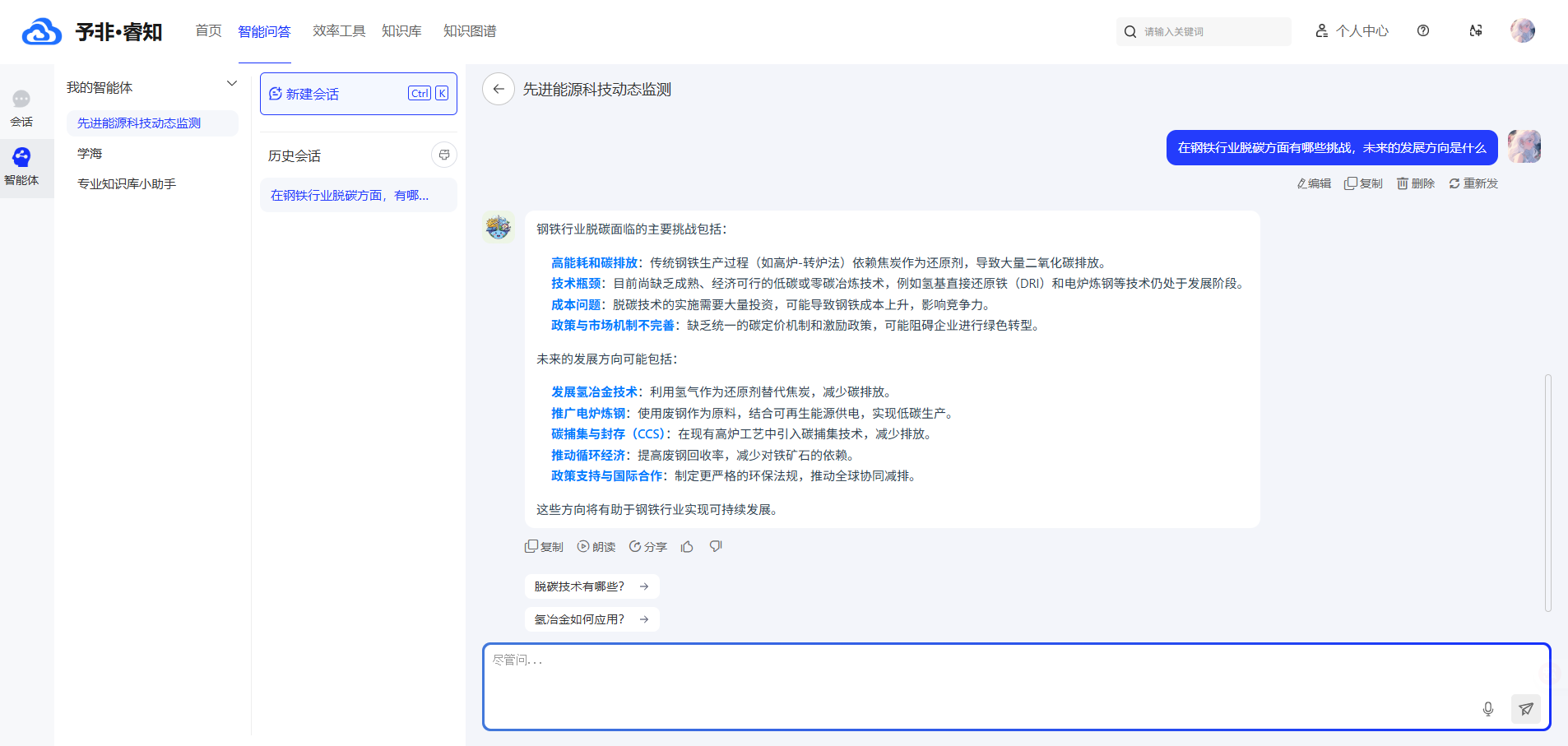
基于深度理解的精准回答: 深度融合DeepSeek等业界领先的大模型,平台具备强大的知识理解与推理能力。它能够准确识别用户问题的意图,即使是复杂的、口语化的表达,也能提供专家级的精准解答,助力企业进行快速、准确的智能决策。
支持联网搜索,知识永不过时: 平台支持与主流搜索引擎接口对接,当本地知识库无法满足需求时,能够通过联网搜索来增强问答能力。这确保了企业获取的信息永远是最新、最全面的,有效提升了决策的准确性和时效性。
基于企业知识的精准回答:与通用的互联网搜索不同,本产品的问答完全基于企业自身的私有知识库。它能够结合上下文,进行逻辑推理和内容归纳,最终生成有理有据、来源可溯的精准答案。每一个回答都忠于原文,确保了信息的权威性、私密性和可靠性。
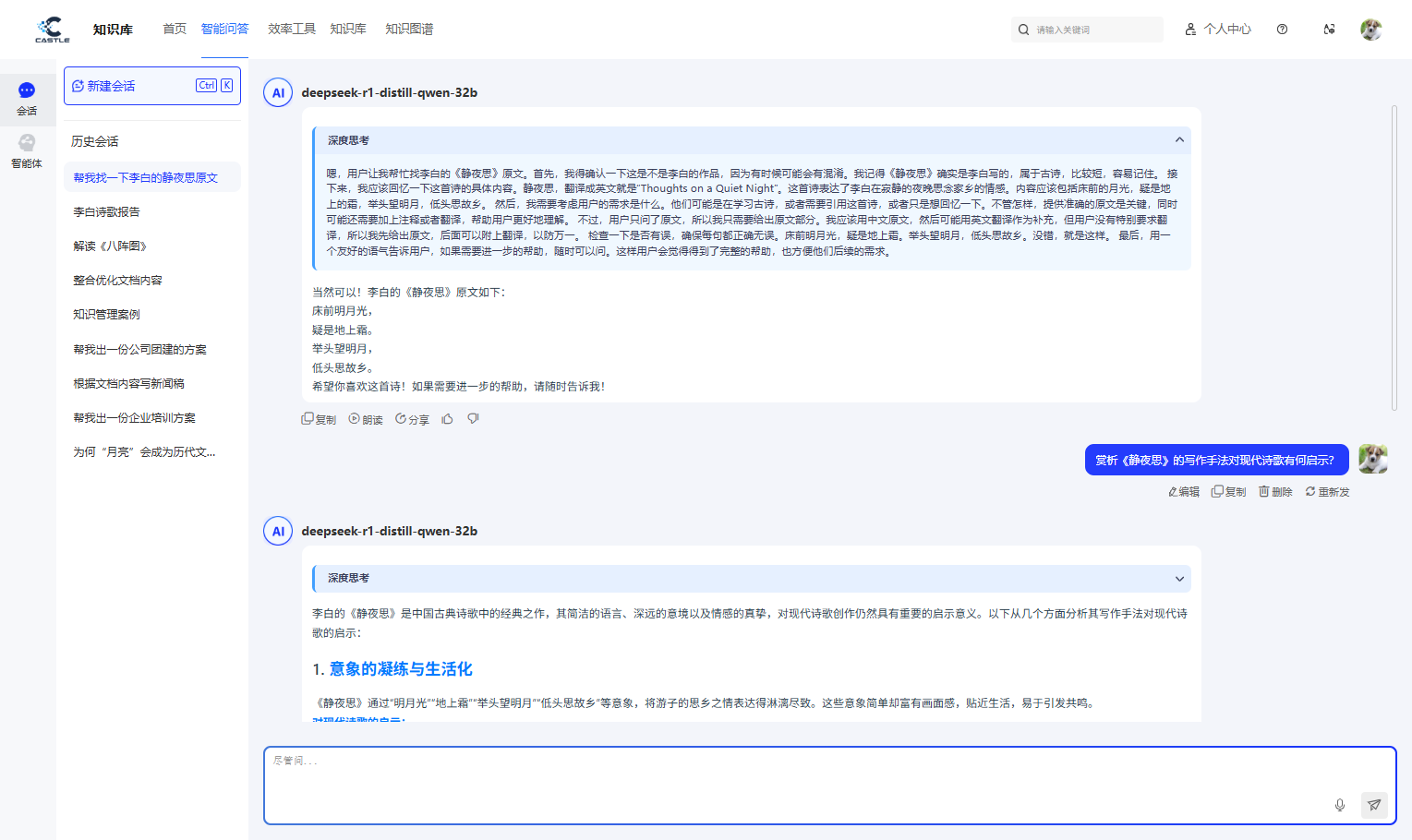
智能总结与多轮追问: 针对内容冗长的文档,用户无需通读全文,只需一键即可生成核心要点总结。同时,系统支持连续的多轮对话,能够记忆上下文语境,允许用户就一个主题不断深入追问,层层剖析,直至找到问题的最终答案,实现高效的深度信息挖掘。
知识搜索
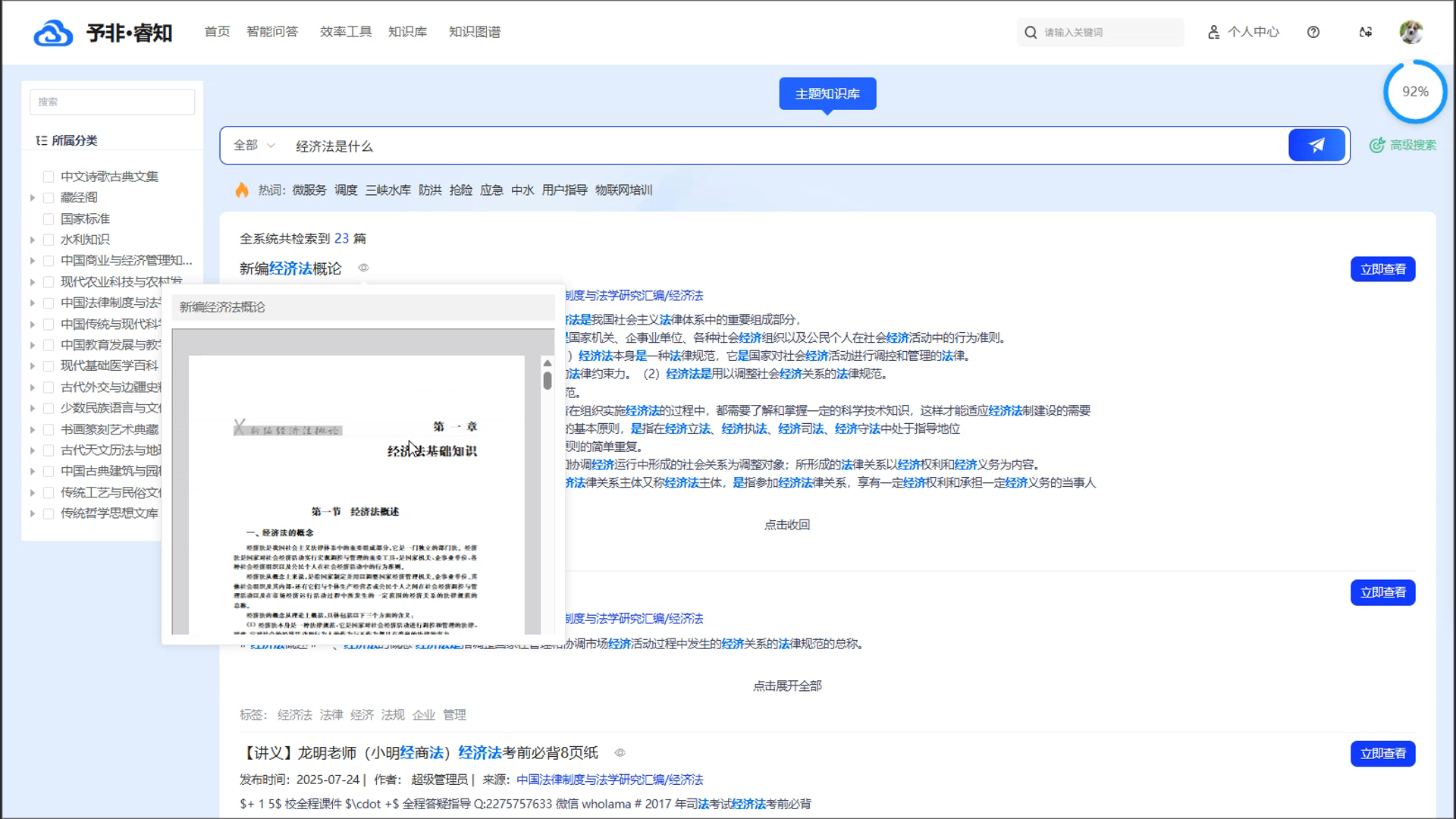
多模态内容的融合呈现: 平台能够无差别地管理包括文档、图片、音视频在内的各类文件,并在搜索结果中进行统一呈现。搜索结果以直观的 “卡片视图” 样式展示,每一条结果都清晰地包含了标题、发布时间、来源、标签以及内容缩略图。这种融合了丰富元信息的可视化呈现方式,让用户在点击查看前就能对内容有全面的了解,极大地提升了知识获取的效率和体验。
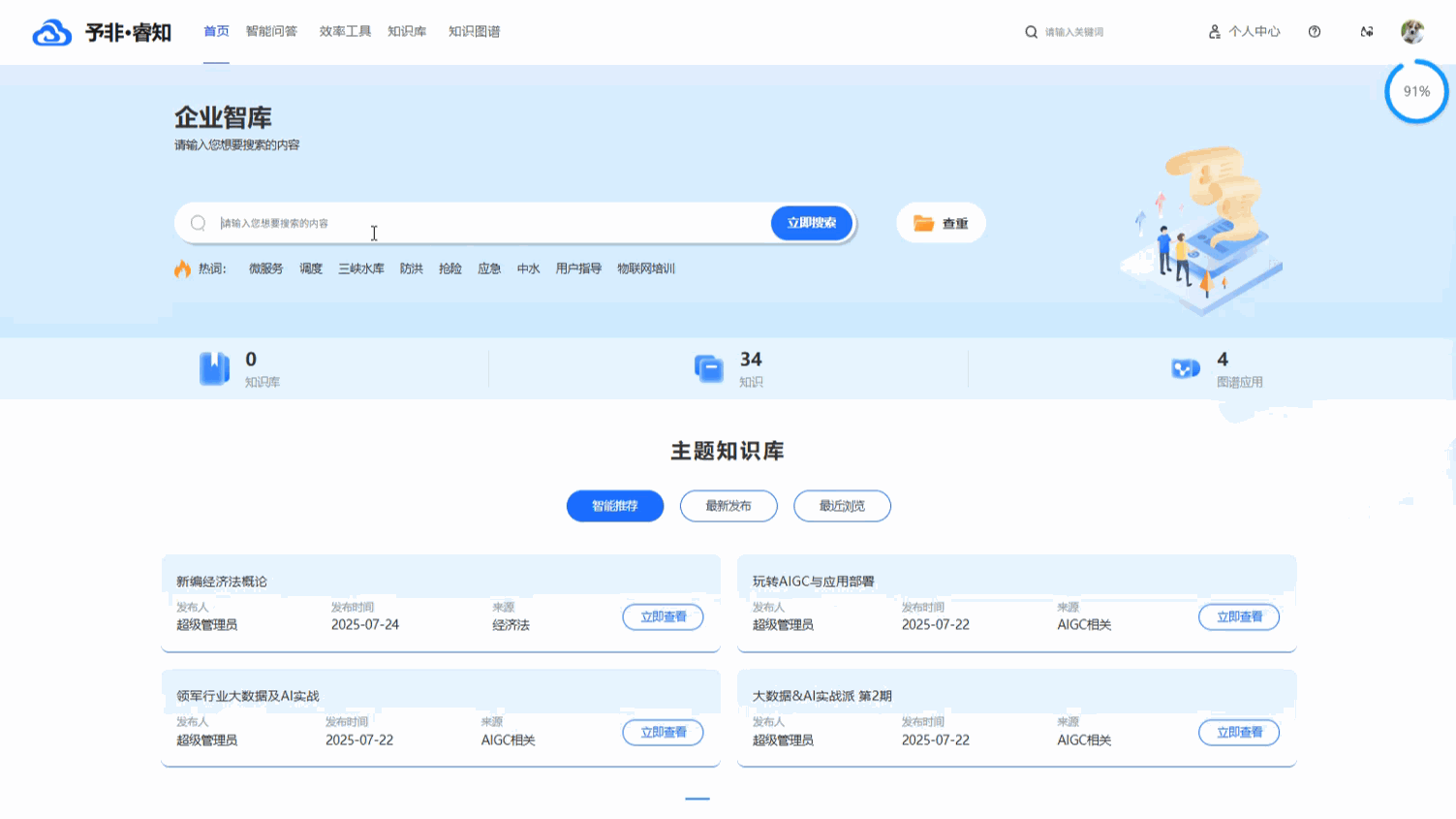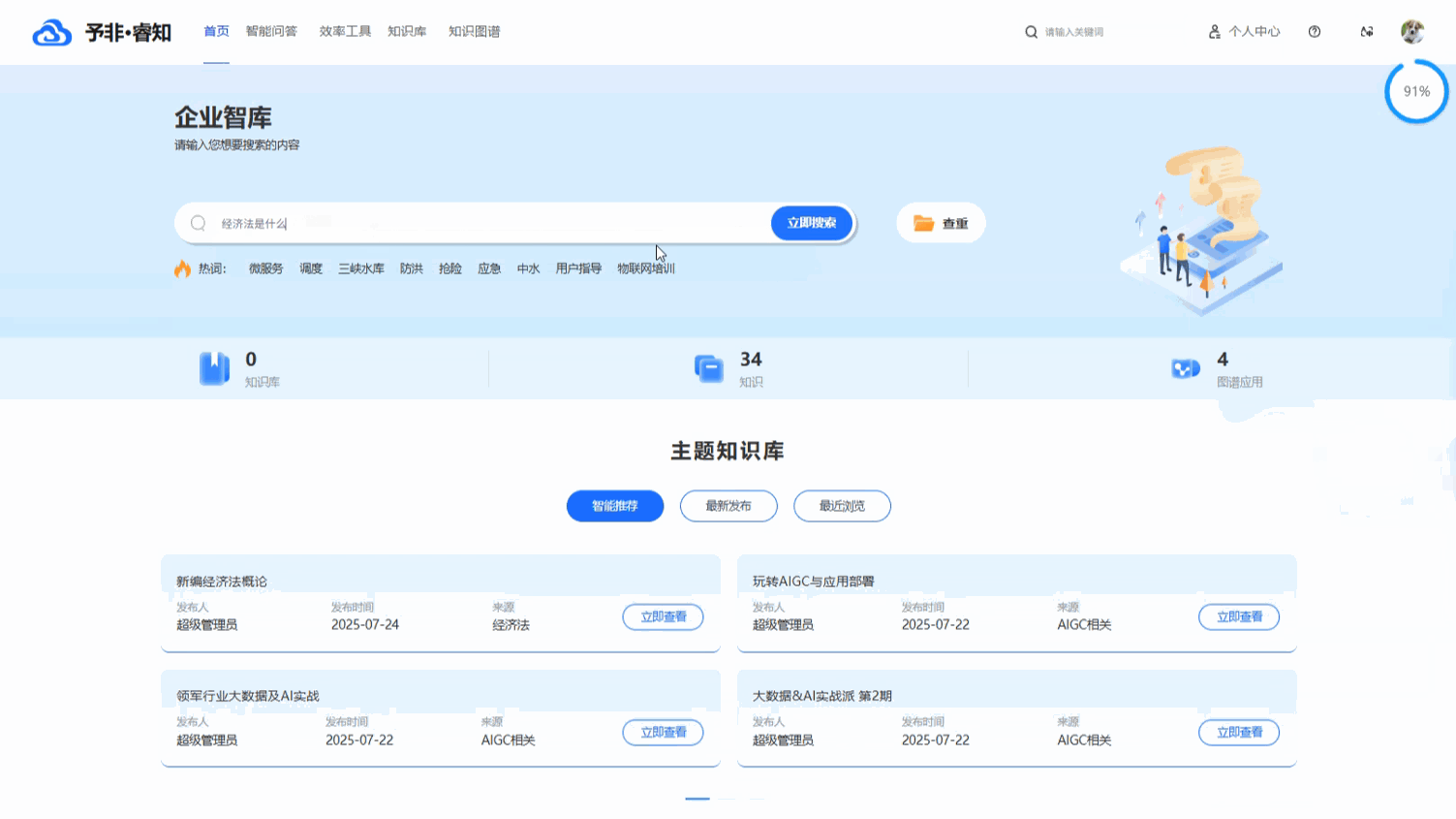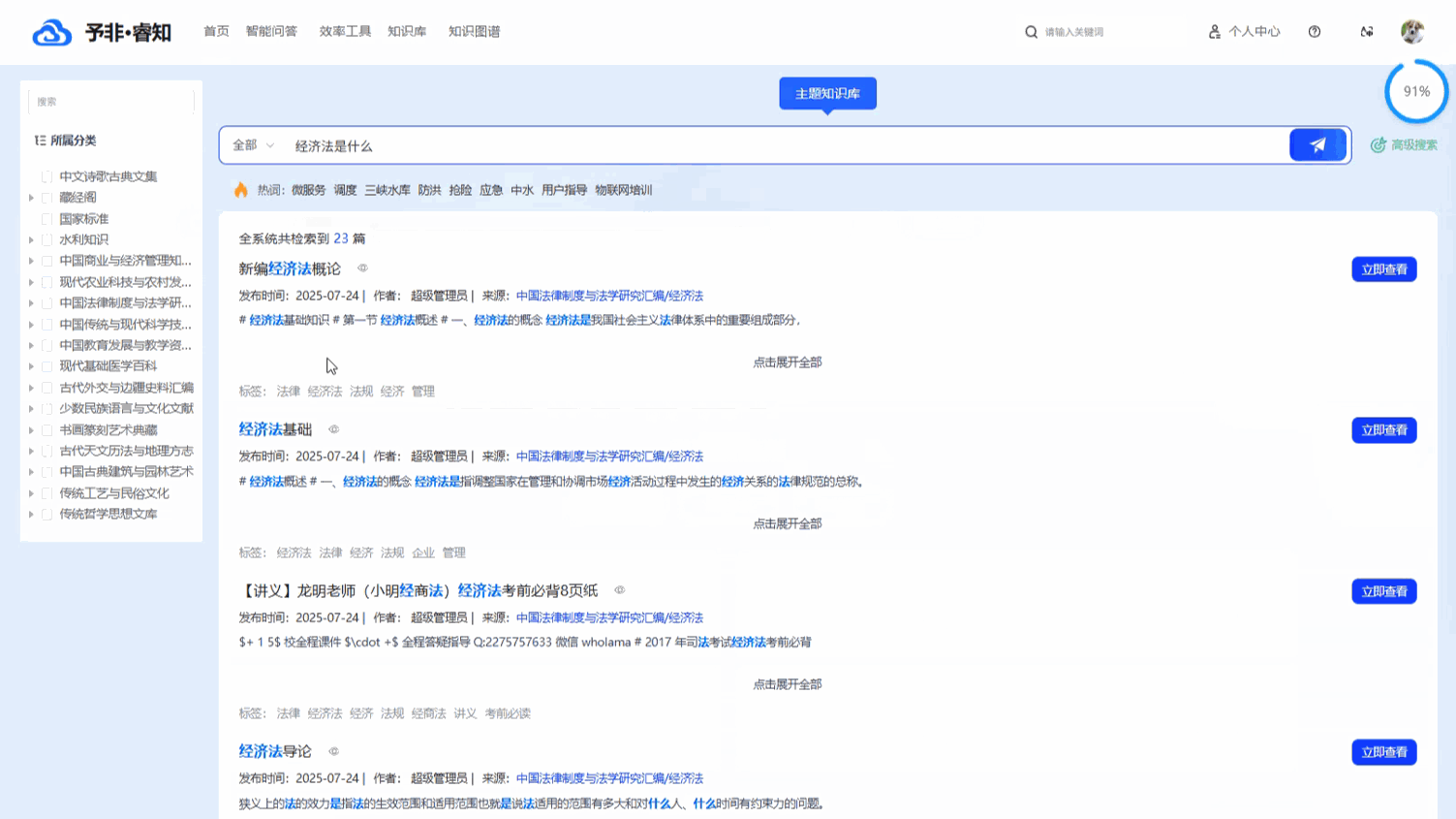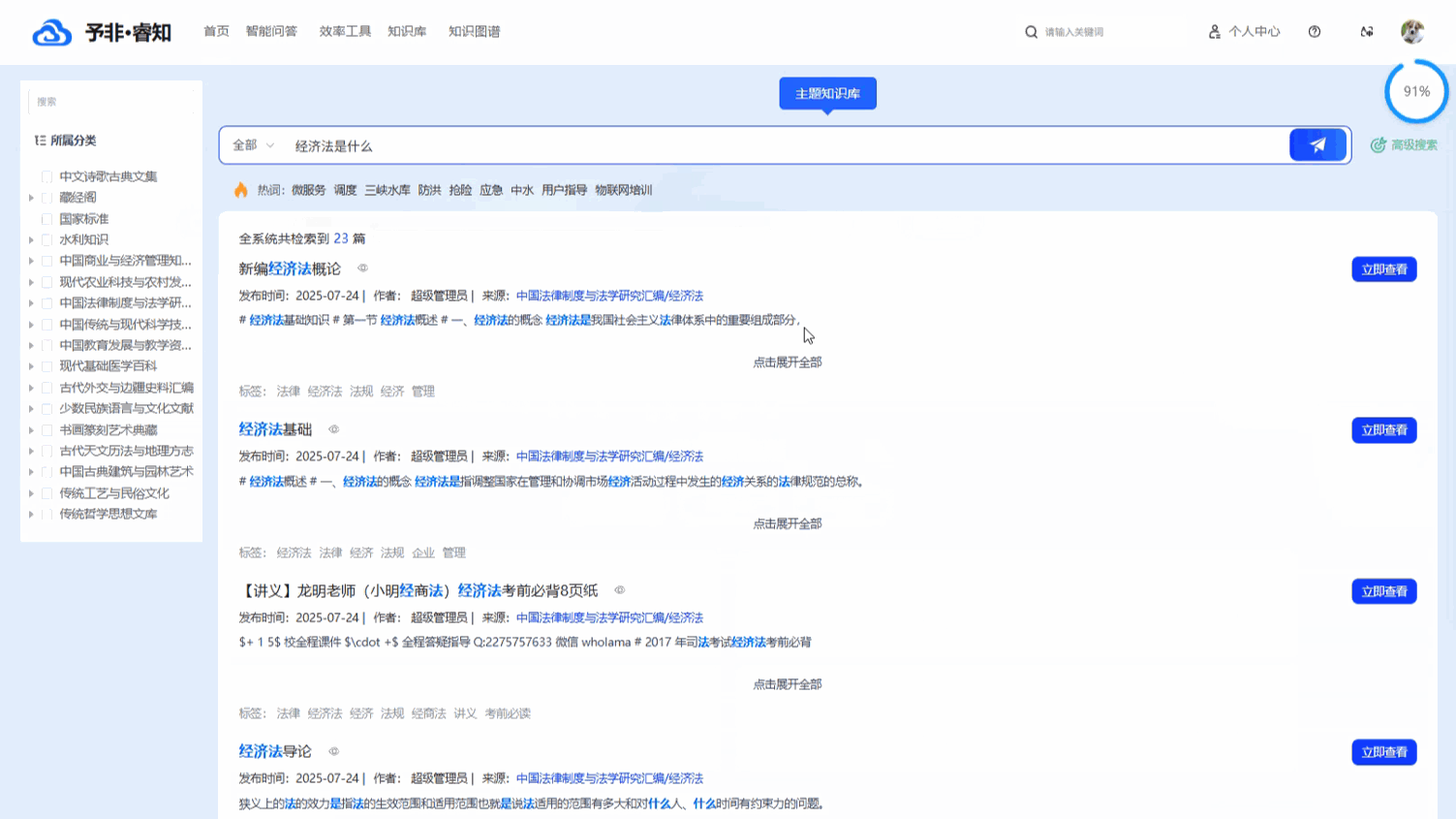
融合语义的智能检索与筛选: 平台的核心搜索功能由先进的 语义搜索 引擎驱动。这意味着系统能够深度理解用户查询的真实意图,而不仅仅是匹配字面上的关键词。即使用户输入的词语与知识库中的文档标题或内容不完全一致,只要在概念上高度相关,系统也能精准地将其找出,从而大幅提升搜索的召回率和准确率。在语义搜索精准锁定相关知识范围的基础上,用户还可以进一步利用 “高级搜索” 功能,根据 文档类型和 时间范围进行多维度筛选,实现从海量数据中快速、精准地触达目标信息。
知识图谱搜索,洞察深层关联: 搜索功能与平台的知识图谱能力深度融合,使用户能够进行超越文本层面的关联和探索。通过 “实体关系对齐” 与 “实体链接” 技术,系统可以在搜索时揭示出知识点之间隐藏的关联。
效率工具
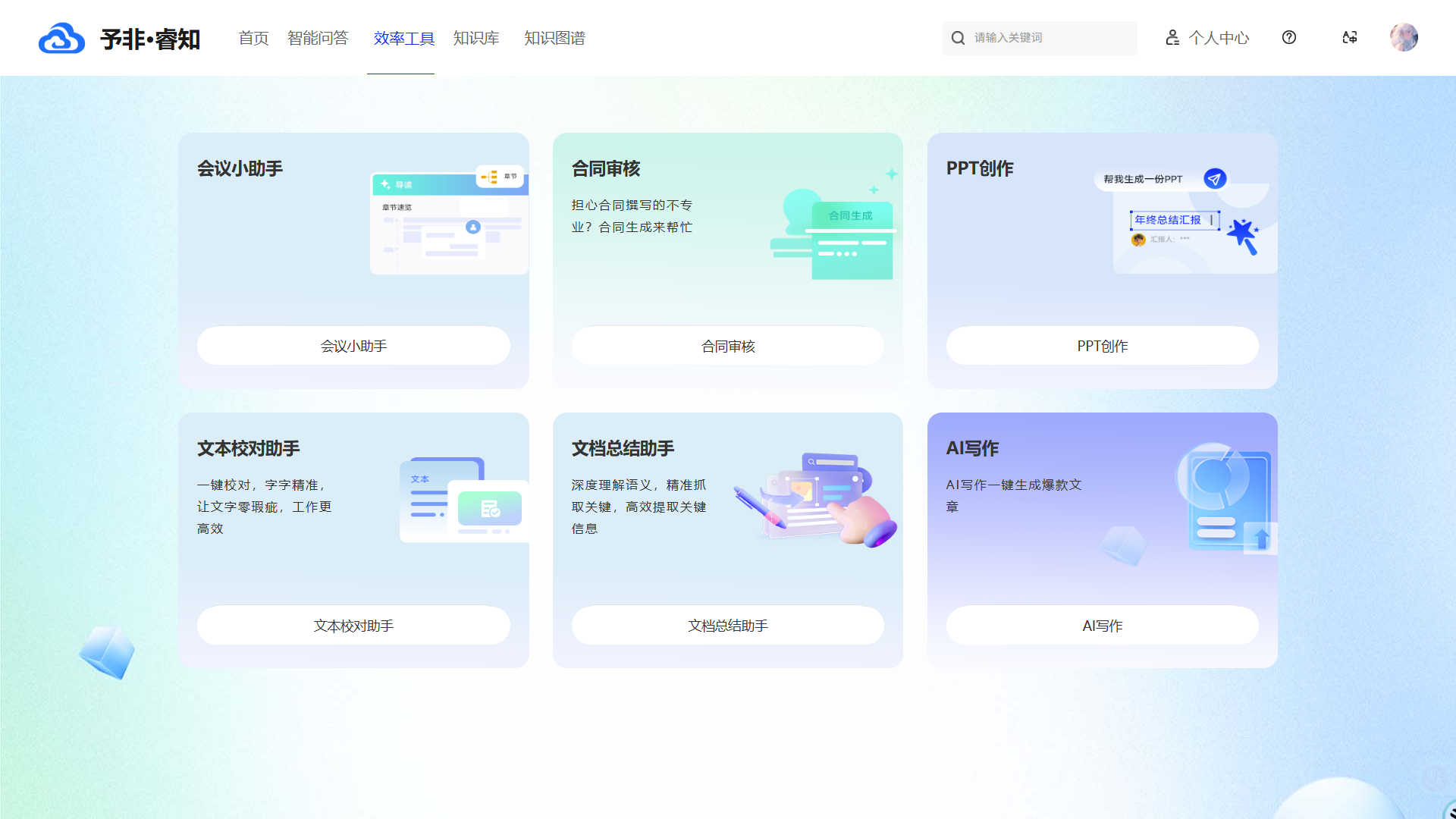
开箱即用的智能化工具: 平台内置了包括AI写作、PPT创成、文本校对、文档总结、合同生成、会议纪要等在内的多种效率工具。这些工具深度融合了大模型能力,能够一键生成高质量的文案、演示稿和分析报告,将员工从繁琐的重复性劳动中解放出来。
私有化部署保证数据安全: 平台深刻理解企业对数据安全的核心关切,支持将所有效率工具模块进行完全的私有化、离线化部署。这意味着企业可以在享受AI带来便利的同时,确保核心数据不出内网,彻底消除数据泄露的风险,为企业的知识资产安全保驾护航。
五、结语
一个优秀的AI知识引擎,对于研发团队而言,绝非一个可有可无的“效率工具”,而是如同IDE、Git一样的核心基础设施。它通过偿还“知识债”,将团队从信息的泥潭中解放出来,最终实现了决策速度与研发效率的双重飞跃。
“予非·睿知”平台的目标,就是将这套复杂的架构和能力产品化,让更多的技术团队能够低成本、高效率地构建起属于自己的“第二大脑”,在激烈的技术竞争中,实现真正的“弯道超车”。


















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









