




在企业中,80%的知识存在于PDF、PPT、扫描件、会议录音等非结构化数据中。
但大多数“知识库”系统只是把这些文件当作文本堆砌,导致搜索不准、问答模糊、信息割裂。
真正的智能知识管理,应该能自动把一份PDF变成可检索、可推理、可关联的知识节点。
本文将带你走完这条“从PDF到知识图谱”的完整技术链路——我们已在予非·睿知企业Ai知识引擎平台实现全流程自动化,文档结构化效率提升 70%+。
一、为什么大多数知识库“读不懂”PDF?
很多企业用向量数据库+大模型搭建RAG系统,结果发现:
- 问“去年Q3项目进度如何?”却返回无关段落;
- 扫描版PDF识别错乱,关键数据丢失;
- 表格内容被当成普通文本,语义断裂。
根本原因在于:对非结构化文档的处理停留在“粗粒度向量化”阶段,缺乏深度解析能力。
而一份典型的PDF文档可能包含:
- 多层级标题与段落
- 图片、图表、公式
- 嵌套表格(甚至跨页表格)
- 页眉页脚、水印、扫描噪点
如果不对这些元素进行语义重建,后续的检索与问答必然失准。
二、我们的解决方案:五步走完“PDF → 知识图谱”全链路
我们在构建企业知识引擎时,设计了一套完整的非结构化文档处理 pipeline:
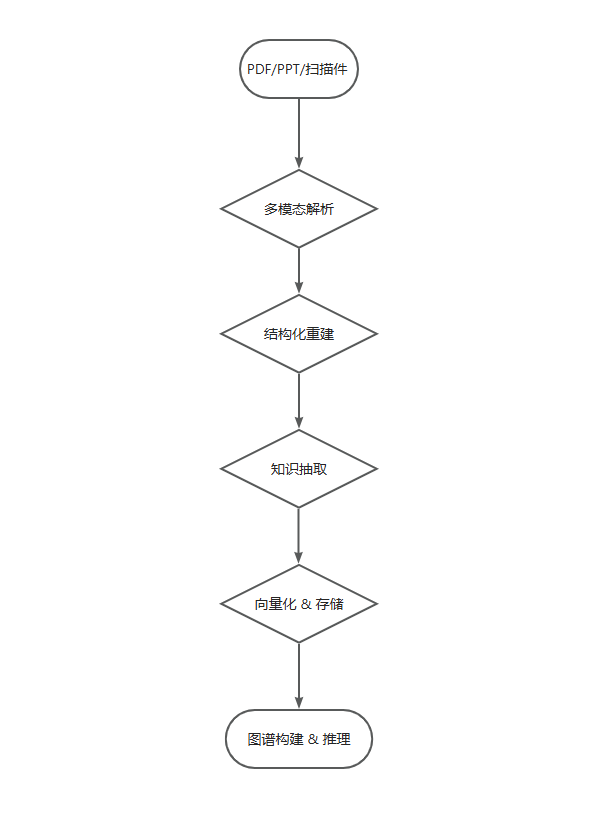
下面我们一步步拆解。
第一步:多模态解析 —— 让机器“看清”每一页
支持多种输入格式:PDF、DOCX、PPTX、Excel、扫描件、音视频等。
关键技术点:
- 使用 OCR 引擎(如PaddleOCR)处理扫描件,识别准确率 >98%
- 利用 LayoutParser 技术识别文档布局:标题、正文、表格、图片位置
- 音视频文件通过 ASR 语音转写 提取内容,并打上时间戳
第二步:结构化重建 —— 给文档“洗个澡”
原始解析结果往往是“一整段文本”,我们需要重建其逻辑结构。
处理流程包括:
- 章节切分:基于字体大小、编号规则识别 H1/H2/H3 标题
- 上下文补全:为每个段落添加所属章节、页码、文档来源等元信息
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









