



我们常听到企业客户说:“我搭了RAG系统,为什么大模型回答总是‘一本正经地胡说八道’?”
问题往往不在于大模型本身,而在于——你喂给它的知识,根本就没“洗干净”。
在实际落地中,我们发现:70%的RAG失败案例,源于对非结构化数据的“裸奔式处理”。
本文将揭秘我们在予非·睿知企业Ai知识引擎平台中提升问答准确率的关键工程实践——重点不是“怎么问大模型”,而是“怎么把知识准备好”。
一、为什么你的RAG问答准确率卡在60%?
很多团队的RAG流程是这样的:
看似简洁,实则隐患重重。
常见问题:
- 检索到的段落是“断章取义”的半句话;
- PDF扫描件OCR识别错误,关键数据失真;
- 合同条款被拆分到不同块中,语义断裂;
- 多个版本文档共存,系统不知该信哪个。
结果就是:模型基于“脏知识”做推理,答得越流畅,错得越离谱。
我们的发现:
RAG的准确率,70%取决于检索前的数据预处理,30%才是模型和检索算法。
为此,我们在予非·睿知企业Ai知识引擎平台构建了一套完整的 “RAG预处理工程体系”,涵盖5个核心环节。
二、提升准确率的5个关键预处理环节
🔹 环节1:全自研文档解析引擎 —— 让机器“看清”每一页
问题:
传统OCR工具对复杂排版(如图文混排、表格跨页)处理能力弱,导致信息丢失。
我们的做法:
- 采用全自研多格式文档解析引擎,支持 PDF/DOCX/PPTX/XLSX/TXT/MD 等数十种格式;
- 集成先进OCR模型,针对图文混排复杂文档优化,解析准确率提升 30%以上;
- 支持大文件上传、断点续传、在线预览;
- 解析效率平均水平提升 50%+。
🔹 环节2:智能分块 + 上下文增强 —— 避免“一句话被截断”
问题:
简单按字符数切分文本(如每512字一块),会导致“一句话被截断”、“表格被拆开”。
我们的做法:
采用 基于语义边界的智能分块策略:
- 在章节切换、段落结束处优先切分;
- 对代码、表格、列表等内容整体保留;
- 引入 滑动窗口+重叠机制,确保上下文连续;
- 每个文本块注入丰富元数据:来源文件、章节标题、页码、创建时间、责任人等。
🔹 环节3:向量化存储与高效检索 —— 毫秒级响应的背后
问题:
向量检索慢、语义漂移严重,导致长期使用后准确率下降。
我们的做法:
- 基于 BGE 预训练模型 实现文本深度语义编码;
- 采用 HNSW 层次化索引,支持千万级向量在 400ms 内完成检索;
- 结合动态微调机制,将语义漂移率控制在 <0.5%/月;
- 文本相似度匹配准确率达到 97.2%,支持千级并发实时检索。
支持多种搜索方式:
- 关键词搜索
- 向量语义搜索
- 拼音搜索、查询纠错
- 标签/作者/日期筛选
- 阅读理解搜索
🔹 环节4:知识去重与版本控制 —— 只返回最新有效内容
问题:
企业常有多个版本的同一文档(如“合同V1.0”、“合同V2.0”),系统无法判断哪个是最新的。
我们的做法:
- 基于文档相似性算法识别重复内容;
- 构建“文档谱系图”,自动识别主版本与修订记录;
- 在检索时优先返回最新有效版本,避免“用旧规答新规”。
🔹 环节5:实体对齐与知识标准化 —— 让“张伟”只有一个身份
问题:
同一实体在不同文档中写法不一:
- “张伟” vs “张伟(项目经理)”
- “HT2024001” vs “合同HT-2024-001”
导致检索时无法关联。
我们的做法:
- 使用 LLM + NLP 技术 自动抽取“实体 / 关系 / 属性”;
- 建立“企业级实体词典”,实现指代消解与归一化;
- 支持自定义标签体系,配置权重与分类规则;
- 基于 Neo4j 图数据库 构建时空知识网络,支持 GNN 图神经网络与 OWL 语义推理。
✅ 效果:问答覆盖率达到 92%以上
三、你可以怎么借鉴?
方案一:自研预处理 pipeline(适合有AI团队的企业)
你可以参考以下技术栈:
- 文档解析:PaddleOCR + LayoutParser
- 分块策略:LangChain 的
RecursiveCharacterTextSplitter+ 自定义规则 - 向量检索:Faiss/Milvus + BGE模型
- 图谱构建:Neo4j + GNN推理
挑战:工程复杂度高,需持续维护
方案二:使用成熟平台(例如予非·睿知企业Ai知识引擎平台)
在予非·睿知企业Ai知识引擎平台,我们已将上述5个预处理环节封装,开箱即用:
多模态知识库
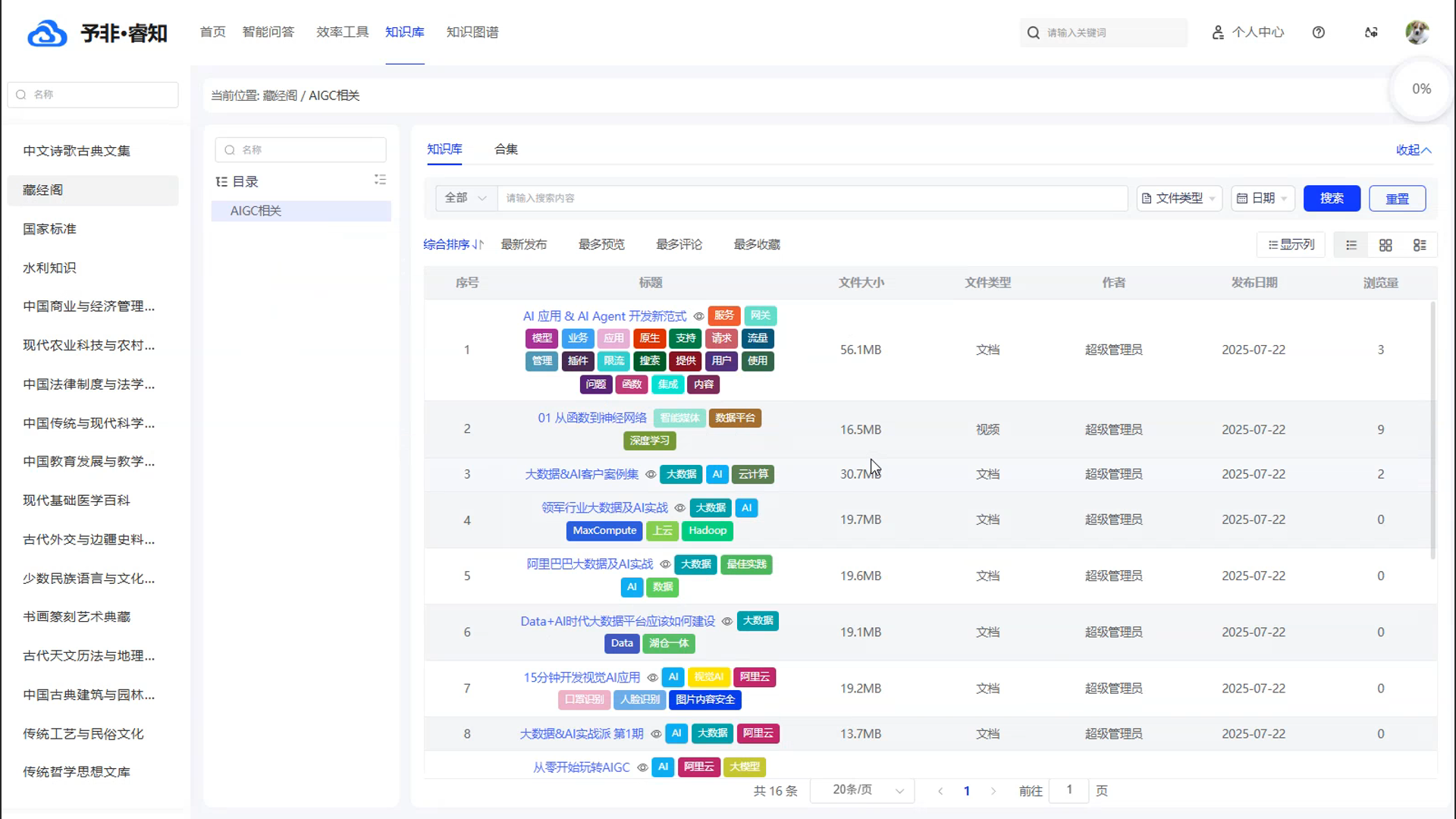
智能化的知识检索与筛选: 产品提供强大的智能搜索功能,用户可以通过输入关键词,快速在海量的知识库中进行检索。同时,系统支持多种筛选和排序方式,例如“综合排序”、“最新发布”、“最多浏览”和“最多收藏”,帮助用户更精准地定位所需信息。
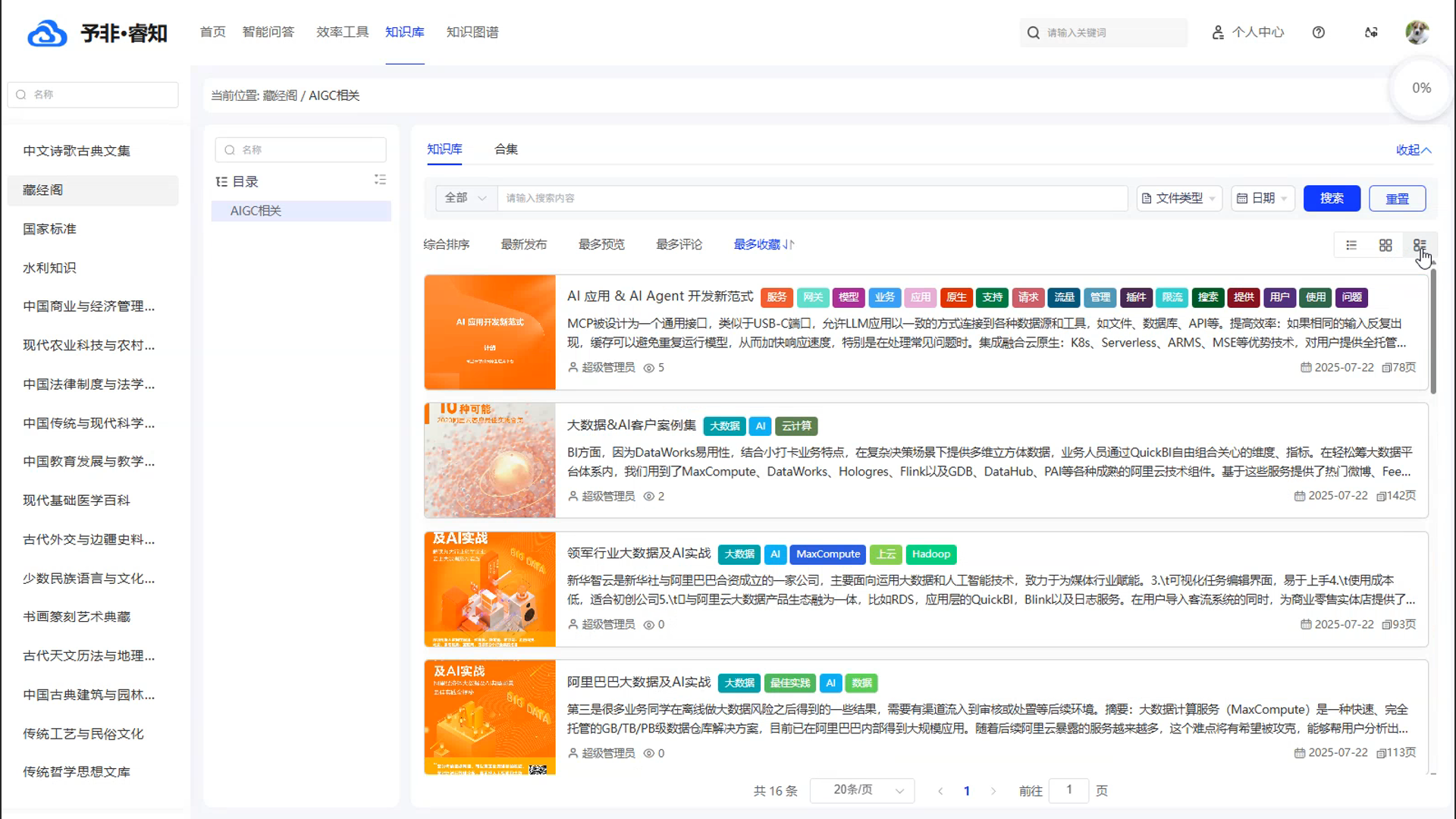
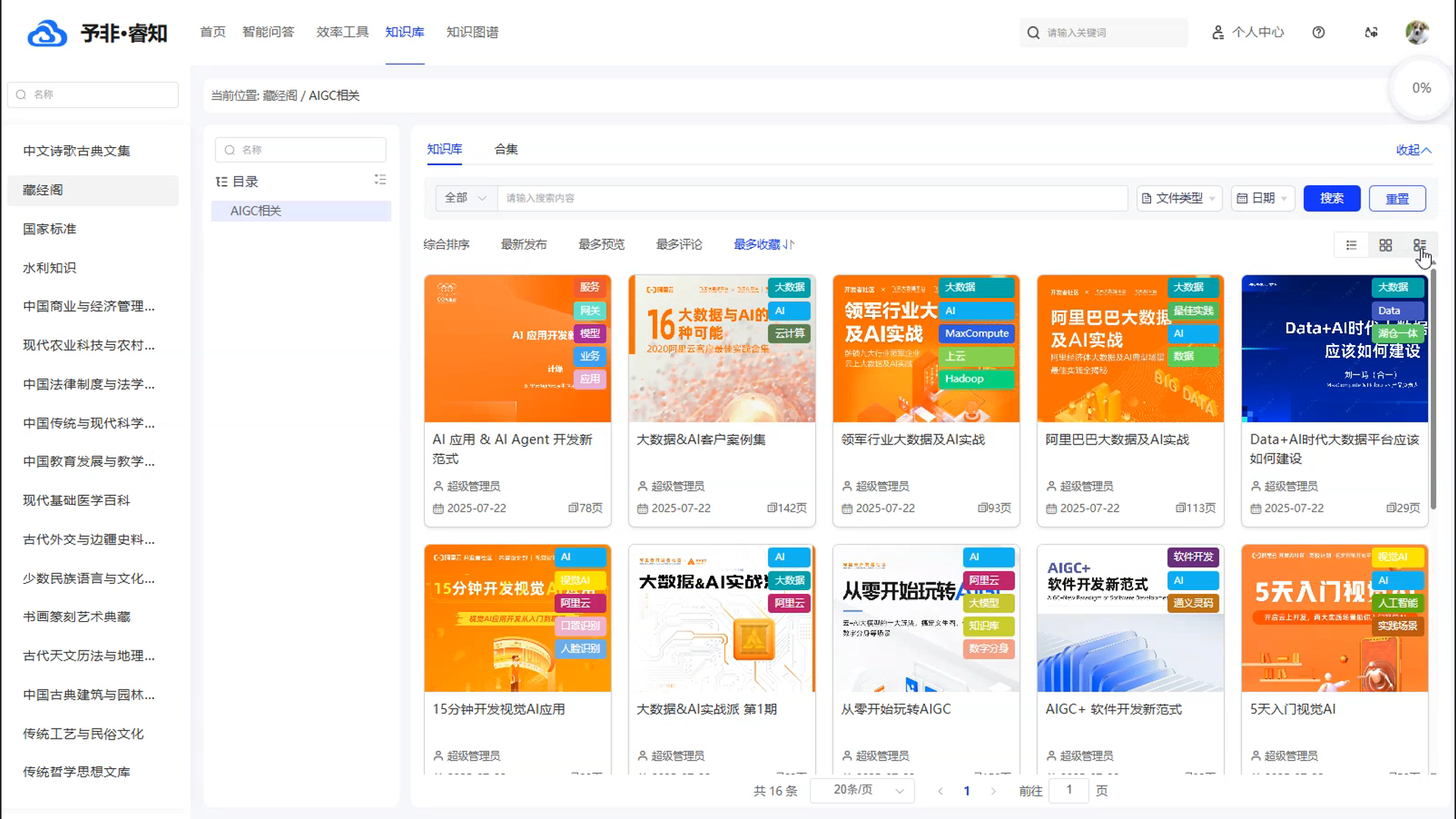
多模态内容呈现: 为了满足不同场景下的浏览需求,产品支持多种内容展示形式。用户可以根据自己的偏好,在清晰的“列表视图”、直观的“摘要视图”和美观的“卡片视图”之间自由切换,获得最佳的阅读体验。
结构化的知识分类: 平台提供灵活、强大的树状分类功能,支持企业根据自身的业务逻辑和知识脉络,自由搭建多层级的知识目录。这能帮助企业构建起一套结构清晰、逻辑严谨、独一无二的专属知识体系,让信息资产井然有序。

AIGC 与大模型深度赋能: 本产品并非简单的知识存储容器,而是深度融合了前沿 AIGC 与大模型技术的智能工作伙伴。它能够实现文档自动摘要、智能问答、内容关联推荐等高级功能,将沉睡的数据和文档激活为可以对话、可以思考的动态知识,极大提升知识的应用效率与创新价值。
知识图谱
自动化的知识构建与关联: 平台能够自动从海量的非结构化文档中,精准识别并抽取关键实体,例如“项目”、“客户”、“技术规格”、“核心人员”等。更重要的是,它能智能分析这些实体之间的内在联系,将过去散落在各个角落的信息点连接成一张逻辑清晰、关系明确的知识网络。
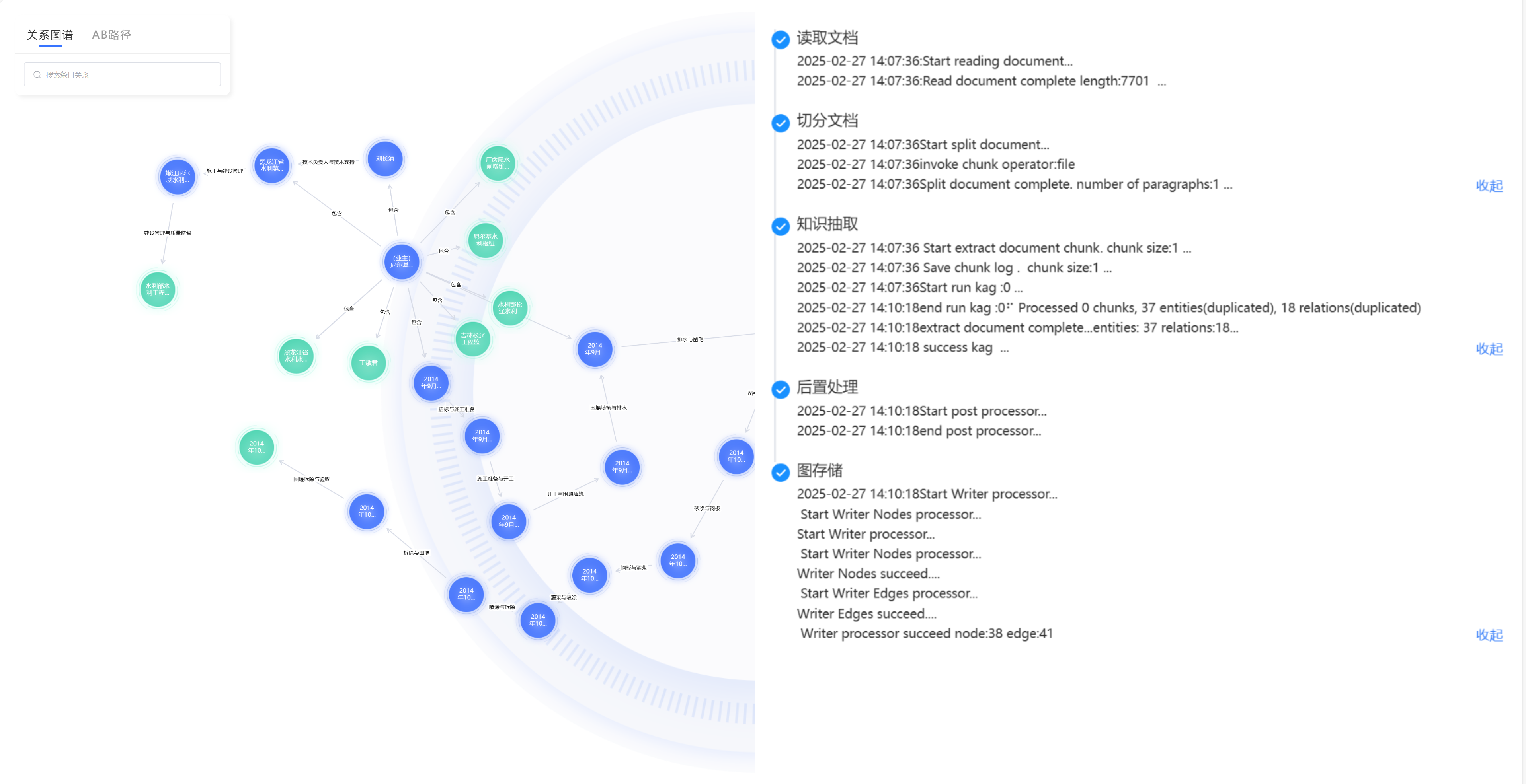
可视化的关系探索与发现: 知识图谱将复杂的知识关系以直观、动态的图形化方式呈现。用户可以轻松地在图谱上进行漫游、钻取和分析,一目了然地看清某个项目涉及的所有人员、文档和技术节点,或某个技术在公司所有产品线中的应用情况,从而发现过去难以察觉的深层联系与潜在价值。
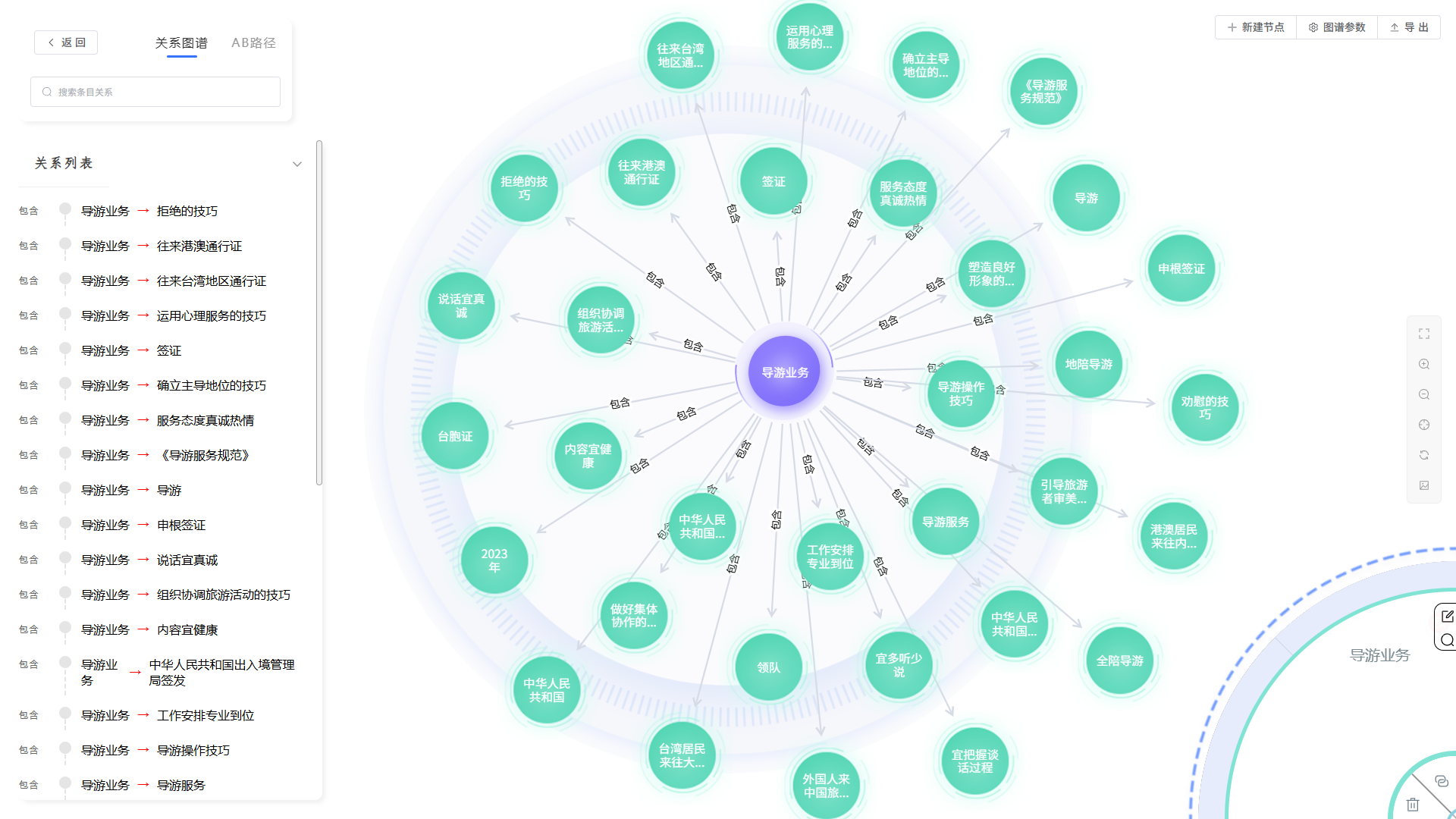
深度的智能推理与分析: 基于已构建的知识网络,系统能够进行复杂的路径查找与智能推理。例如,它可以帮助您分析“某个技术专家的变更对哪些关联项目可能产生风险”,或“与A客户有相似需求特征的还有哪些潜在客户”,为企业的战略决策、风险预警和业务创新提供强有力的数据支持。
知识问答
基于深度理解的精准回答: 深度融合DeepSeek等业界领先的大模型,平台具备强大的知识理解与推理能力。它能够准确识别用户问题的意图,即使是复杂的、口语化的表达,也能提供专家级的精准解答,助力企业进行快速、准确的智能决策。
支持联网搜索,知识永不过时: 平台支持与主流搜索引擎接口对接,当本地知识库无法满足需求时,能够通过联网搜索来增强问答能力。这确保了企业获取的信息永远是最新、最全面的,有效提升了决策的准确性和时效性。
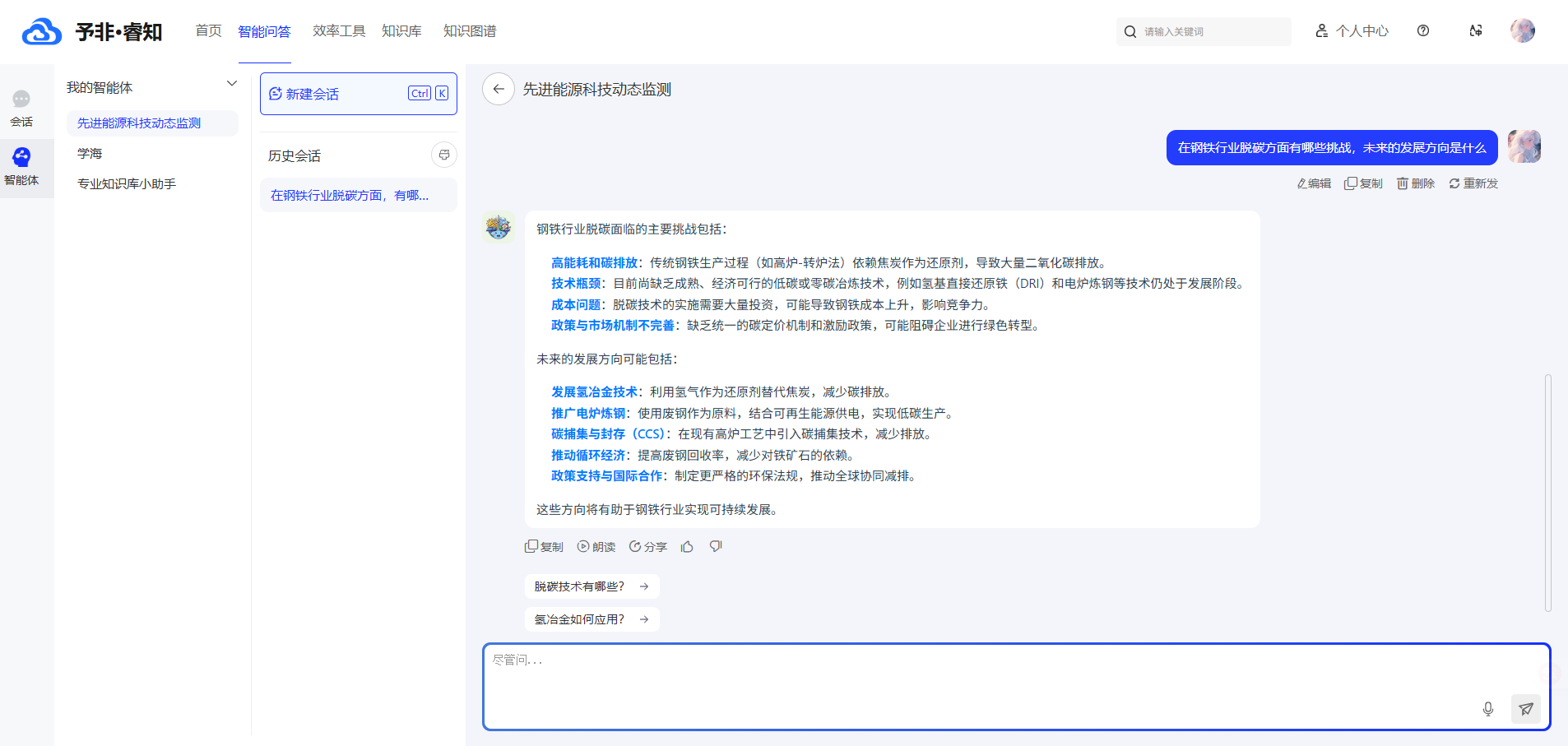
基于企业知识的精准回答: 与通用的互联网搜索不同,本产品的问答完全基于企业自身的私有知识库。它能够结合上下文,进行逻辑推理和内容归纳,最终生成有理有据、来源可溯的精准答案。每一个回答都忠于原文,确保了信息的权威性、私密性和可靠性。
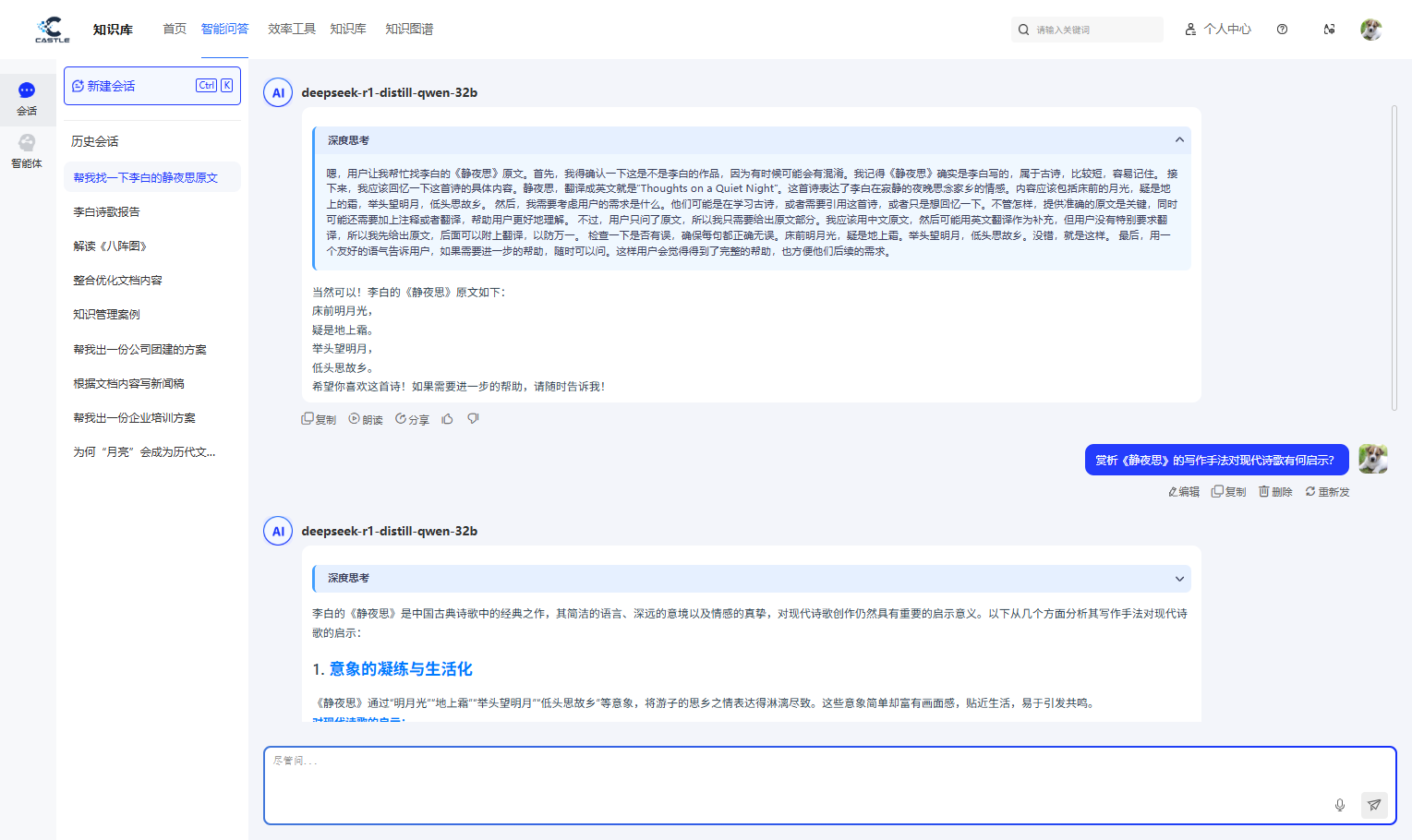
智能总结与多轮追问: 针对内容冗长的文档,用户无需通读全文,只需一键即可生成核心要点总结。同时,系统支持连续的多轮对话,能够记忆上下文语境,允许用户就一个主题不断深入追问,层层剖析,直至找到问题的最终答案,实现高效的深度信息挖掘。
知识搜索
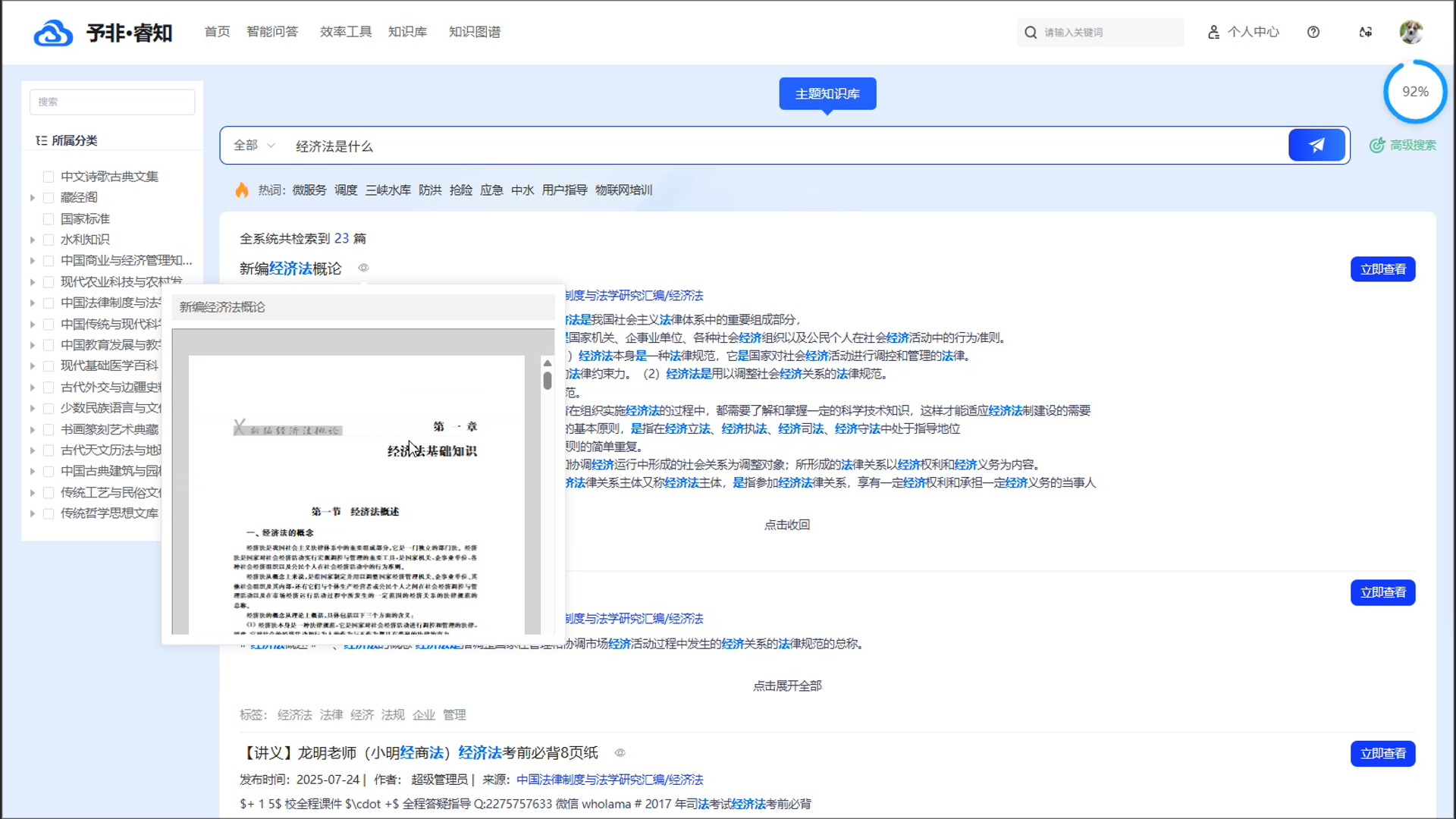
多模态内容的融合呈现: 平台能够无差别地管理包括文档、图片、音视频在内的各类文件,并在搜索结果中进行统一呈现。搜索结果以直观的 “卡片视图” 样式展示,每一条结果都清晰地包含了标题、发布时间、来源、标签以及内容缩略图。这种融合了丰富元信息的可视化呈现方式,让用户在点击查看前就能对内容有全面的了解,极大地提升了知识获取的效率和体验。
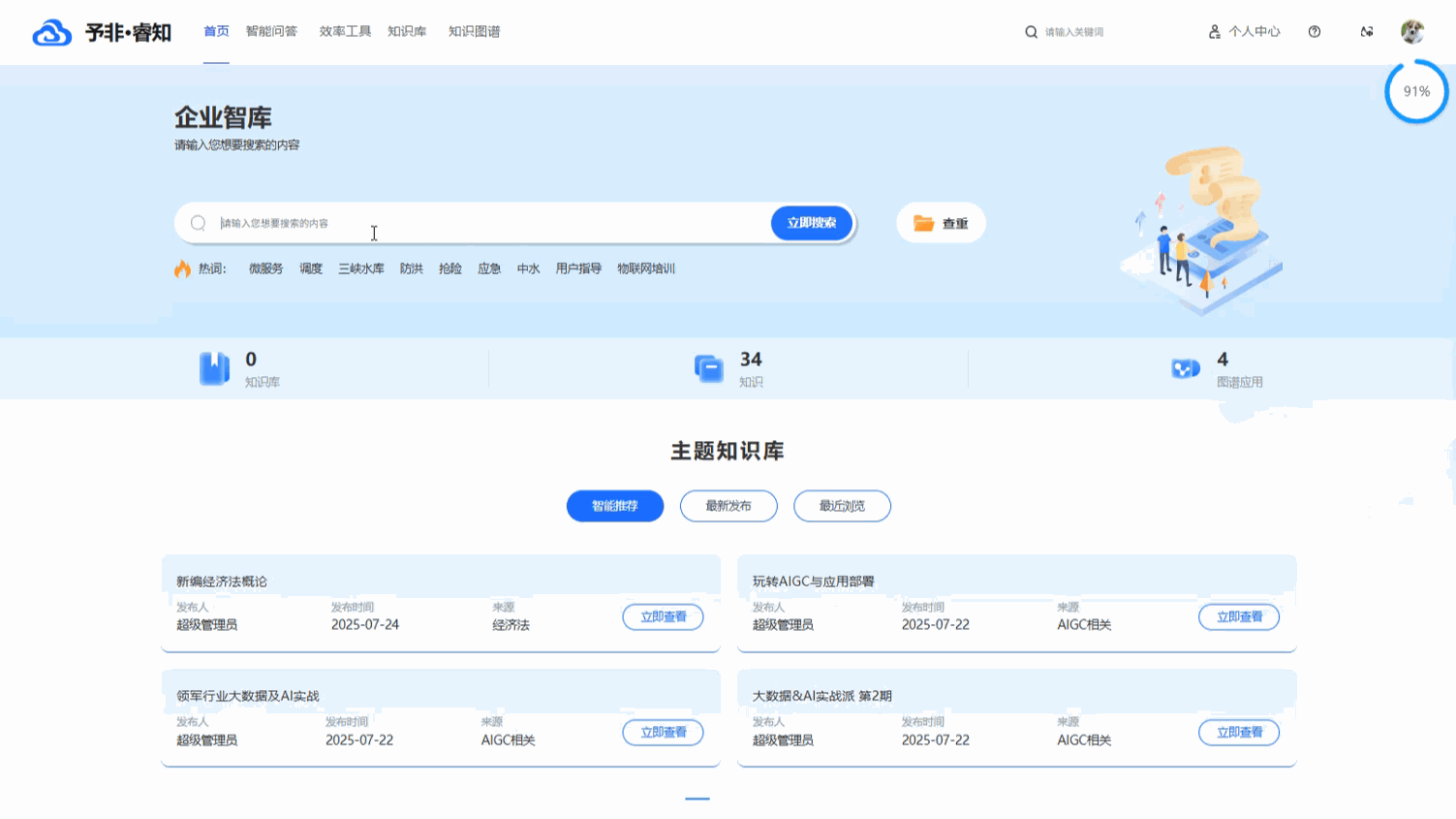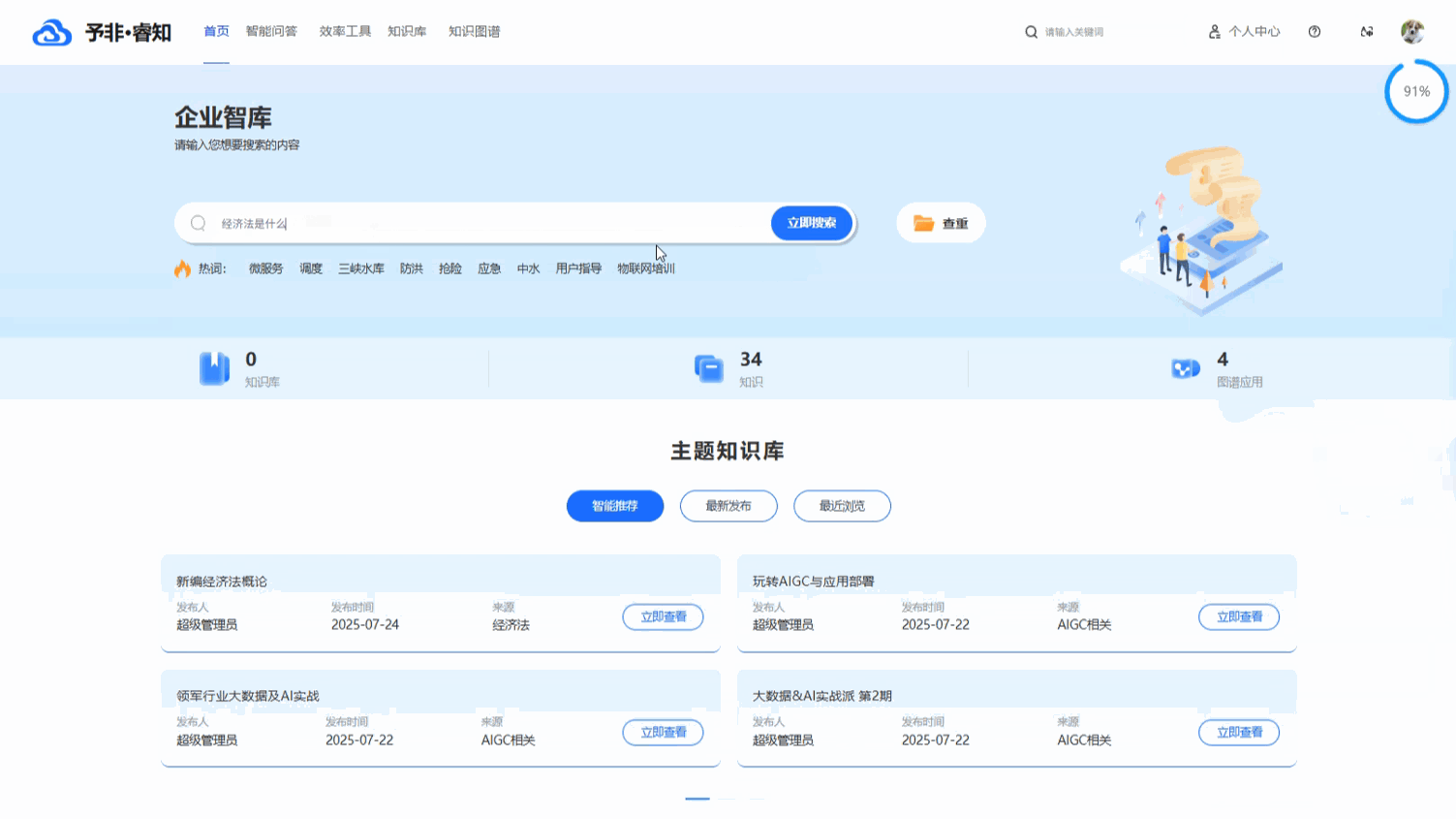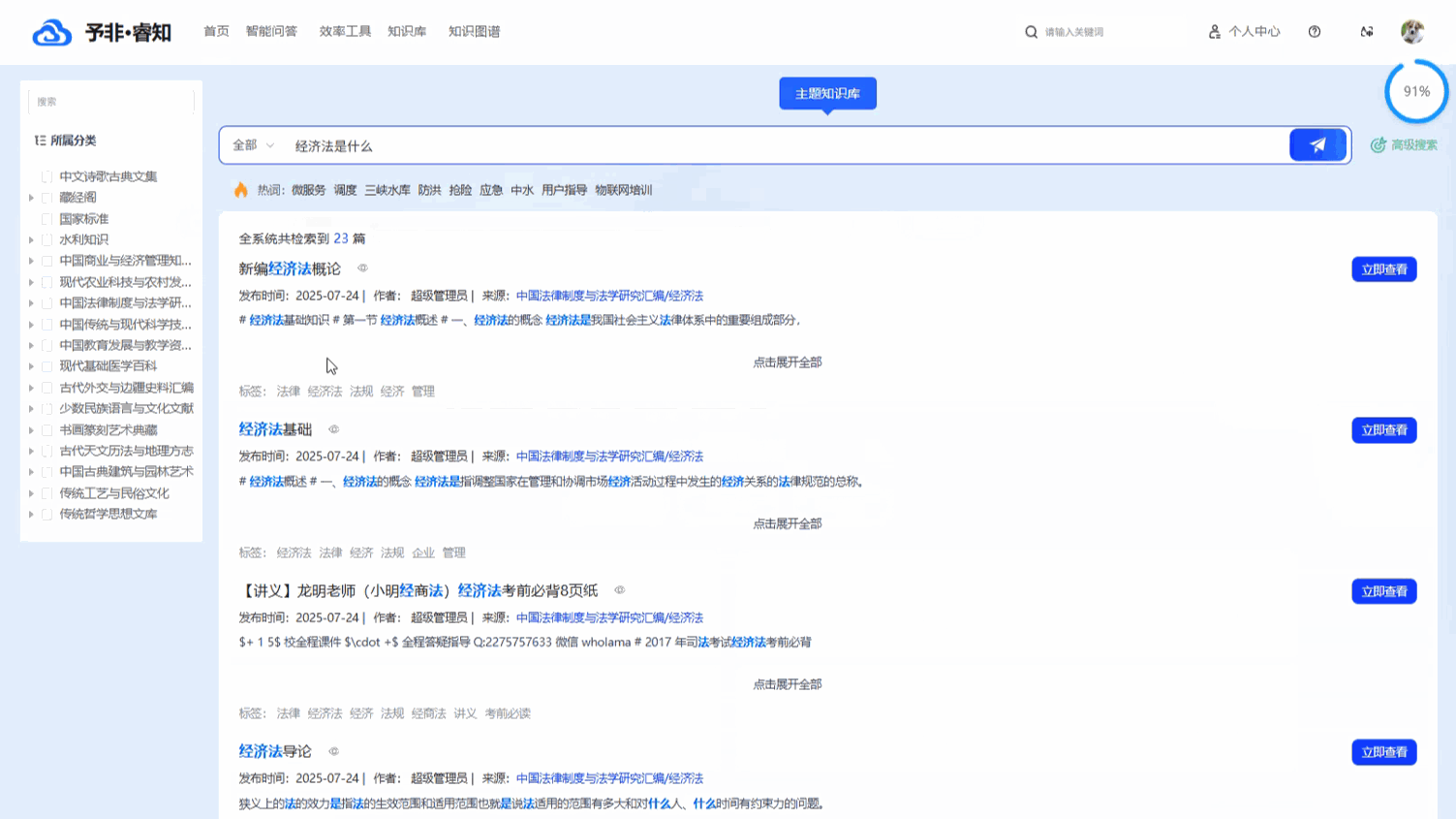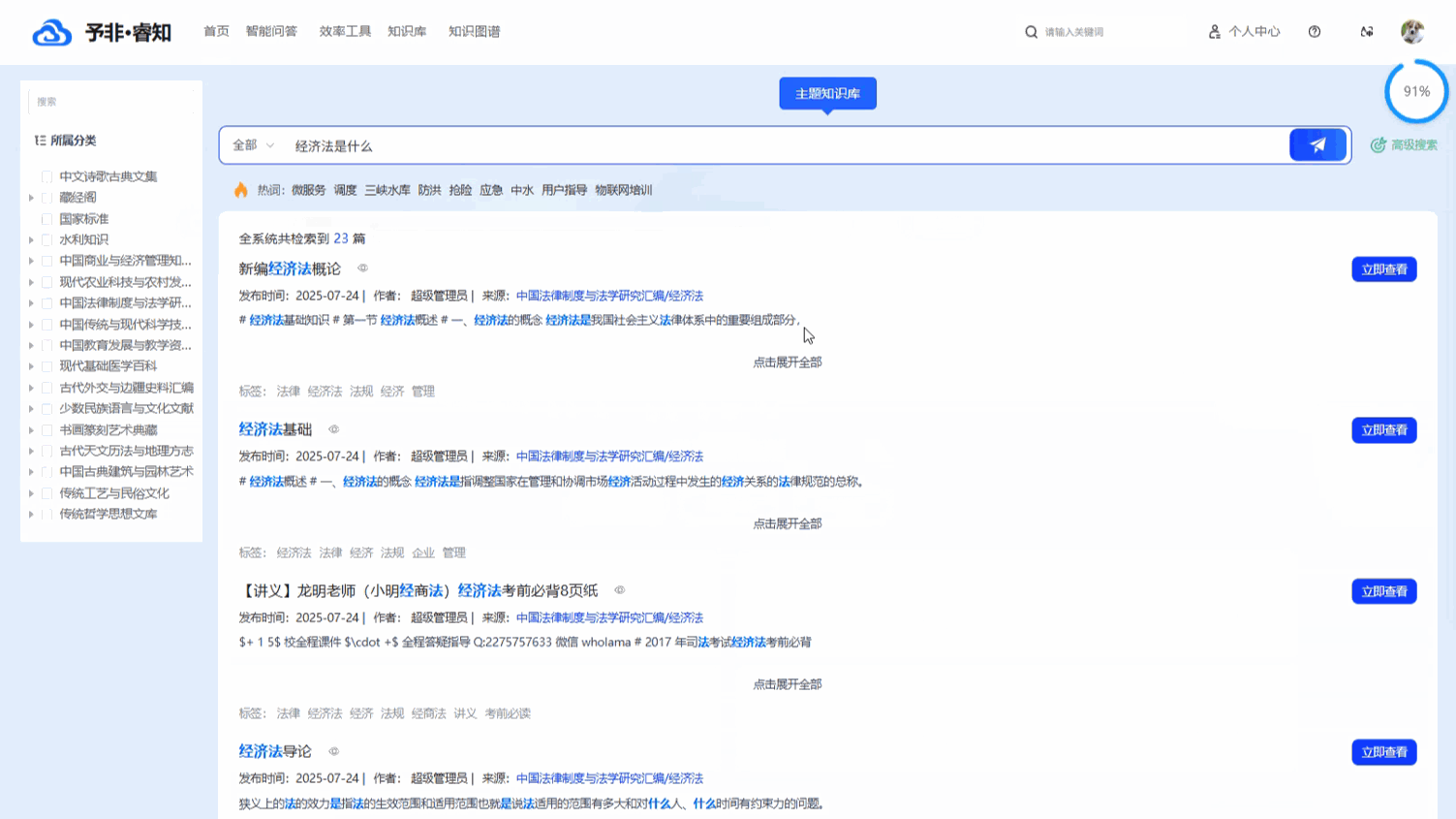
融合语义的智能检索与筛选: 平台的核心搜索功能由先进的 语义搜索 引擎驱动。这意味着系统能够深度理解用户查询的真实意图,而不仅仅是匹配字面上的关键词。即使用户输入的词语与知识库中的文档标题或内容不完全一致,只要在概念上高度相关,系统也能精准地将其找出,从而大幅提升搜索的召回率和准确率。在语义搜索精准锁定相关知识范围的基础上,用户还可以进一步利用 “高级搜索” 功能,根据 文档类型和 时间范围进行多维度筛选,实现从海量数据中快速、精准地触达目标信息。
知识图谱搜索,洞察深层关联: 搜索功能与平台的知识图谱能力深度融合,使用户能够进行超越文本层面的关联和探索。通过 “实体关系对齐” 与 “实体链接” 技术,系统可以在搜索时揭示出知识点之间隐藏的关联。
效率工具
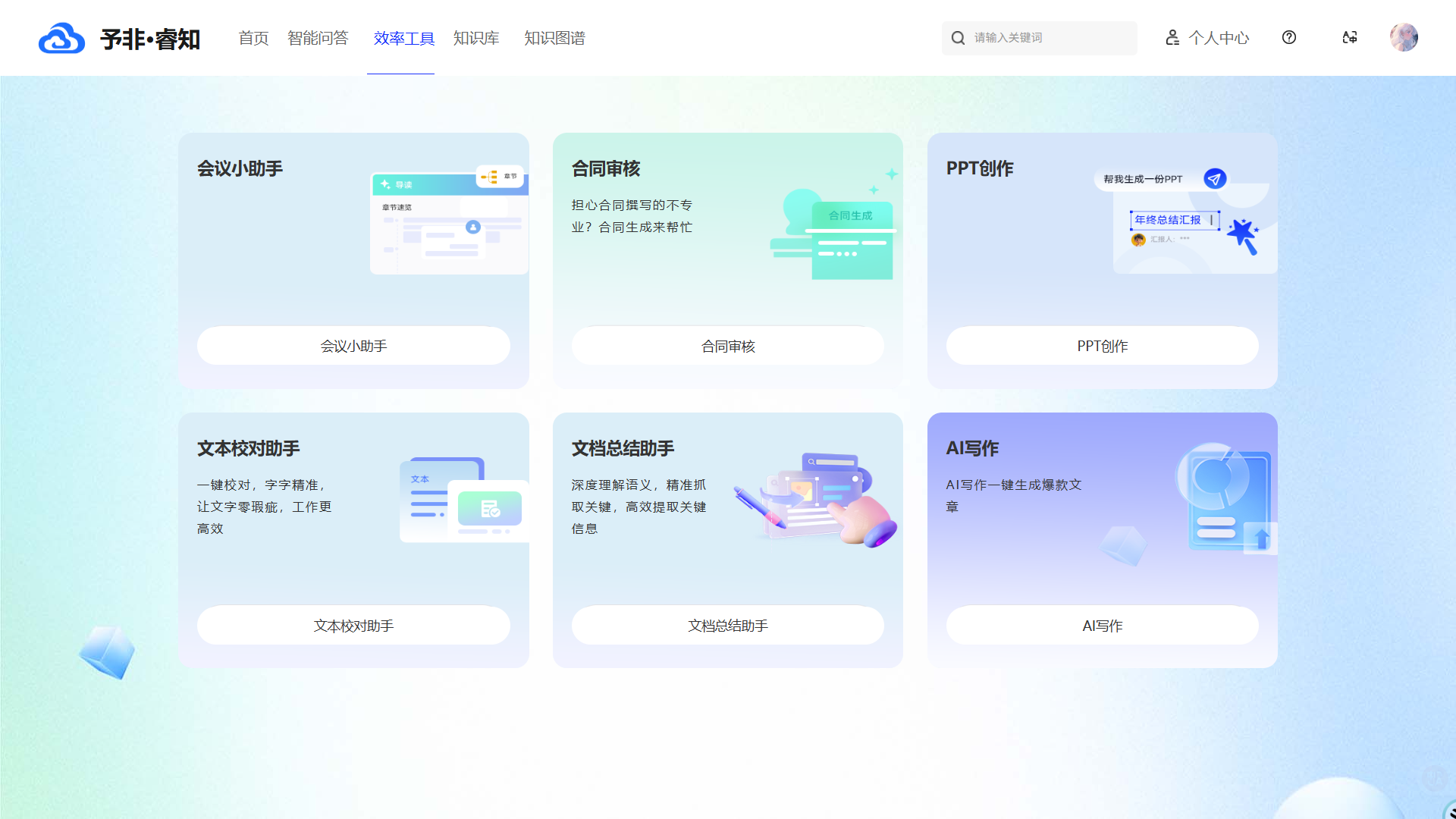
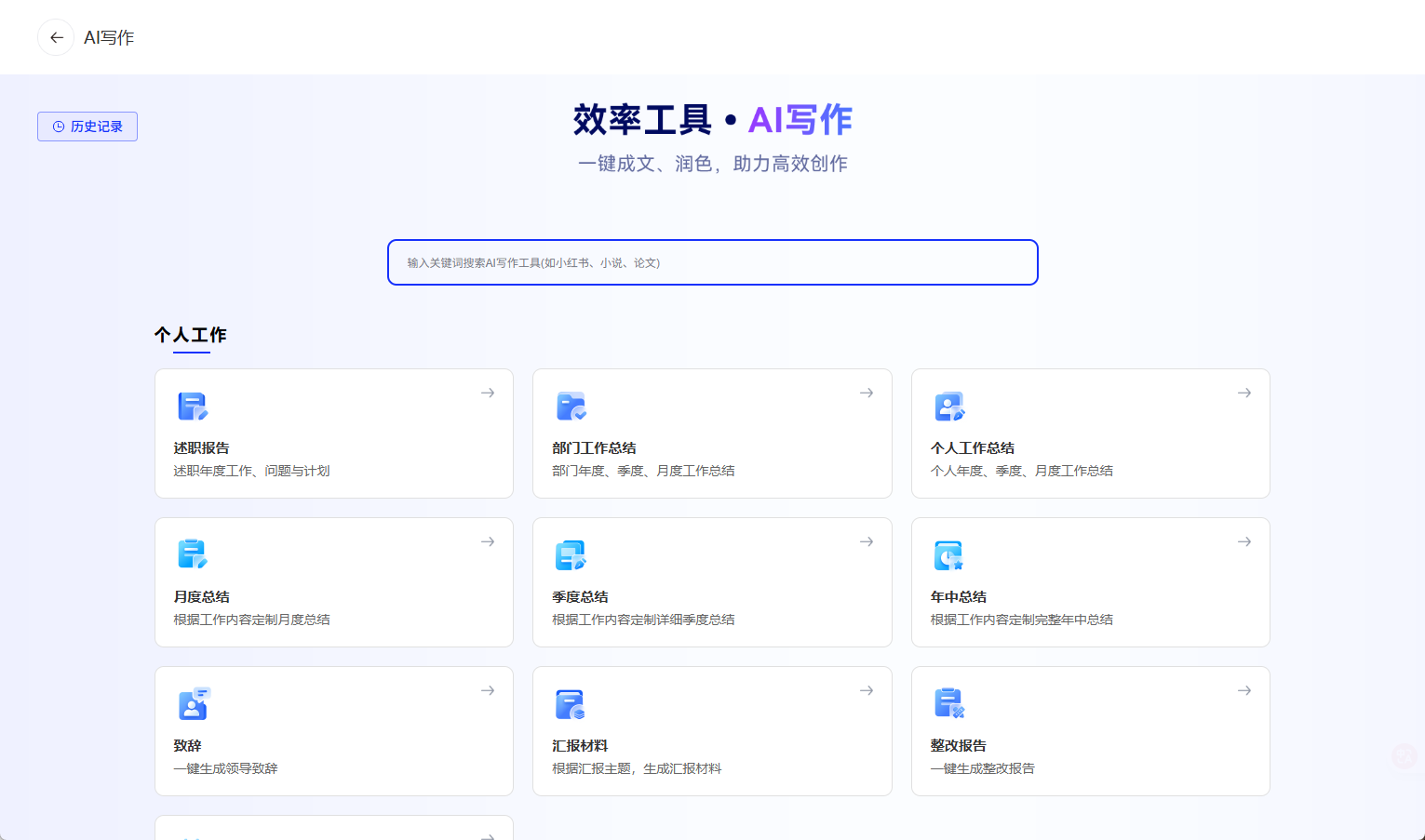
开箱即用的智能化工具: 平台内置了包括AI写作、PPT创成、文本校对、文档总结、合同生成、会议纪要等在内的多种效率工具。这些工具深度融合了大模型能力,能够一键生成高质量的文案、演示稿和分析报告,将员工从繁琐的重复性劳动中解放出来。
私有化部署保证数据安全: 平台深刻理解企业对数据安全的核心关切,支持将所有效率工具模块进行完全的私有化、离线化部署。这意味着企业可以在享受AI带来便利的同时,确保核心数据不出内网,彻底消除数据泄露的风险,为企业的知识资产安全保驾护航。


















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









