



在当今的商业环境中,“数据是资产”已成为共识。然而,如何有效盘活并利用这些资产,却是大多数企业面临的共同难题。企业内部,ERP、CRM、OA等系统中沉淀了海量的运营数据,服务器上存储着数以万计的技术文档、市场报告和会议纪要。这些数据本应是决策的基石、创新的源泉,但现实中它们却常常以“数据孤岛”的形式静默沉睡,难以被高效地查找、关联和利用。
为了搭上AI的快车,一些企业选择了调用外部通用大模型API的路径。这在短期内似乎提供了一条捷径,但随着应用的深入,其固有的挑战也逐渐浮出水面:核心数据的安全顾虑、持续攀升的调用成本、以及通用模型与企业个性化业务场景的“隔阂感”。这些问题,促使企业开始思考一个更根本的问题:有没有一种方式,既能拥抱AI的强大能力,又能将数据安全和技术自主权牢牢掌握在自己手中?
私有化部署的AI知识引擎,正是在这一背景下,作为一种备受关注的解决方案而出现。它致力于在企业内部构建一个专属的“智慧大脑”,实现数据的内部循环与增值。那么,这种模式真的潜力巨大吗?它是否有可能,如标题所探讨的那样,为企业的数据利用率带来高达70%的提升?本文将尝试深入剖析其背后的逻辑。
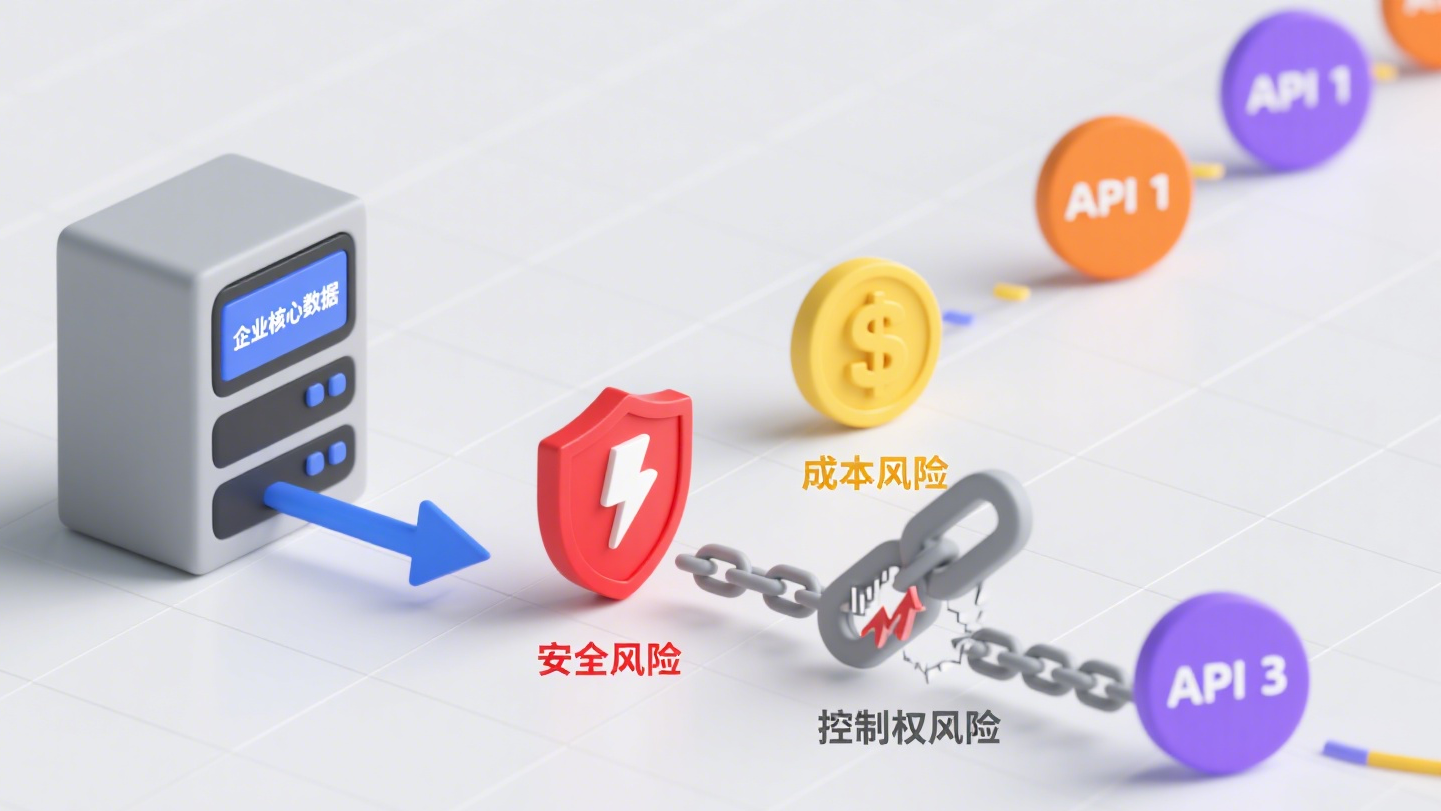
通用API模式,企业AI深化应用中的现实挑战
在客观评估私有化部署的价值之前,我们需要理性地审视当前主流的API调用模式,在企业长期发展中可能会遇到的几大现实挑战。
1. 核心数据的安全与合规边界
数据安全是企业的生命线。当企业将可能包含敏感客户信息、未公开的财务数据、核心技术资料或战略规划的查询内容,通过公网发送至第三方服务商的服务器时,无疑增加了一条潜在的风险链路。尽管服务商会提供安全承诺,但在数据传输、存储和处理的漫长链条中,任何一个环节的疏漏都可能导致难以预估的后果。
2. 从“经济灵活”到“成本失控”的潜在可能
API的按量付费模式,在应用初期或轻度使用场景下,确实显得经济且灵活。然而,当AI应用从“尝鲜”走向“普及”,融入日常办公流程,用户量与调用频率会呈几何级数增长。此时,运营性支出会持续累加,形成一笔可观且难以精确预测的开销。这种模式可能导致企业在AI投入上陷入被动,预算的制定和控制变得更加复杂,与通过AI实现“降本增效”的初衷产生了一定程度的背离。
3. “通用”与“专用”之间的适配鸿沟
大型通用模型知识面广,能力强大,但其设计的初衷是服务于广泛的公共领域。对于企业内部的特定语境,它往往难以做到深度理解。例如,企业内部的项目代号、特定的技术术语、不成文的业务流程、或是长期积累形成的行业“know-how”,这些对于通用模型来说都是陌生的。因此,当员工提出一个深度结合业务场景的问题时,得到的答案可能不够精准,甚至“答非所问”。这种“水土不服”使得AI应用难以真正渗透到业务的核心环节。
4. 技术路线的自主性与长期发展的考量
深度依赖单一外部API,意味着企业自身的AI能力建设与服务商的技术路线、定价策略、服务稳定性高度绑定。服务商的产品迭代方向、API的调整甚至停用,都可能直接影响到企业内部应用的正常运行。从长远战略来看,核心能力的自主可控是企业保持竞争韧性的重要一环,将关键的知识处理流程完全建立在外部供给之上,可能会在未来发展中失去一部分主动权。
一种新的解题思路:构建企业内生的AI知识引擎
面对上述挑战,将AI能力“内化”,让数据在安全可控的环境内发挥价值,成为越来越多企业的选择。“予非·睿知知识引擎平台”便是在这一思路下,为企业提供的一种解决方案。它的核心理念,是通过私有化部署,帮助企业打造一个属于自己的、深度融合业务的知识管理与应用中枢。
什么是私有化部署的AI知识引擎?
简单来说,它是一套可以完整、独立地安装在企业自有服务器、内部网络或专属云环境中的智能系统。整个系统,从数据的存储、索引,到AI模型的计算与推理,再到最终的知识服务呈现,全部在企业的防火墙之内闭环完成。这从物理层面上保障了数据的安全性,使得企业能够放心地将包括核心敏感数据在内的所有知识资产,交由其进行管理和分析。
以“予非·睿知知识引擎平台”为例,它通常具备以下几个核心能力模块:
- 异构数据的统一接入与管理: 平台提供丰富的接口和工具,能够连接并整合企业内部不同来源、不同格式的数据。无论是共享文件夹中的Word、PDF、PPT,还是各类数据库中的业务数据,亦或是邮件、内部沟通工具中的信息流,都可以被汇聚到一个统一的知识库中,为打破“数据孤岛”奠定基础。
- 面向业务场景的深度语义理解: 区别于简单的全文检索,“予非·睿知”这类平台的核心在于其认知智能。它运用先进的自然语言处理技术,能够模拟人类专家的方式去“阅读”和“理解”海量文档内容,抽取关键信息,识别实体、概念及其之间的复杂关系,并以此为基础构建起反映企业特有知识体系的知识网络。
- 自然流畅的人机交互体验: 平台将复杂的AI技术封装在简洁的对话界面之后。任何员工,无论技术背景如何,都可以像使用聊天软件一样,用日常工作语言提出问题。
-
- 例如,研发人员可以问:“关于‘材料A’和‘材料B’在高温高压环境下的性能对比测试报告有哪些?”
- 销售人员可以问:“请总结一下客户‘XYZ公司’过去三年的主要诉求和我们提供的解决方案。”
- 新员工则可以问:“入职培训中,关于报销流程和规范的最新文档在哪里?”
引擎会尝试直接给出提炼后的答案,并附上原文出处,让“人找知识”转变为“知识找人”。
- 超越关键词的精准语义检索: 传统的搜索依赖于关键词匹配,返回的是文档列表,用户需要二次筛选。而语义检索能够理解查询背后的真实意图,即便提问的措辞与原文不完全一致,也能精准定位到最相关的段落、图表或数据,大幅提升知识获取的效率和精准度。
7大价值点解析:数据利用率的提升潜力从何而来?
回到我们最初的问题,70%的提升听起来是一个相当可观的数字。它并非一个精确的承诺,而更像是一个用来衡量其潜在影响力的标尺。那么,这个潜力的增长点究竟源自何处?我们不妨从以下几个维度进行一番逻辑推演。
1. 盘活沉睡的非结构化数据(约占30%的潜力贡献)
行业分析普遍认为,企业数据中约80%是“非结构化数据”,即各类文档、邮件、图片等。这部分蕴含巨大价值的“暗数据”,传统BI工具难以触及。“予非·睿知”这样的知识引擎,其核心能力之一就是深度解析这些非结构化文本。当数万份技术手册、市场分析、法律合同从“静态文件”变为“可查询、可理解的动态知识”时,企业有效数据资产的利用基数本身就得到了极大的扩展。这是实现利用率提升最直接、最基础的一步。
2. 降低数据应用门槛,赋能一线员工(约占20%的潜力贡献)
过去,深度的数据查询与分析工作,往往需要依赖数据分析师或IT部门的协助。知识引擎的自然语言交互界面,将数据的使用权“民主化”了。一线的销售、客服、生产等岗位的员工,可以根据自己的实际工作需要在“第一时间”自助获取决策所需的信息。当数据的应用不再局限于少数“专家”,而是渗透到业务的每一个毛细血管时,数据的价值密度和应用广度自然会成倍增加。
3. 加速知识的沉淀与复用(约占10%的潜力贡献)
员工的经验和智慧,是企业最宝贵的无形资产,但也最容易因人员流动而流失。知识引擎通过对项目文档、问题解决方案、优秀实践案例的持续学习,能够将这些碎片化的、存在于个人大脑中的隐性知识,沉淀为组织可复用的显性资产。这有效减少了“重复造轮子”的现象,加速了新员工的学习曲线,提升了整个组织的知识传承效率。
4. 促进跨域的关联与洞察(约占10%的潜力贡献)
知识引擎的更高阶价值,在于通过知识图谱等技术,揭示不同数据点之间隐藏的关联。它可能会发现,不同部门看似无关的研究,其实指向同一个技术突破口;或者,某个产品的售后问题,其根源可以追溯到供应链的某个环节。这种跨领域、跨部门的关联洞察,是创新的催化剂,也是数据利用从“支撑运营”到“驱动创新”的质变。
将这几个方面的潜力相加(30% + 20% + 10% + 10%),我们便得到了70%这个理想化的增长模型。需要强调的是,这并非一个可以简单套用的公式,实际效果与企业的数据基础、业务复杂度及推广应用的深度紧密相关。但这个推演清晰地展示了一条路径:数据利用率的显著提升,来源于对数据范围、使用人群、复用效率和洞察深度的全方位拓展。
结语:从“拥有数据”到“善用智慧”的战略选择
在数字化转型的深水区,企业间的竞争,正越来越多地表现为对数据和知识的运用能力的竞争。依赖外部通用API或许是一条看似平坦的道路,但构建自主可控的内部智能中枢,则更像是在打造一条能够通向未来的、更坚实的基石。
“予非·睿知知识引擎平台”所代表的私有化部署方案,为企业提供了一种兼顾安全、自主与智能的战略选择。它不仅仅是一个IT工具的升级,更是一种管理思维的转变——推动企业从仅仅“拥有数据”,迈向真正地“善用智慧”。
若您的企业也正面临数据孤岛、知识流失或AI应用难以深入的挑战,不妨将目光投向内部,思考如何构筑属于自己的、真正服务于业务的AI知识引擎。这或许正是开启下一轮增长的关键所在。


















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









