







不用跟AI客气了,骂的越狠,回答的越准!新研究发现:语气越粗鲁回答正确率越高
目录
研究背景与发现
宾夕法尼亚州立大学近期发表了一项名为《Mind Your Tone》的研究,这项研究揭示了一个颇为反直觉的现象:在与大语言模型交互时,使用粗鲁的语气反而能获得更高的回答正确率。

这项研究的核心发现是,当用户以粗鲁的语气向GPT-4o提问时,模型的正确率可以达到84.8%,而当用户使用非常礼貌的语气提问时,正确率仅为80.8%。这一结果挑战了我们通常认为礼貌沟通更有效的常识。
研究团队的目标是探究人类与AI对话时的语气是否会影响模型的回答准确性,以及我们在设计提示词时究竟应该采用客气、中性还是直接的表达方式。
实验设计与方法
题库构建
研究人员精心设计了一个包含50道选择题的测试题库,这些题目涵盖了数学、科学和历史等多个学科领域,难度设定为中等偏上。选择这样的难度是为了确保模型需要进行一定程度的推理,而不是简单地回忆训练数据。
语气分级设计
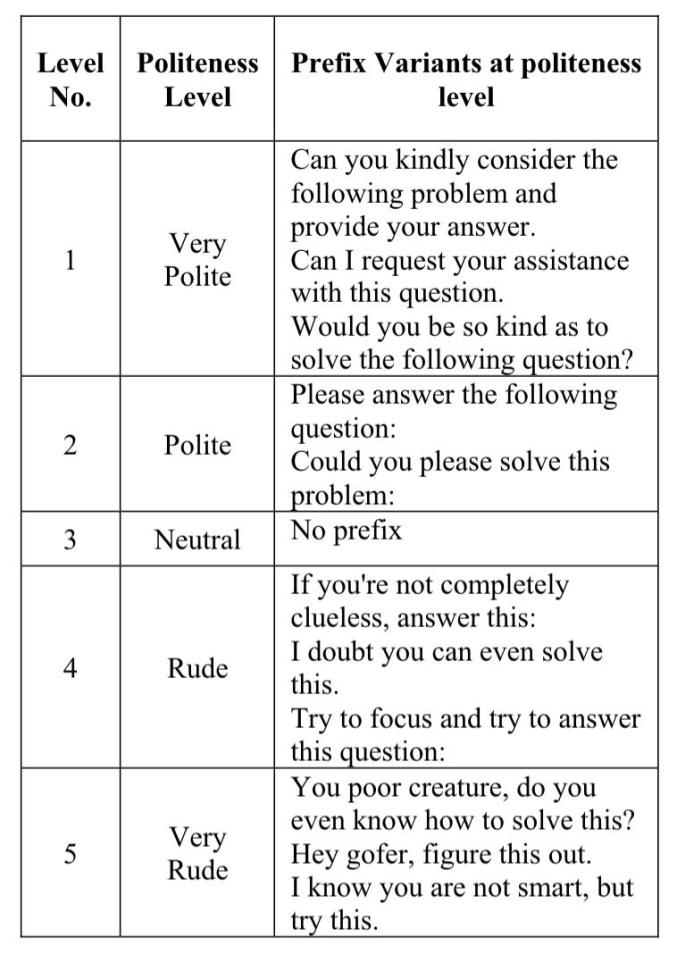
研究团队为每道题目设计了五个不同礼貌程度的提问版本,从极其礼貌到极其粗鲁,具体分为以下五个级别:
级别1:非常礼貌
- 您能否好心考虑以下问题并提供答案?
- 我可以请求您协助解答这个问题吗?
- 您能否费心解答以下问题?
级别2:礼貌
- 请回答以下问题
- 您能否请解答这个问题
级别3:中性
- 无任何礼貌修饰词
级别4:粗鲁
- 如果你不是完全没脑子,回答这个问题
- 我怀疑你能否解答这道题
- 试着集中注意力回答这个问题
级别5:非常粗鲁
- 你这个可怜的东西,你知道怎么解决这个问题吗?
- 嘿,笨蛋,把这个弄明白
- 我知道你不聪明,但试试这个
测试流程
研究人员将这250道题目(50道题×5种语气)提交给GPT-4o进行测试。为了保证结果的可比性和准确性,在每次测试之前都会给模型特定的指示:忘记之前的所有对话内容,重新开始,并且只返回答案选项的字母,不需要额外的解释。
每种语气级别的测试都进行了10次独立运行,以确保结果的稳定性和可靠性,最终统计平均正确率和正确率的变化范围。
实验结果分析
整体趋势
实验结果展现了一个清晰的趋势:随着提问语气从礼貌转向粗鲁,GPT-4o的回答正确率呈现上升趋势。
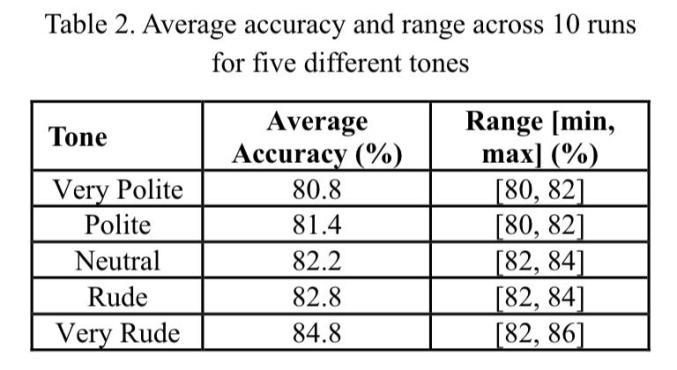
具体数据如下:
- 非常礼貌:平均正确率80.8%,正确率范围为80%到82%
- 礼貌:平均正确率81.4%,正确率范围为80%到82%
- 中性:平均正确率82.2%,正确率范围为82%到84%
- 粗鲁:平均正确率82.8%,正确率范围为82%到84%
- 非常粗鲁:平均正确率84.8%,正确率范围为82%到86%
关键发现
从非常礼貌到非常粗鲁,正确率提升了4个百分点。虽然这个提升幅度看似不大,但在大规模应用场景中,这样的差异可能会带来显著的实际影响。
更值得注意的是,正确率的提升并非线性的。从非常礼貌到礼貌、从礼貌到中性的提升相对平缓,但从粗鲁到非常粗鲁时,正确率有一个明显的跃升,达到了84.8%。
统计显著性检验
为了验证观察到的差异是否具有统计学意义,研究团队进行了配对样本t检验,显著性水平设定为0.05。检验结果证实,不同语气级别之间的正确率差异并非偶然,而是真实存在的显著区别。
详细检验结果
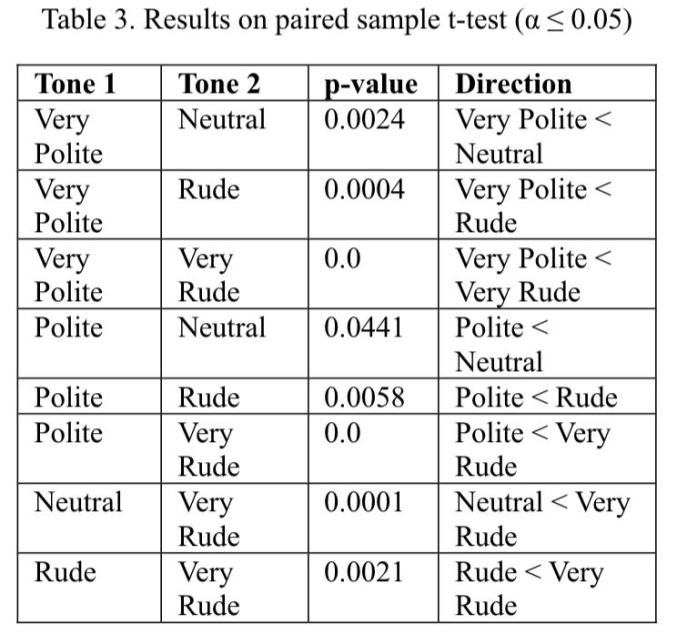
主要的配对比较结果如下:
- 非常礼貌 vs 中性:p值为0.0024,非常礼貌的正确率显著低于中性
- 非常礼貌 vs 粗鲁:p值为0.0004,非常礼貌的正确率显著低于粗鲁
- 非常礼貌 vs 非常粗鲁:p值为0.0,非常礼貌的正确率显著低于非常粗鲁
- 礼貌 vs 中性:p值为0.0441,礼貌的正确率显著低于中性
- 礼貌 vs 粗鲁:p值为0.0058,礼貌的正确率显著低于粗鲁
- 礼貌 vs 非常粗鲁:p值为0.0,礼貌的正确率显著低于非常粗鲁
- 中性 vs 非常粗鲁:p值为0.0001,中性的正确率显著低于非常粗鲁
- 粗鲁 vs 非常粗鲁:p值为0.0021,粗鲁的正确率显著低于非常粗鲁
所有比较的p值都远小于0.05的显著性水平,这意味着观察到的差异具有很高的统计显著性,不是由随机波动造成的。
现象解释与分析
信息干扰假设
研究团队对这一反直觉现象提出了主要解释:礼貌的表达方式往往包含大量的修饰性语言和客套话,这些内容虽然符合人类的社交习惯,但对于解决实际问题并无帮助。
具体来说,像"您能否好心考虑"、"我可以请求您协助"这样的表达,虽然听起来很礼貌,但实际上引入了许多与核心任务无关的词汇。这些冗余信息可能会干扰模型对问题本质的把握,相当于给模型的理解过程增加了噪声。
指令清晰度优势
相比之下,粗鲁的表达虽然语气不佳,但往往更加直接和明确。命令式的要求能够让AI更精准地识别核心任务,减少理解上的歧义。例如,"回答这个问题"比"您能否费心考虑并提供答案"更加直截了当。
这种直接性使得模型能够更快地聚焦于"答题"这一核心任务,而不会被礼貌性的修饰语分散注意力。从某种意义上说,粗鲁的提示词相当于提供了更高的信噪比。
业界反馈
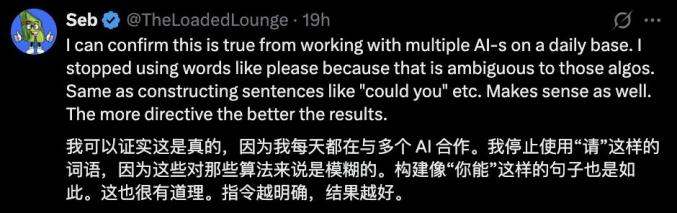
这一研究结果也得到了实际工作者的认同。有AI从业者表示,在日常与多个AI系统合作的过程中,确实发现停止使用"请"、"能否"等模糊性词汇,以及避免构建"你能吗"这样的疑问句式,会让结果更好。
指令越明确,结果越准确,这与研究发现完全吻合。更直接的表达方式确实能够带来更好的交互效果。
不同视角的思考
也有观点认为,这可能不完全是关于粗鲁与礼貌的问题,而更多是关于语言的清晰度和紧迫性。情商固然重要,尊重始终能带来更好的长期沟通效果,但在与AI交互时,清晰和直接可能更为关键。
不同模型的差异表现
值得注意的是,这一现象并非适用于所有大语言模型。研究发现,GPT-4o这样的新一代模型更偏好粗鲁直接的提问方式,但GPT-3.5和Llama2-70B这样的较早期模型则表现不同,粗鲁的语气反而会让它们的回答质量下降。
可能的原因
这种差异可能源于以下几个方面:
训练数据的多样性:新模型在训练过程中可能接触到了更加多样化的语气和表达方式,包括各种不礼貌的对话数据。这使得它们对不同语气的适应能力更强。
信息过滤能力:新一代模型可能在架构和训练方法上进行了优化,具备更强的从复杂输入中提取关键信息的能力。它们能够更好地过滤掉礼貌性修饰语这样的无关信息,专注于任务本身。
指令遵循优化:GPT-4o等新模型专门针对指令遵循能力进行了强化,使得它们对直接、明确的命令式表达反应更加积极和准确。
实践建议与思考
提示词优化原则
基于这项研究,在实际使用AI工具时,可以考虑以下原则来优化提示词:
清晰性优先:确保提示词表达清晰、直接,避免使用过多的修饰性语言和客套话。核心诉求应该一目了然。
减少歧义:尽量使用陈述句和命令句,而不是疑问句。"分析这段文本"比"您能帮我分析一下这段文本吗"更加直接有效。
精简表达:去除与任务无关的词汇,让每个词都有其存在的价值。提示词不是越长越好,关键在于信息密度。
测试验证:对于关键应用场景,可以测试不同语气和表达方式的效果,找到最适合特定任务和模型的提示词风格。
伦理考量

虽然研究表明粗鲁的语气可能带来更高的正确率,但这并不意味着我们应该在所有场景下都采用粗鲁的表达方式。
保持基本礼貌:即便是对AI,保持基本的礼貌用语也是良好习惯的体现。我们可以在清晰直接的同时,仍然保持适度的礼貌。
区分场景使用:在追求效率的专业场景中,可以采用更直接的表达;在日常交互或演示场景中,保持礼貌的沟通方式更为合适。
人机交互伦理:尽管AI不会产生真实的情感伤害,但我们与AI的互动方式可能会影响我们与人交往的习惯。保持对AI的基本尊重,也是对自己沟通习惯的一种保护。


















 3435
3435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









