







 文章详细介绍了查找运算中的顺序查找和二分查找算法,包括它们的基本思想、比较次数、平均查找长度的计算以及在不同情况下的性能。重点讨论了顺序查找的平均长度及二分查找的最优性能。
文章详细介绍了查找运算中的顺序查找和二分查找算法,包括它们的基本思想、比较次数、平均查找长度的计算以及在不同情况下的性能。重点讨论了顺序查找的平均长度及二分查找的最优性能。
查找,又称搜索,检索。
查找运算的主要操作是关键字的比较, 通常把查找过程中的平均比较次数(也称为平均查找长度) 作为衡量一个查找算法效率优劣的标准。
平均查找长度(Average Search. Length ASL) 的计算公式为
A S L = ∑ i = 1 n P n C i ASL = \sum\limits_{i=1}^{n} P_{n}C_i ASL=i=1∑nPnCi
其中,
n
n
n 为结点的个数,
P
i
P_i
Pi 是查找第
i
i
i 个结点的概率。
在本文,设定查找每个结点是等概率的, 即
P
1
=
P
2
=
.
.
.
=
P
i
=
1
n
P_1 = P_2 = ...=P_i = \frac{1}{n}
P1=P2=...=Pi=n1 ;
C
i
C_i
Ci 为找到第
i
i
i 个结点所需要比较的次数。 因此,平均查找长度计算公式可简化为
A S L = 1 n ∑ i = 1 n C i ASL =\frac{1}{n} \sum\limits_{i=1}^{n} C_i ASL=n1i=1∑nCi
一 顺序表的查找
顺序表是指线性表的顺序存储结构。
在顺序表上的查找方法有多种, 我介绍最常用、最主要的两种方法
————————————————————————————
1.1 顺序查找
顺序查找 又称线性查找。其基本思想是: 从表的一端开始, 顺序扫描线性表, 依次把扫描到的记录关键字与给定的值 k k k 相比较, 若某个记录的关键字等于 k k k, 则查找成功, 返回该记录所在的下标; 若直到所有记录都比较完, 仍未找到关键字 与 k k k 相等的记录, 则表明查找失败, 返回 -1。
以java 为例, 看一个demo.
public static int sequentialSearch(int[] array, int key) {
for (int i = 0; i < array.length; i++) {
if (array[i] == key) {
return i; // 找到元素,返回其索引
}
}
return -1; // 如果没有找到,返回-1
}
这个算法 若循环终止于
i
>
0
i>0
i>0, 查找成功, 当
i
=
n
i=n
i=n, 则比较次数
C
n
=
n
C_n = n
Cn=n,
一般情况下
C
i
=
i
+
1
C_i = i+1
Ci=i+1 。
有2个结论:
- 顺序查找成功时的平均查找长度约为表长的一半(假定查找某个记录是等概率)。
- 顺序查找的平均查找长度: 3 ( n + 1 ) 4 \frac{3(n+1)}{4} 43(n+1)
~~
假设要查找的顺序表是按关键字递增有序的,用上述算法同样可以实现, 但是表有序的条件就没用上,可用下面的算法来实现:
public int seqSearch_advance(int[] array, int k){
int i= array.length;
while(array[i] > k){
i--;
}
if(array[i] == k){
return i;
}
return -1;
}
循环语句判断当要查找值 k k k 小于表中当前关键字值时,向前查找。
该算法在查找失败时, 对于无序表的查找长度是 n + 1 n + 1 n+1, 而该算法的平均查找长度则是表长的一半, 因此该改进后的算法的平均查找长度是 n + 1 2 \frac{n+1}{2} 2n+1.
——————————————————————————————
1.2 二分查找
二分查找 (Binary Search) 又叫折半查找, 是一种效率较高的查找方法。
二分查找的前提: 查找对象的线性表必须是顺序存储结构的有序表。 在本文我们假设递增有序
二分查找的过程是: 首先将待查的
k
k
k 值和有序表
R
[
1..
n
]
R[1..n]
R[1..n] 的中间位置 mid上的记录的关键字进行比较,
若相等,则查找成功;
若
R
[
m
i
d
]
>
k
R[mid] > k
R[mid]>k, 则
k
k
k 在左子表
R
[
1..
m
i
d
−
1
]
R[1..mid-1]
R[1..mid−1]中, 接着再在左子表中进行二分查找即可;
若
R
[
m
i
d
]
<
k
R[mid] < k
R[mid]<k, 则
k
k
k 在右子表
R
[
m
i
d
+
1..
n
]
R[mid+1..n]
R[mid+1..n]中, 接着再在右子表中进行二分查找即可;
这样,经过一次关键字的比较, 就可缩小一半的查找空间, 如此进行下去,直到找到关键字为
k
k
k 的记录 或者查找失败。
二分查找的过程是递归的, 其递归算法描述如下:
以java为例,看demo:
/***
* 二分查找, 这里有一个前提,待查找的表 必须是递增有序表
*/
public class BinarySearchRecursive{
public static int search(int[] array, int k, int low, int high) {
if (low > high) {
return -1; // 未找到目标值,返回-1
}
int mid = low + (high - low) / 2;
if (array[mid] == k) {
return mid; // 找到目标值,返回索引
} else if (k < array[mid]) {
return search(array, k, low, mid - 1);
} else {
return search(array, k, mid + 1, high);
}
}
public static void main(String[] args) {
int[] array = {9, 11, 13, 15, 17};
int k = 15;
int index = search(array, k, 0, array.length - 1);
if (index != -1) {
System.out.println("找到目标值,索引为 " + index);
} else {
System.out.println("目标值不在数组中");
}
}
}
二分查找也可以用非递归方法来实现,那就是用
w
h
i
l
e
(
l
o
w
<
=
h
i
g
h
)
循
环
while(low<=high) 循环
while(low<=high)循环, 其算法如下:
/***
* 二分查找, 这里有一个前提,待查找的表必须是递增有序表
* 2024
*/
public class BinarySearch{
public static int search(int[] array, int k) {
int low = 0;
int high = array.length - 1;
while(low<=high){
int mid = low + (high - low) / 2;
if (array[mid] == k) {
return mid; // 找到目标值,返回索引
} else if (k < array[mid]) {
//如果关键字k小于当前列表中间值,说明要在左子表中查找,所以将high改小, 在左子表中继续找
high = mid - 1;
} else {
//如果关键字k大于当前列表中间值,说明要在右子表中查找,所以将low改大,在右子表中继续找
low = mid + 1;
}
}
return -1;
}
public static void main(String[] args) {
int[] array = {9, 11, 13, 15, 17};
int k = 15;
int index = search(array, k);
if (index != -1) {
System.out.println("找到目标值,索引为 " + index);
} else {
System.out.println("目标值不在数组中");
}
}
}
程序运行结果如下:

二. 查找的结论
先看一个图
序号 1 2 3 4 5
值 9 11 13 15 17
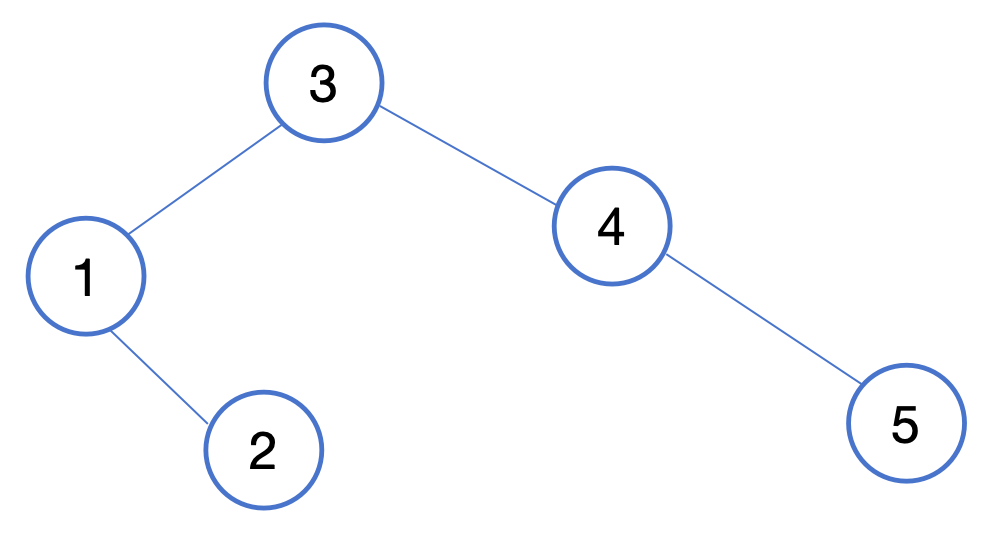
长度为5的有序表二分查找判定树
二分查找算法在查找成功时,进行关键字比较的次数不超过判定树的深度。
假设有序表的长度
n
=
2
h
−
1
,
h
=
l
o
g
2
(
n
+
1
)
n = 2^h - 1, h = log_2(n+1)
n=2h−1,h=log2(n+1), 假设每条记录的查找概率相等, 即
P
i
=
1
n
P_i = \frac{1}{n}
Pi=n1,
则查找成功时二分查找的平均长度为
A
S
L
=
n
+
1
n
l
o
g
2
(
n
+
1
)
−
1
ASL = \frac{n+1}{n}log_2(n+1) - 1
ASL=nn+1log2(n+1)−1
当
n
n
n 很大时,近似公式为
A
S
L
=
l
o
g
2
(
n
+
1
)
−
1
ASL = log_2(n+1) -1
ASL=log2(n+1)−1
当二分查找失败时, 所需要比较的关键字个数不超过判定树的深度。
二分查找的最坏性能和平均性能相当接近。
看一个例题:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









