




1、RDMA
1.1、系统框架
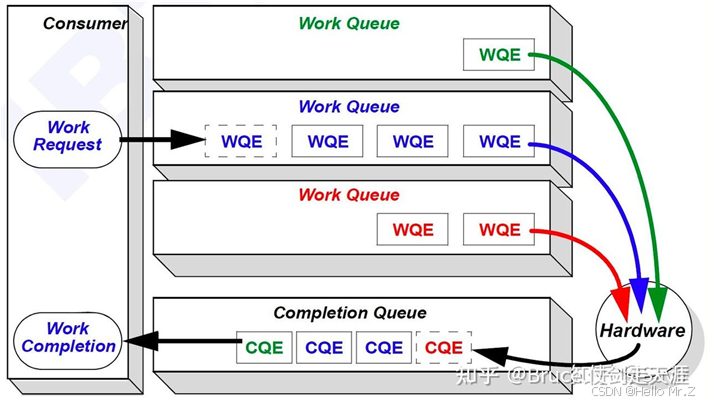
- WQ(Work Queue):存储工作请求的队列,包含多个WQE。软件通过WQ向硬件下发任务,硬件从WQ中取出WQE执行;
- WQE(Work Queue Element):工作队列元素,是软件提交给硬件的具体任务描述(如发送/接收数据的地址、长度等);
- QP(Queue Pair):由发送队列(SQ)和接收队列(RQ)组成,是RDMA通信的基本单位,用于双向数据传输;
- SQ(Send Queue):存放发送任务的队列,包含发送操作的WQE(如RDMA_Write、Send等);
- RQ(Receive Queue):存放接收任务的队列,包含预分配的接收缓冲区地址(RQ WQE);
- CQ(Completion Queue):存储硬件完成任务的通知(CQE),用于软件轮询或中断确认操作状态;
- SRQ(Shared Receive Queue):多个QP共享的接收队列,减少内存和硬件资源占用;
- CQE(Completion Queue Element):完成队列元素,记录操作状态(成功/失败)和类型;
- MR(Memory Region):内存区域;
- 发送流程:应用程序提交WQE到QP的SQ -> 触发Doorbell通知硬件 -> 硬件执行操作 -> 生成CQE到CQ;
- 接收流程:应用程序预分配接收缓冲区并提交WQE到RQ(或SRQ) -> 硬件将远端数据写入指定缓冲区 -> 生成CQE到CQ。
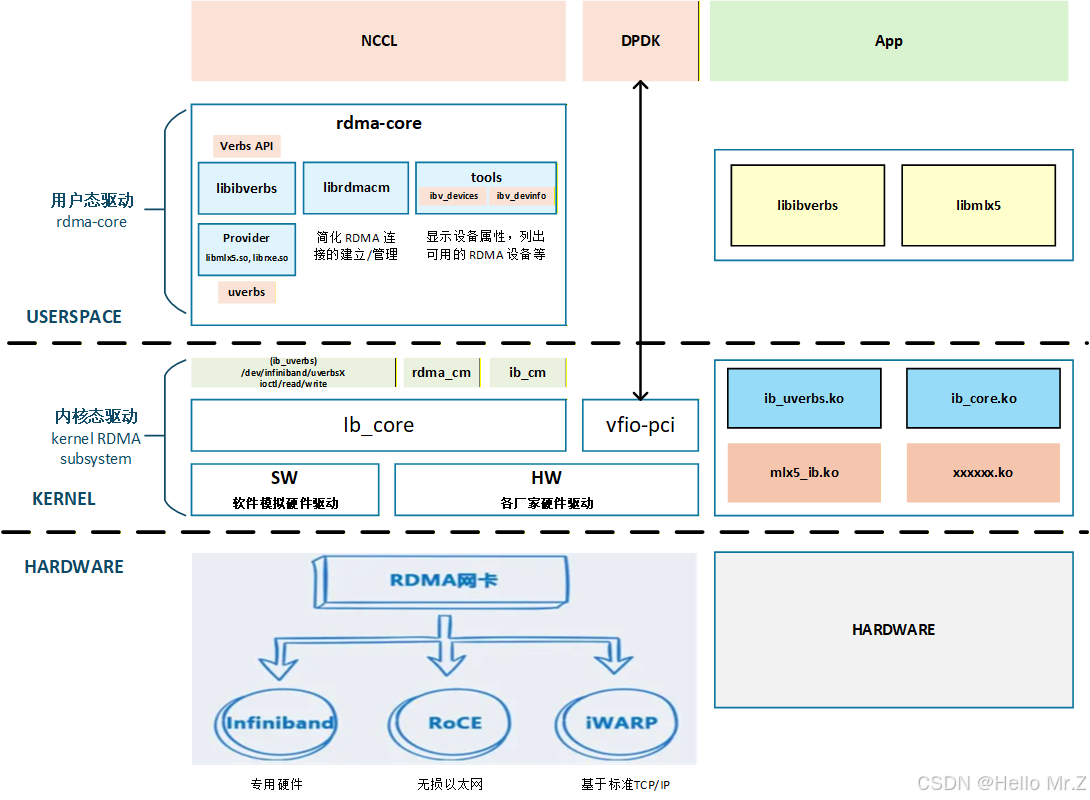
- 用户态驱动:https://github.com/linux-rdma/rdma-core
- 内核态驱动:Linux内核代码drivers/infiniband目录下
- OFED(OpenFabrics Enterprise Distribution):厂家的开源软件包集合,其中包含内核框架和驱动、用户框架和驱动、以及各种中间件、测试工具和API文档。开源OFED由OFA组织负责开发、发布和维护,它会定期从rdma-core和内核的RDMA子系统取软件版本,并对各商用OS发行版进行适配。除了协议栈和驱动外,还包含了perftest等测试工具
- libibverbs提供verbs api,librdmacm提供rdma_cm api,rdma_cm是对verbs的再次封装
- 用户态api前缀为“ibv_”、“rdma_”,内核态api前缀为“ib_”
- DPDK:是一个开源工具集,用于在标准CPU上快速处理网络数据包,绕过了操作系统的内核,大幅提升网络性能Linux网络编程之dpdk实现用户态协议栈
1.2、qemu测试环境搭建
vmware版本:VMware® Workstation 17 Pro
ubuntu版本:ubuntu-24.04.3-desktop-amd64.iso
1.2.1、安装vmware-tools:
sudo apt update
sudo apt upgrade
sudo apt-get install open-vm-tools-desktop -y1.2.2、打开vmware虚拟机支持:
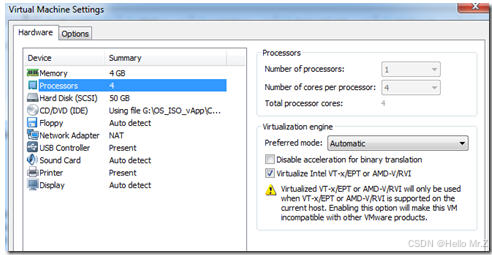
如果显示黄色叹号,修改对应的.vmx文件,增加语句apic.xapic.enabled=FALSE,然后重启
1.2.3、安装qemu:
sudo apt install qemu-system-x86 cloud-image-utils
kvm-ok
# 期望输出包含 "KVM acceleration can be used"。1.2.4、(推荐) 将用户添加到 kvm 组,这样可以无需 sudo 运行某些 QEMU 操作:
sudo usermod -aG kvm $(whoami)重要提示: 可能需要注销并重新登录或者重新连接ssh,用户组的更改才能生效
1.2.5、下载 Ubuntu Cloud Image
# 创建工作目录
mkdir -p ~/rdma_vm_setup && cd ~/rdma_vm_setup
# 下载 cloud image (qcow2 格式)
wget https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img1.2.6、创建差分磁盘镜像 (Backing File)
为了不直接修改原始的 cloud image(便于复用),我们创建一个基于它的差分镜像。对虚拟机的所有磁盘写入将保存在这个新镜像中。
qemu-img create -f qcow2 -F qcow2 -b noble-server-cloudimg-amd64.img my-ubuntu.qcow2 40G -f qcow2: 新镜像的格式。
-F qcow2: 后备镜像 (backing file) 的格式。
-b noble-server-cloudimg-amd64.img: 指定后备镜像。
my-ubuntu.qcow2: 新创建的差分镜像文件名。
40G: 差分镜像的最大可增长大小。
1.2.7、准备 cloud-init 用户数据和元数据
cloud-init 使用 user-data 和 meta-data 文件来配置虚拟机。
meta-data.yaml (元数据):
cat > meta-data.yaml <<EOF
instance-id: ubuntu-$(date +%s)
local-hostname: ubuntu-vm
EOF 这定义了实例ID和虚拟机在网络中可见的主机名。
user-data.yaml (用户数据):
# 如果 ~/.ssh/id_rsa.pub 不存在,请先通过 ssh-keygen 生成
if [ ! -f ~/.ssh/id_rsa.pub ]; then ssh-keygen -t rsa -b 4096; fi
cat > user-data.yaml <<EOF
#cloud-config
password: ubuntu # 设置用户密码 (可选)
chpasswd: { expire: False } # 密码永不过期
ssh_pwauth: true # 允许密码认证 (可选,推荐使用公钥认证)
ssh_authorized_keys:
- $(cat ~/.ssh/id_rsa.pub)
EOF1.2.8、创建 cloud-init 数据源镜像 (seed.img)
cloud-localds seed.img user-data.yaml meta-data.yaml这将创建一个名为 seed.img 的小镜像,QEMU 会将其作为 CD-ROM 提供给虚拟机,cloud-init 会从中读取配置。
1.2.9、启动QEMU虚拟机
# 在宿主机上创建一个用于共享的目录
mkdir -p ~/shared_with_vm
qemu-system-x86_64 \
-enable-kvm \
-cpu host \
-smp $(nproc) \
-m 4G \
-drive file=my-ubuntu.qcow2,format=qcow2,if=virtio \
-drive file=seed.img,format=raw,if=virtio \
-netdev user,id=net0,hostfwd=tcp::2222-:22 \
-device virtio-net-pci,netdev=net0 \
-virtfs local,path=$HOME/shared_with_vm,mount_tag=host_share,security_model=none,id=fsdev0 \
-device virtio-9p-pci,fsdev=fsdev0,mount_tag=host_share \
-nographic -serial mon:stdio1.2.10、QEMU虚拟机安装开发环境
# 宿主机上SSH登录qemu(注意端口是 2222)
ssh ubuntu@localhost -p 2222
# 登录qemu环境
# 账号:ubuntu
# 密码:ubuntu
# 在qemu虚拟机内执行
sudo apt update
sudo apt install build-essential gcc make git linux-headers-$(uname -r) linux-modules-extra-$(uname -r) rdma-core ibverbs-utils1.2.11、验证RDMA环境
# 获取网卡名称
NETDEV=$(ip -o -4 route show to default | awk '{print $5}')
# 加载 RXE 模块并创建一个 rxe 设备
sudo modprobe rdma_rxe
sudo rdma link add rxe0 type rxe netdev $NETDEV
# 查看设备信息
ibv_devinfo
# 如果一切正常,应该能看到类似下面的输出,表明 RDMA 环境正常。
hca_id: rxe0
transport: InfiniBand (0)
fw_ver: 0.0.0
node_guid: 5054:00ff:fe12:3456
sys_image_guid: 5054:00ff:fe12:3456
vendor_id: 0xffffff
vendor_part_id: 0
hw_ver: 0x0
phys_port_cnt: 1
port: 1
state: PORT_ACTIVE (4)
max_mtu: 4096 (5)
active_mtu: 1024 (3)
sm_lid: 0
port_lid: 0
port_lmc: 0x00
link_layer: Ethernet1.2.12、挂载和使用共享目录
# 在qemu虚拟机内执行
sudo mkdir -p /mnt/host_share
sudo mount -t 9p -o trans=virtio,version=9p2000.L,rw host_share /mnt/host_share
# 设置开机自动挂载,向虚拟机的 /etc/fstab 文件添加一行:
echo 'host_share /mnt/host_share 9p trans=virtio,version=9p2000.L,rw,_netdev,nofail 0 0' | sudo tee -a /etc/fstab
# _netdev 选项建议在网络可用后再挂载,nofail 选项防止因挂载失败导致启动卡住1.3、使用RDMA API
# rdma_cm API:
rdma_post_send();
rdma_post_write();
rdma_post_recv();
rdma_listen();
rdma_connect();
rdma_post_read();
rdma_post_ud_send();
# Verbs API:
ibv_get_device_list();
ibv_open_device();
ibv_query_device();
ibv_alloc_pd();
ibv_create_cq();
ibv_create_qp();
ibv_reg_mr();
ibv_modify_qp();
ibv_modify_qp();
ibv_modify_qp();
ibv_post_send();
ibv_post_recv();
ibv_poll_cq();
ibv_destroy_qp();
ibv_dereg_mr();
ibv_destroy_cq();
ibv_close_device();
ibv_free_device_list();
ibv_modiy_qp();
ibv_get_async_event();rdma 编程详解
RDMA编程养成记
RDMA2.1: verbs编程基础知识,程序执行流程,函数,名词说明
执行一个自己写的NCCL集合通信代码
1.3.1、RDMA WRITE 操作
uint64_t remote_addr = 0x12345678;
uint32_t rkey = 0x9ABCDEF0;
struct ibv_send_wr *bad_wr;
struct ibv_sge sge = {
.addr = (uintptr_t)local_buf,
.length = 4096,
.lkey = mr->lkey,
};
struct ibv_send_wr wr = {
.wr_id = 1,
.sg_list = &sge,
.num_sge = 1,
.opcode = IBV_WR_RDMA_WRITE,
.send_flags = IBV_SEND_SIGNALED,
.wr.rdma = {
.remote_addr = remote_addr,
.rkey = rkey,
},
};
ibv_post_send(qp, &wr, &bad_wr);1.3.2、RDMA SEND/RECV 操作
int post_recv(struct context *ctx) {
struct ibv_sge sge = {
.addr = (uintptr_t)ctx->buf,
.length = ctx->size,
.lkey = ctx->mr->lkey
};
struct ibv_recv_wr wr = {
.wr_id = 1,
.sg_list = &sge,
.num_sge = 1
};
struct ibv_recv_wr *bad_wr;
return ibv_post_recv(ctx->qp, &wr, &bad_wr);
}
int post_send(struct rdma_context *ctx, const char *msg) {
strncpy(ctx->buf, msg, ctx->size);
struct ibv_sge sge = {
.addr = (uintptr_t)ctx->buf,
.length = strlen(msg) + 1,
.lkey = ctx->mr->lkey
};
struct ibv_send_wr wr = {
.wr_id = 2,
.sg_list = &sge,
.num_sge = 1,
.opcode = IBV_WR_SEND,
.send_flags = IBV_SEND_SIGNALED
};
struct ibv_send_wr *bad_wr;
return ibv_post_send(ctx->qp, &wr, &bad_wr);
}1.3.3、RDMA READ 操作
uint64_t remote_addr = 0x12345678;
uint32_t rkey = 0x9ABCDEF0;
struct ibv_send_wr *bad_wr;
struct ibv_sge sge = {
.addr = (uintptr_t)local_buf,
.length = 4096,
.lkey = mr->lkey,
};
struct ibv_send_wr wr = {
.wr_id = 1,
.sg_list = &sge,
.num_sge = 1,
.opcode = IBV_WR_RDMA_READ,
.send_flags = IBV_SEND_SIGNALED,
.wr.rdma = {
.remote_addr = remote_addr,
.rkey = rkey,
},
};
ibv_post_send(qp, &wr, &bad_wr);1.4、使用RDMA工具集
RDMA性能测试工具perftest简介
工具集包括/sys/class/infiniband/、rdma link show、perftest,perftest如下:
- ib_atomic_bw
- ib_atomic_lat
- ib_read_bw
- ib_read_lat
- ib_send_bw
- ib_send_lat
- ib_write_bw
- ib_write_lat
- raw_ethernet_burst_lat
- raw_ethernet_bw
- raw_ethernet_fs_rate
- raw_ethernet_lat
1.5、核心代码分析(内核态驱动分析)
1.5.1、定义驱动的核心数据结构(urdma.h)
#ifndef __URDMA_H__
#define __URDMA_H__
#include <rdma/ib_verbs.h> // 引入 RDMA Verbs 相关的核心头文件
// 代表我们的虚拟 RDMA 设备
struct urdma_dev {
struct ib_device ibdev; // 内嵌标准的 ib_device 结构,这是与 ib_core 交互的关键
int id; // 设备的唯一标识符
union ib_gid gid; // 用于存储设备的 GID (全局标识符),用于网络寻址
};
// 一个辅助内联函数,用于从 ib_device 指针获取包含它的 urdma_dev 指针
// 这是内核中常见的技巧,通过结构体成员的地址反向定位整个结构体的地址
static inline struct urdma_dev *to_udev(struct ib_device *ibdev)
{
return container_of(ibdev, struct urdma_dev, ibdev);
}
// 为 Verbs 对象定义自定义的包装结构体
struct urdma_pd {
struct ib_pd ibpd; // 内嵌标准的 ib_pd
};
struct urdma_cq {
struct ib_cq ibcq; // 内嵌标准的 ib_cq
};
struct urdma_qp {
struct ib_qp ibqp; // 内嵌标准的 ib_qp
};
struct urdma_ucontext {
struct ib_ucontext ibuc; // 内嵌标准的 ib_ucontext
};
#endif /* __URDMA_H__ */1.5.2、实现模块的初始化和退出函数(urdma_main.c)
#include <linux/module.h> // 标准模块头文件
#include "urdma.h" // 我们自己的头文件
MODULE_AUTHOR("Linux RDMA Tutorial Driver Developer"); // 模块作者
MODULE_DESCRIPTION("A minimal virtual RDMA device driver"); // 模块描述
MODULE_LICENSE("GPL"); // 许可证声明
#define NUM_DEV 2 // 定义我们想要创建的虚拟设备数量
static struct urdma_dev *urdma_devs[NUM_DEV] = {}; // 全局数组,用于存放我们的设备实例
// 前向声明
static int urdma_register_device(struct urdma_dev *urdma);
static const struct ib_device_ops urdma_device_ops; // 定义在后续
// 设备分配与释放的辅助函数
static struct urdma_dev *urdma_alloc_device(const int id)
{
struct urdma_dev *urdma;
urdma = ib_alloc_device(urdma_dev, ibdev);
if (!urdma) {
pr_err("urdma: alloc_device failed for id: %d\n", id);
return NULL;
}
urdma->id = id;
urdma->gid.global.subnet_prefix = cpu_to_be64(0xfe80000000000000);
urdma->gid.global.interface_id = cpu_to_be64(0x505400fffe123456);
pr_info("urdma: allocated device for id: %d\n", id);
return urdma;
}
static void urdma_dealloc_device(struct urdma_dev *urdma)
{
if (!urdma)
return;
pr_info("urdma: deallocating device for id: %d\n", urdma->id);
ib_dealloc_device(&urdma->ibdev);
}
// 模块初始化函数
static int __init urdma_init_module(void)
{
int err = 0;
int i;
pr_info("urdma: loading module...\n");
for (i = 0; i < NUM_DEV; i++) {
urdma_devs[i] = urdma_alloc_device(i);
if (!urdma_devs[i]) {
err = -ENOMEM;
goto err_cleanup;
}
err = urdma_register_device(urdma_devs[i]);
if (err) {
urdma_dealloc_device(urdma_devs[i]);
urdma_devs[i] = NULL;
goto err_cleanup;
}
}
pr_info("urdma: module loaded successfully with %d device(s)\n", NUM_DEV);
return 0;
err_cleanup:
pr_err("urdma: error during module initialization, cleaning up...\n");
// 清理已成功创建的设备
for (i = i - 1; i >= 0; i--) { // 从最后一个成功分配/注册的开始清理
if (urdma_devs[i]) {
ib_unregister_device(&urdma_devs[i]->ibdev);
urdma_dealloc_device(urdma_devs[i]);
urdma_devs[i] = NULL;
}
}
return err;
}
// 模块退出函数
static void __exit urdma_exit_module(void)
{
int i;
pr_info("urdma: unloading module...\n");
for (i = 0; i < NUM_DEV; i++) {
if (urdma_devs[i]) {
ib_unregister_device(&urdma_devs[i]->ibdev);
urdma_dealloc_device(urdma_devs[i]);
urdma_devs[i] = NULL;
}
}
pr_info("urdma: module unloaded.\n");
}
module_init(urdma_init_module);
module_exit(urdma_exit_module);
// ib_device_ops 和 urdma_register_device 的定义将在后文给出1.5.3、实现 ib_device_ops 中的必要回调函数(urdma_main.c)
// --- ib_device_ops 的最小实现 ---
// 获取端口不可变属性 (在设备注册时调用)
static int urdma_get_port_immutable(struct ib_device *ibdev, u32 port_num, struct ib_port_immutable *immutable)
{
immutable->gid_tbl_len = 1; // 支持一个 GID
return 0;
}
static int urdma_query_device(struct ib_device *ibdev, struct ib_device_attr *attr, struct ib_udata *udata)
{
memset(attr, 0, sizeof(*attr));
return 0;
}
static int urdma_query_port(struct ib_device *ibdev, u32 port_num, struct ib_port_attr *attr)
{
memset(attr, 0, sizeof(*attr));
attr->state = IB_PORT_ACTIVE; // 设置为活动状态
attr->gid_tbl_len = 1; // 支持一个 GID
attr->phys_state = IB_PORT_PHYS_STATE_LINK_UP; // 物理链路状态
return 0;
}
static int urdma_query_gid(struct ib_device *ibdev, u32 port_num, int index, union ib_gid *gid)
{
struct urdma_dev *urdma = to_udev(ibdev);
memcpy(gid, &urdma->gid, sizeof(*gid)); // 返回预设的GID
return 0;
}
// --- stub 实现 ---
static int urdma_alloc_pd(struct ib_pd *pd, struct ib_udata *udata) { return 0; }
static int urdma_dealloc_pd(struct ib_pd *pd, struct ib_udata *udata) { return 0; }
static int urdma_create_qp(struct ib_qp *qp, struct ib_qp_init_attr *init_attr, struct ib_udata *udata) { return 0; }
static int urdma_modify_qp(struct ib_qp *qp, struct ib_qp_attr *attr, int attr_mask, struct ib_udata *udata) { return 0; }
static int urdma_destroy_qp(struct ib_qp *qp, struct ib_udata *udata) { return 0; }
static int urdma_post_send(struct ib_qp *ibqp, const struct ib_send_wr *wr, const struct ib_send_wr **bad_wr) { return 0; }
static int urdma_post_recv(struct ib_qp *ibqp, const struct ib_recv_wr *wr, const struct ib_recv_wr **bad_wr) { return 0; }
static int urdma_create_cq(struct ib_cq *ibcq, const struct ib_cq_init_attr *attr, struct ib_udata *udata) { return 0; }
static int urdma_destroy_cq(struct ib_cq *cq, struct ib_udata *udata) { return 0; }
static int urdma_poll_cq(struct ib_cq *ibcq, int num_entries, struct ib_wc *wc) { return 0; }
static int urdma_req_notify_cq(struct ib_cq *ibcq, enum ib_cq_notify_flags flags) { return 0; }
static struct ib_mr *urdma_get_dma_mr(struct ib_pd *ibpd, int access) { struct ib_mr *mr = kzalloc(sizeof(*mr), GFP_KERNEL); return mr ? mr : ERR_PTR(-ENOMEM); }
static struct ib_mr *urdma_reg_user_mr(struct ib_pd *pd, u64 start, u64 length, u64 virt_addr, int access_flags, struct ib_udata *udata) { struct ib_mr *mr = kzalloc(sizeof(*mr), GFP_KERNEL); return mr ? mr : ERR_PTR(-ENOMEM); }
static int urdma_dereg_mr(struct ib_mr *mr, struct ib_udata *udata) { kfree(mr); return 0; }
static int urdma_alloc_ucontext(struct ib_ucontext *ibuc, struct ib_udata *udata) { return 0; }
static void urdma_dealloc_ucontext(struct ib_ucontext *ibuc) { return; }
// ib_device_ops 的定义
static const struct ib_device_ops urdma_device_ops = {
.owner = THIS_MODULE,
.driver_id = RDMA_DRIVER_UNKNOWN,
.uverbs_abi_ver = 1,
// mandatory methods <https://elixir.bootlin.com/linux/v6.8/source/drivers/infiniband/core/device.c#L267>
.query_device = urdma_query_device,
.query_port = urdma_query_port,
.alloc_pd = urdma_alloc_pd,
.dealloc_pd = urdma_dealloc_pd,
INIT_RDMA_OBJ_SIZE(ib_pd, urdma_pd, ibpd),
.create_qp = urdma_create_qp,
.modify_qp = urdma_modify_qp,
.destroy_qp = urdma_destroy_qp,
INIT_RDMA_OBJ_SIZE(ib_qp, urdma_qp, ibqp),
.post_send = urdma_post_send,
.post_recv = urdma_post_recv,
.create_cq = urdma_create_cq,
.destroy_cq = urdma_destroy_cq,
.poll_cq = urdma_poll_cq,
INIT_RDMA_OBJ_SIZE(ib_cq, urdma_cq, ibcq),
.req_notify_cq = urdma_req_notify_cq,
.get_dma_mr = urdma_get_dma_mr,
.reg_user_mr = urdma_reg_user_mr,
.dereg_mr = urdma_dereg_mr,
.get_port_immutable = urdma_get_port_immutable,
// uverbs required methods
.alloc_ucontext = urdma_alloc_ucontext,
.dealloc_ucontext = urdma_dealloc_ucontext,
INIT_RDMA_OBJ_SIZE(ib_ucontext, urdma_ucontext, ibuc),
// rc_pingpong required methods
.query_gid = urdma_query_gid,
};1.5.4、分配、初始化并注册 ib_device 实例(urdma_main.c)
static int urdma_register_device(struct urdma_dev *urdma)
{
struct ib_device *dev = &urdma->ibdev;
int err;
// --- 填充 ib_device 的属性 ---
strscpy(dev->node_desc, "URDMA Virtual HCA", sizeof(dev->node_desc));
dev->node_type = RDMA_NODE_UNSPECIFIED; // 我们的设备类型标识为未知
dev->phys_port_cnt = 1; // 模拟一个单端口设备
// 设置设备的操作函数表
ib_set_device_ops(dev, &urdma_device_ops);
// --- 注册设备到 ib_core ---
// 第二个参数 "urdma%d" 用于格式化注册信息,dev->name 才是最终的设备名
err = ib_register_device(dev, "urdma%d", NULL);
if (err) {
pr_err("urdma: failed to register device %s: %d\n", dev->name, err);
} else {
pr_info("urdma: successfully registered device %s\n", dev->name);
}
return err;
}1.5.5、makefile
obj-m += urdma.o
urdma-objs := urdma_main.o # 如果有其他 .c 文件,也添加到这里
KDIR ?= /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
all:
$(MAKE) -C $(KDIR) M=$(PWD) modules
clean:
$(MAKE) -C $(KDIR) M=$(PWD) clean
load: all
sudo insmod ./urdma.ko
unload:
sudo rmmod urdma
log:
sudo dmesg -T | tail -n 201.5.6、编译加载及验证
# 1. 编译
make
# 2. 加载
sudo modprobe ib_core # 加载依赖
sudo insmod ./urdma.ko
sudo dmesg -T | tail -n 20
# 3. 验证
ls /sys/class/infiniband/
urdma0 urdma1
cat /sys/class/infiniband/urdma0/node_desc
URDMA Virtual HCA
cat /sys/class/infiniband/urdma0/ports/1/state
4: ACTIVE
# 查看 GID (注意 GID 在 sysfs 中通常以十六进制冒号分隔格式显示)
cat /sys/class/infiniband/urdma0/ports/1/gids/0
fe80:0000:0000:0000:5054:00ff:fe12:3456
rdma link show
link urdma0/1 state ACTIVE physical_state LINK_UP
link urdma1/1 state ACTIVE physical_state LINK_UP1.6、链接
虚拟 RDMA 设备驱动实现(一):环境配置与Linux内核模块初探
虚拟 RDMA 设备驱动实现(二):从零构建一个内核可识别的RDMA设备
实现一个 RDMA 用户态驱动程序
blue-rdma 设计介绍 (一)—— 如何实现RDMA操作
blue-rdma 设计介绍 (二)—— 软硬件架构
blue-rdma 设计介绍 (三)—— 数据包处理
Linux下RDMA驱动程序探索系列-1
Linux下RDMA驱动程序探索系列-2
GPUDirect RDMA 的演进与实现
InfiniBand包头与ibverbs接口实现(一)—— RDMA WRITE分析
天工开物开源毕设:达坦科技Open-RDMA等你来战
一次RDMA用户态驱动调试的复盘
直播预告 l RDMA软件接口高层封装
达坦科技RDMA解决方案助力国际顶尖天文观测项目论文发表
TA的视频
RDMA 系列(一)- 总览
RDMA(二)- 从rdma 看 CPU 架构和瓶颈
RDMA(三)- 从DMA-BUF 到GDR
详解RDMA架构和技术原理 rdma应用
深入理解 RDMA 的软硬件交互机制
RDMA技术-Queue&传输机制详解(2)
RDMA技术深入应用与编程实践手册
Xilinx ERNIC:
xilinx rdma实现100G以太网开发笔记,支持标准ROCE V2协议,与PC大带宽通信,支持麦乐斯全系列网卡
xilinx rdma ernic FPGA verilog源码与架构实践
Xilinx Embedded RDMA Enabled NIC(ERNIC)
RDMA用户态驱动:https://github.com/linux-rdma/rdma-core
RDMA内核态驱动:Linux内核代码drivers/infiniband目录下
drivers/infiniband/hw/mlx4驱动是用于ConnectX-3或更早的网卡,如:
MCX354A-FCCT: ConnectX-3 VPI, QSFP+ 接口
MCX354A-QCBT: ConnectX-3 VPI, QSFP+ 接口
MCX314A-BCCT: ConnectX-3 Pro, QSFP+ 接口
MT27500/MT27501: 这是 ConnectX-3 系列的芯片代号(Family)
ConnectX-2 系列
ConnectX-EN 系列(早期的以太网卡)
Mellanox ConnectX HCA InfiniBand 驱动分析:drivers/infiniband/hw/mlx4/main.c
Mellanox ConnectX HCA InfiniBand 驱动深入解析
Savir
配置 InfiniBand 和 RDMA 网络
复盘:在Ubuntu 20.04下安装OFED驱动
2、NVLink/NVSwitch

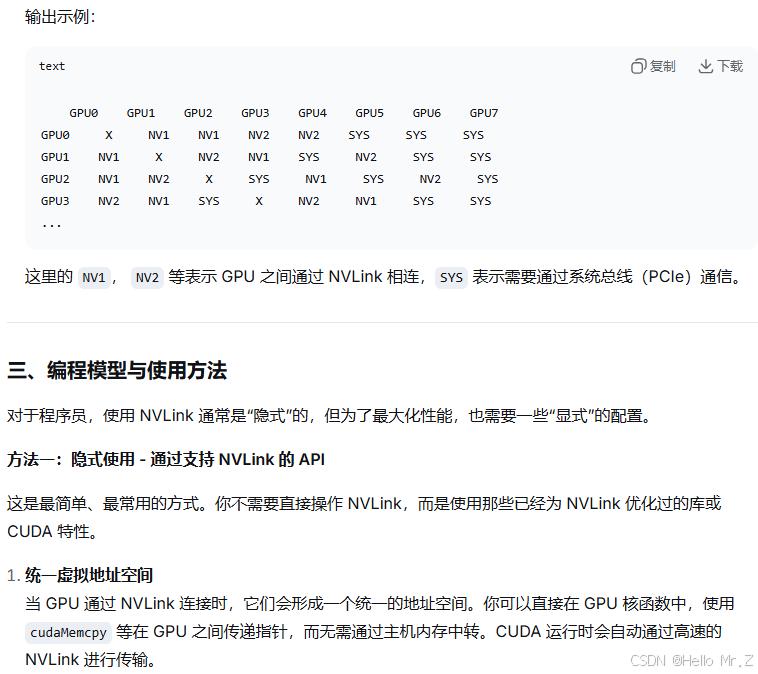
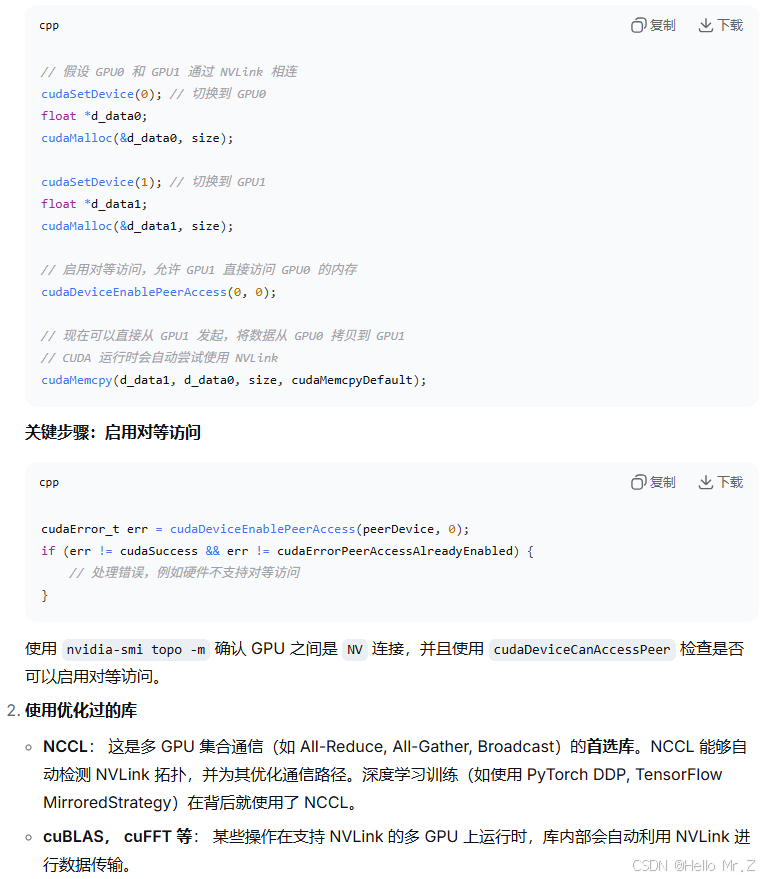
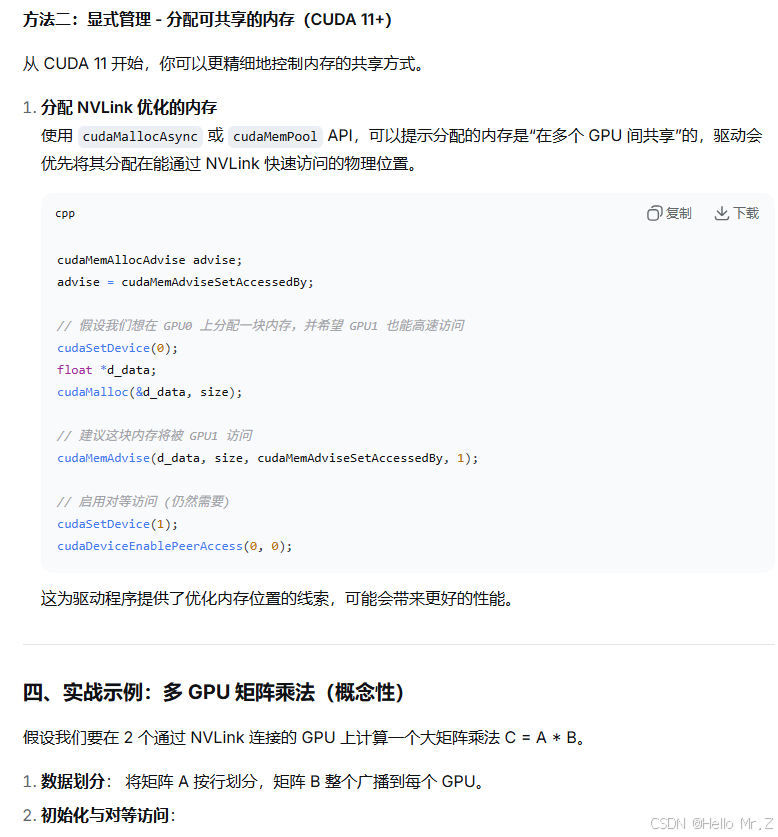
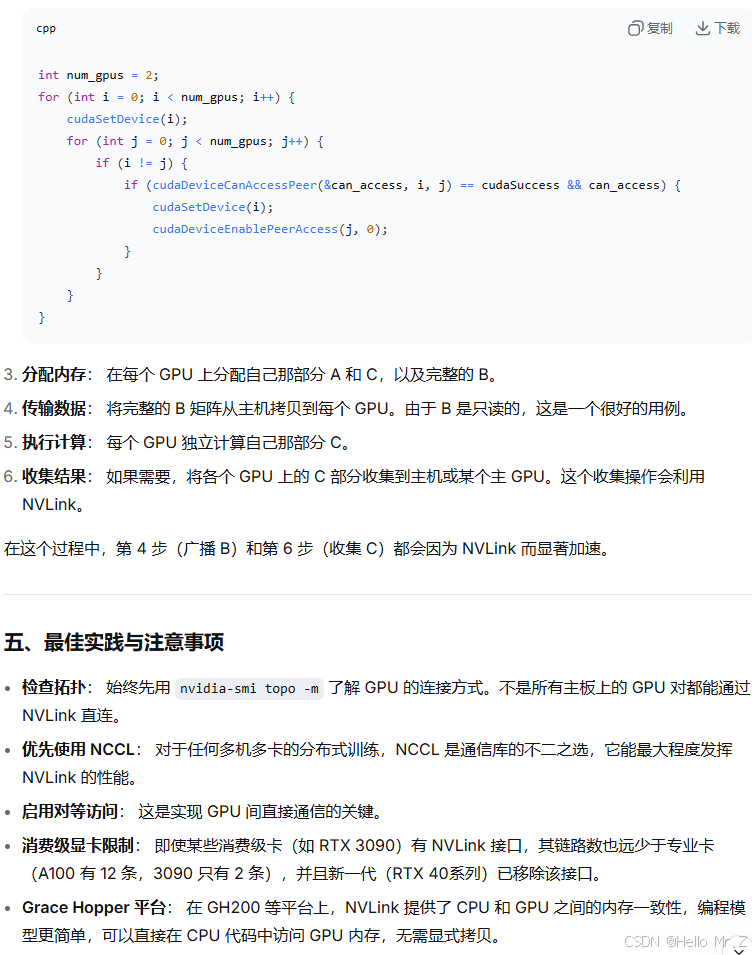

在没有nvlink硬件设备的情况下,需要实现卡间通信则采用PCIe与两种方式:
PCIe:GPU-A -> PCIe -> 系统内存 -> PCIe -> GPU-B
GPUDirect P2P(PCIe卡在同一根复合体上):GPU-A -> PCIe -> GPU-B
【AI系统】NVLink 原理剖析
Nvidia技术壁垒之一--NVLink&NVSwitch
https://chat.deepseek.com/a/chat/s/20e2e1a0-0f4c-4ae9-b7d1-5d6df63b3d4e
浅析GPU通信技术(上)-GPUDirect P2P
浅析GPU通信技术(中)-NVLink
浅析GPU通信技术(下)-GPUDirect RDMA
聊透 GPU 通信技术——GPU Direct、NVLink、RDMA
3、NCCL
3.1、nccl-tests编译及环境安装
3.1.1、安装nccl
# 查看cuda版本
nvcc -V
# 配置网络存储库
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update
# 安装特定版本
sudo apt install libnccl2=2.15.1-1+cuda11.8 libnccl-dev=2.15.1-1+cuda11.8
# 确认系统nccl版本
dpkg -l | grep nccl3.1.2、安装openmpi
# apt安装openmpi
sudo apt-get update
sudo apt-get install openmpi-bin openmpi-doc libopenmpi-dev
# 验证是否安装成功
mpirun --version3.1.3、编译nccl-tests
# 克隆该repo
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests
# 编译支持mpi的test
make MPI=1 MPI_HOME=/usr/lib/x86_64-linux-gnu/openmpi
# 可选编译参数
# NCCL_ALGO=Tree ./build/all_reduce_perf -b 1M -e 2048M -f 2 -g 8
# NCCL_ALGO=Ring ./build/all_reduce_perf -b 1M -e 2048M -f 2 -g 83.1.4、编译结果

3.2、NCCL源语
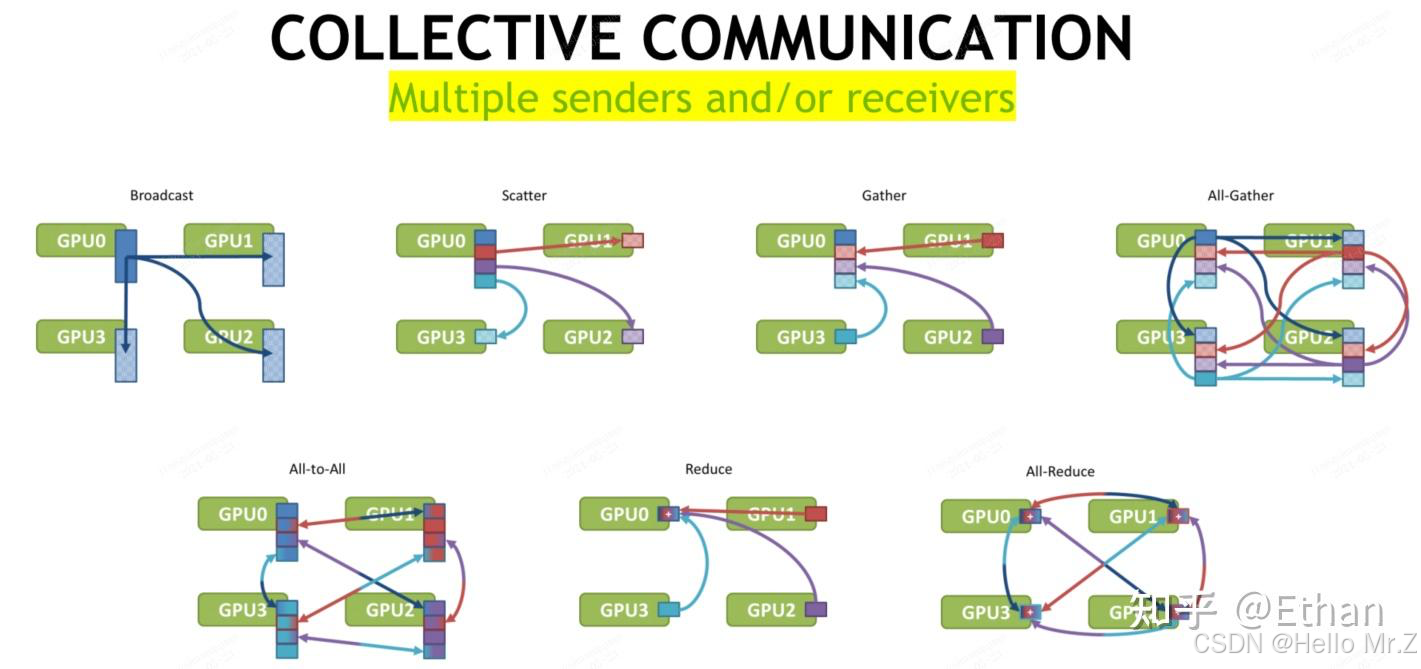
3.3、使用NCCL工具集nccl-tests
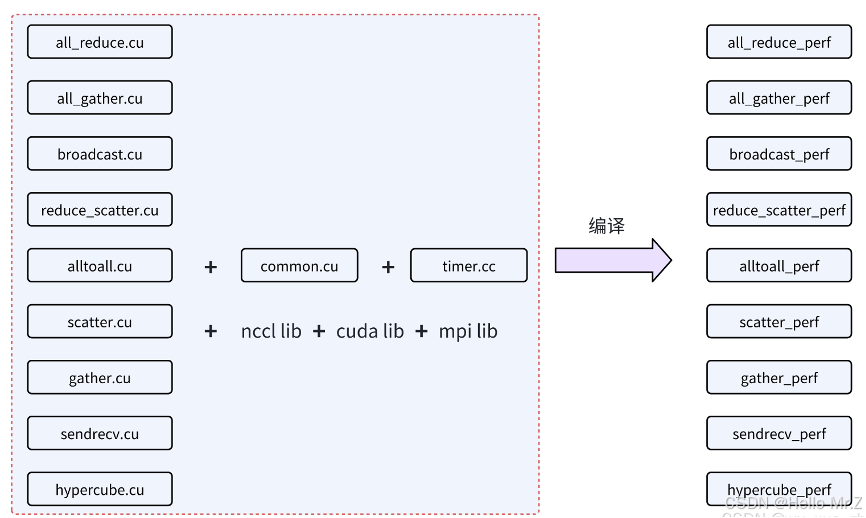
AllReduce:./all_reduce_perf
ReduceScatter:./reduce_scatter_perf
AllGather:./all_gather_perf
Broadcast:./broadcast_perf
Reduce:./reduce_perf
# 2 台机器,16 张 GPU卡,执行 all_reduce_perf 测试
mpirun -np 16 \ // 指定总进程数(需匹配GPU数量)
-H 172.16.2.8:8,172.16.2.13:8 \ // 定义主机和每台主机的GPU数
--allow-run-as-root \ // 允许以root权限运行
-bind-to none -map-by slot \
-x NCCL_DEBUG=INFO \ // 查看详细日志
-x NCCL_IB_GID_INDEX=3 \
-x NCCL_IB_DISABLE=0 \
-x NCCL_SOCKET_IFNAME=eth0 \ // 指定网卡
-x NCCL_NET_GDR_LEVEL=2 \
-x NCCL_IB_QPS_PER_CONNECTION=4 \
-x NCCL_IB_TC=160 \
-x LD_LIBRARY_PATH -x PATH \
-mca btl ^openib \ // 禁用特定通信后端(如避免OpenIB冲突)
-mca coll_hcoll_enable 0 -mca pml ob1 -mca btl_tcp_if_include eth0 \
./build/all_reduce_perf -b 32M -e 1G -i 1000 -f 2 -g 1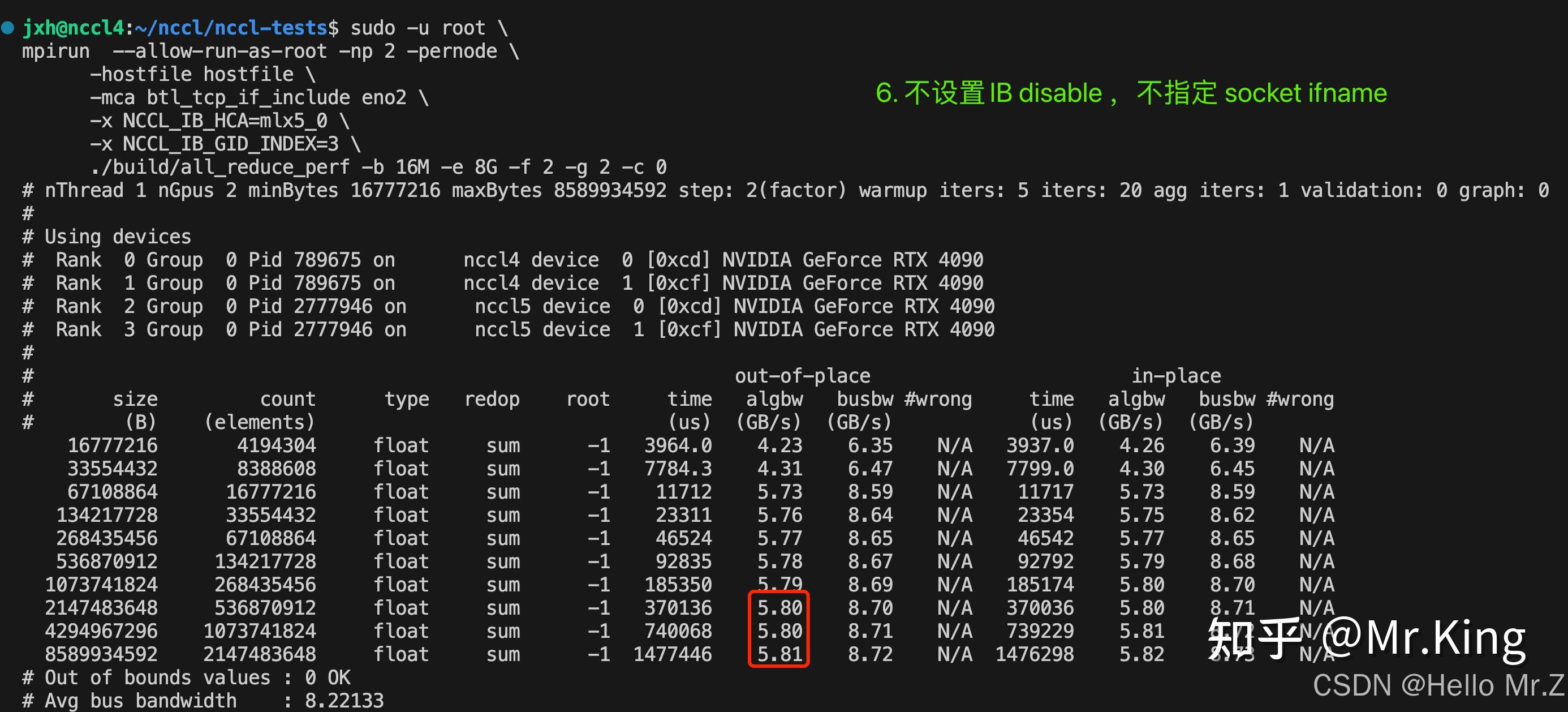
3.4、使用NCCL API及pytorch调用API过程
1. 初始化与生命周期管理
ncclGetUniqueId(ncclUniqueId* uniqueId);
ncclCommInitRank(ncclComm_t* comm, int ndev, ncclUniqueId commId, int rank);
ncclCommDestroy(ncclComm_t comm);
ncclCommInitAll(ncclComm_t* comm, int ndev, const int* devlist);
ncclGroupStart();
ncclGroupEnd();
2. 集体通信操作(核心功能)
ncclAllReduce(...);
ncclReduce(...);
ncclReduceScatter(...);
ncclBroadcast(...);
ncclAllGather(...);
ncclGather(...);
3. 点对点通信操作(NCCL 2.7+)
ncclSend(...);
ncclRecv(...);
4. 信息与调试
ncclCommCount(const ncclComm_t comm);
ncclCommUserRank(const ncclComm_t comm);
ncclGetVersion(int* version);
ncclGetLastError(ncclComm_t comm); Nvidia-NCCL-GPU集合通信接口简介_源码笔记
执行一个自己写的NCCL集合通信代码
pytorch初始化过程:
getNCCLComm->ncclComm::create->NCCLCommInitRank,NCCLCommInitRank函数完成communicator和设备的绑定,底层cuda stream的建立、拓扑发现等。
pytorch运行过程中触发NCCL回调:
- DDP 由于是Module的子类,所以继承了Module的hooks 机制,使forward函数被执行
- DDP 的forward 包括三个阶段,pre_forward,run_ddp_forward,post_forward,如果使能delay_allreduce_all_params, forward 过程不触发allreduce
- DDP backward 中流程相对简单,似乎主要是为了delay_allreduce
- NCCL 被ProcessGroupNCCL class 包住,通过intraComm和reducer的抽象最后以hooks 方式暴露给python
- NCCL 被触发的时机在于joinable.exit 和 joinable.notify_join_context
- DDP 由于是Joinable的子类,所以继承了joinable的接口,forward 过程中通过joinable.notify_join_context 调用allreduce
- reduce 过程中注重bucketing的原因是为了提高allreduce 的 overlap
多机多卡运行nccl-tests和channel获取
2. 多机多卡nccl-tests 对比分析
Pytorch+NCCL源码编译
【教程】简介nccl-test工具
RDMA 环境下的一点 NCCL 调试经验
分布式入门(一)- 通信原语和通信库
分布式入门(二)- MPI 的进程组与进程拓扑
源码阅读-PyTorch 如何调用到NCCL?
第12篇 - 集合通信 - NCCL 关键代码路径分析
NCCL和NVSHMEM的主要区别是什么?
一文讲清 NCCL 集合通信原理与优化
NCCL概述和NCCL-Test分析
分布式训练——集合通信及其通信原语
【大模型】通信元语和相关概念|NCCL梯度|Allreduce|Scatter|Broadcast|Gather
Nvidia-NCCL-GPU集合通信接口简介_源码笔记

















 3235
3235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









