









写在前面
上一篇记录了DSO的初始化阶段,本文主要记录下对于新帧的追踪,即tracking,整个部分其实不是很难,主要的思路也简单,就是由粗到细的进行光度误差的最小化,以此来计算位姿。
特点
虽然都是最小化光度误差,这里先列出DSO做的很不同的地方:
- 放弃使用了像素块的方法,这个个人深有感触,一般而言虽然像素块的大小不大,但是耐不住点多啊,多数情况下如果用像素块的话这个地方就变成了十分花费时间;
- 当某一层的初始位姿不好的时候,DSO并不放弃"治疗",反而会给足了机会去优化,但是如果优化出来的结果与阈值差距太大,那么就直接放弃了;
- 作者假设了5种运动模型:匀速、倍速、半速、零速以及没有运动;
- 与此同时,作者假定了有26×N种旋转情况(四元数的26种旋转情况,N个比较小的角度),作者认为是在丢失的情况下,这样的方法会十分有用,如果没有丢失应该前五种假设就够了;
深入探讨
整个跟踪函数仅有一个,即代码中的trackNewCoarse函数,该函数主要做了四件事:
- 准备相应的运动初值,详细来说就是五种运动假设和N种旋转假设;
- 对每一个运动假设进行L-M迭代,求得最佳的位姿以及对应的能量;
- 更新最优结果;
- 更新其它变量;
下面逐步进行说明:
A. 准备运动初值
这个部分用文字说明比较苍白,这里配上一张图会比较清晰:
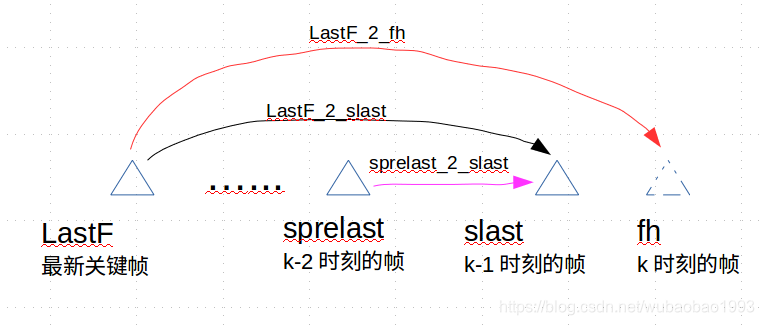
如图所示,图中的变量使用的都是程序中的变量名称,最终需要的运动初值为红线所示的LastF_2_fh,然后作者使用的参考运动值为sprelast_2_slast,假设为slast_2_fh,因此五种模型如下:
- 匀速模型: T l a s t F f h = T s l a s t f h ∗ T l a s t F s l a s t T_{lastF}^{fh} = T_{slast}^{fh}*T_{lastF}^{slast} TlastFfh=Tslastfh∗TlastFslast;
- 倍速模型: T l a s t F f h = T s l a s t f h ∗ T l a s t F f h T_{lastF}^{fh} = T_{slast}^{fh}*T_{lastF}^{fh} TlastFfh=Tslastfh∗TlastFfh,相当于说匀速的从slast帧运动到当前帧,之后以当前帧为起点再匀速运动一次;
- 半速模型: T l a s t F f h = 0.5 × T s l a s t f h ∗ T l a s t F s l a s t T_{lastF}^{fh} = 0.5×T_{slast}^{fh}*T_{lastF}^{slast} TlastFfh=0.5×Tslastfh∗TlastFslast;
- 零速模型: T l a s t F f h = T l a s t F s l a s t T_{lastF}^{fh} = T_{lastF}^{slast} TlastFfh=TlastFslast;
- 不动模型: T l a s t F f h = T I T_{lastF}^{fh} = T_I TlastFfh=TI;
随后就是26×3种旋转模型,这里不在赘述,代码如下:
shared_ptr<FrameHessian> lastF = coarseTracker->lastRef; // last key frame
shared_ptr<Frame> slast = allFrameHistory[allFrameHistory.size() - 2];
shared_ptr<Frame> sprelast = allFrameHistory[allFrameHistory.size() - 3];
SE3 slast_2_sprelast;
SE3 lastF_2_slast;
{ // lock on global pose consistency!
unique_lock<mutex> crlock(shellPoseMutex);
slast_2_sprelast = sprelast->getPose() * slast->getPose().inverse();
lastF_2_slast = slast->getPose() * lastF->frame->getPose().inverse();
aff_last_2_l = slast->aff_g2l;
}
SE3 fh_2_slast = slast_2_sprelast;// assumed to be the same as fh_2_slast.
// get last delta-movement.
lastF_2_fh_tries.push_back(fh_2_slast.inverse() * lastF_2_slast); // assume constant motion.
lastF_2_fh_tries.push_back(fh_2_slast.inverse() * fh_2_slast.inverse() * lastF_2_slast); // assume double motion (frame skipped)
lastF_2_fh_tries.push_back(SE3::exp(fh_2_slast.log() * 0.5).inverse() * lastF_2_slast); // assume half motion.
lastF_2_fh_tries.push_back(lastF_2_slast); // assume zero motion.
lastF_2_fh_tries.push_back(SE3()); // assume zero motion FROM KF.
// just try a TON of different initializations (all rotations). In the end,
// if they don't work they will only be tried on the coarsest level, which is super fast anyway.
// also, if tracking rails here we loose, so we really, really want to avoid that.
for (float rotDelta = 0.02;rotDelta < 0.05; rotDelta += 0.01) { // TODO changed this into +=0.01 where DSO writes ++
lastF_2_fh_tries.push_back(fh_2_slast.inverse() * lastF_2_slast *
SE3(Sophus::Quaterniond(1, rotDelta, 0, 0),
Vec3(0, 0, 0))); // assume constant motion.
...
lastF_2_fh_tries.push_back(fh_2_slast.inverse() * lastF_2_slast *
SE3(Sophus::Quaterniond(1, rotDelta, rotDelta, rotDelta),
Vec3(0, 0, 0))); // assume constant motion.
}
这里说明一点的是,虽然注释上写说旋转模型仅仅在金字塔最顶层进行优化,但是在代码上个人并没有发现。
B. 位姿优化
对于每一个运动假设,算法从金字塔的最顶层由粗到细的进行位姿优化,大致步骤如下(主要是coarseTracker->trackNewestCoarse函数部分):
-
从上到下遍历每一层;
-
对于每一层使用L-M优化的方式,不过对于初始化的残差和增量方程,作者采取了及其容忍的态度,这大概率是因为在计算光度误差的时候,作者仅仅使用一个点而不是像素块的方式,具体方法是每次都会判断超出阈值的点所占的比例,如果比例过大(60%),则增加阈值(2倍)并重新来过,直到满足条件或者阈值增大到一定程度,代码如下:
Vec6 resOld = calcRes(lvl, refToNew_current, aff_g2l_current, setting_coarseCutoffTH * levelCutoffRepeat); // 如果误差大的点的比例大于60%, 那么增大阈值再计算N次 while (resOld[5] > 0.6 && levelCutoffRepeat < 50) { // more than 60% is over than threshold, then increate the cut off threshold levelCutoffRepeat *= 2; resOld = calcRes(lvl, refToNew_current, aff_g2l_current, setting_coarseCutoffTH * levelCutoffRepeat); } // Compute H and b // 内部也是用SSE实现的,公式可以参考上一篇文章 // 其中用到的参考帧的东西都在参考帧添加的时候准备好了 calcGSSSE(lvl, H, b, refToNew_current, aff_g2l_current); -
进行L-M算法,这里都比较正常,代码如下:代码中不太明白的是作者在求解出增量了之后,为什么又与权重做了积?
for (int iteration = 0; iteration < maxIterations[lvl]; iteration++) { Mat88 Hl = H; for (int i = 0; i < 8; i++) Hl(i, i) *= (1 + lambda); Vec8 inc = Hl.ldlt().solve(-b); // depends on the mode, if a,b is fixed, don't estimate them if (setting_affineOptModeA < 0 && setting_affineOptModeB < 0) // fix a, b { inc.head<6>() = Hl.topLeftCorner<6, 6>().ldlt().solve(-b.head<6>()); inc.tail<2>().setZero(); } if (!(setting_affineOptModeA < 0) && setting_affineOptModeB < 0) // fix b { inc.head<7>() = Hl.topLeftCorner<7, 7>().ldlt().solve(-b.head<7>()); inc.tail<1>().setZero(); } if (setting_affineOptModeA < 0 && !(setting_affineOptModeB < 0)) // fix a { Mat88 HlStitch = Hl; Vec8 bStitch = b; HlStitch.col(6) = HlStitch.col(7); HlStitch.row(6) = HlStitch.row(7); bStitch[6] = bStitch[7]; Vec7 incStitch = HlStitch.topLeftCorner<7, 7>().ldlt().solve(-bStitch.head<7>()); inc.setZero(); inc.head<6>() = incStitch.head<6>(); inc[6] = 0; inc[7] = incStitch[6]; } float extrapFac = 1; if (lambda < lambdaExtrapolationLimit) extrapFac = sqrtf(sqrt(lambdaExtrapolationLimit / lambda)); inc *= extrapFac; // 这里为什么要再乘一个scale Vec8 incScaled = inc; incScaled.segment<3>(0) *= SCALE_XI_ROT; incScaled.segment<3>(3) *= SCALE_XI_TRANS; incScaled.segment<1>(6) *= SCALE_A; incScaled.segment<1>(7) *= SCALE_B; if (!std::isfinite(incScaled.sum())) incScaled.setZero(); // left multiply the pose and add to a,b SE3 refToNew_new = SE3::exp((Vec6) (incScaled.head<6>())) * refToNew_current; AffLight aff_g2l_new = aff_g2l_current; aff_g2l_new.a += incScaled[6]; aff_g2l_new.b += incScaled[7]; // calculate new residual after this update step Vec6 resNew = calcRes(lvl, refToNew_new, aff_g2l_new, setting_coarseCutoffTH * levelCutoffRepeat); // decide whether to accept this step // res[0]/res[1] is the average energy bool accept = (resNew[0] / resNew[1]) < (resOld[0] / resOld[1]); if (accept) { // decrease lambda calcGSSSE(lvl, H, b, refToNew_new, aff_g2l_new); resOld = resNew; aff_g2l_current = aff_g2l_new; refToNew_current = refToNew_new; lambda *= 0.5; } else { // increase lambda in LM lambda *= 4; if (lambda < lambdaExtrapolationLimit) lambda = lambdaExtrapolationLimit; } // terminate if increment is small if (!(inc.norm() > 1e-3)) { break; } } // end of L-M iteration -
优化完成之后查看一下该层最终的标准差,如果标准差大于阈值的1.5倍时,认为该次优化失败了,直接退出,这里阈值是动态调节的,假设这是对第k+1个运动假设进行优化,0~k次得到的最优运动假设误差为E(阈值就是这个),那么该次优化的误差如果超过了NE(作者使用N=1.5),那就没必要再优化了,直接用最优的结果就好了,帮助删除一些不必要的优化时间,但是如果没有超过NE,就认为该运动假设可以继续进行优化;除此之外,如果该层的初始误差状态并不佳,但是最终的误差确实在NE范围中,那么说明这个初值还有希望,就再优化一遍,不过这个机会是整个运动假设优化过程中唯一的一次机会,用掉了就没有了。代码如下:
// set last residual for that level, as well as flow indicators. // 看一下标准差,如果标准差大于1.5倍的阈值,那么认为优化失败 lastResiduals[lvl] = sqrtf((float) (resOld[0] / resOld[1])); lastFlowIndicators = resOld.segment<3>(2); if (lastResiduals[lvl] > 1.5 * minResForAbort[lvl]) return false; // repeat this level level // 当初始位姿不好的时候, if (levelCutoffRepeat > 1 && !haveRepeated) { lvl++; haveRepeated = true; }
C. 更新最优变量
经历上面的优化过程后,如果没有什么问题,此时我们就获得了一个能量(也就是整体的误差水平),如果本次优化在金字塔第0层的误差小于上次的第0层误差(第0层着实很重要),那么算法认为这是一个更好的结果,就更新(B4)步骤中的阈值为当前的各层误差;进一步,如果本次的金字塔第0层误差水平在上一帧的误差水平的1.5倍之内,那么就认为这个就是最优的,直接退出计算,代码如下:
if (trackingIsGood &&
std::isfinite((float) coarseTracker->lastResiduals[0]) &&
!(coarseTracker->lastResiduals[0] >= achievedRes[0])) {
flowVecs = coarseTracker->lastFlowIndicators;
aff_g2l = aff_g2l_this;
lastF_2_fh = lastF_2_fh_this;
haveOneGood = true;
}
// take over achieved res (always).
if (haveOneGood) {
for (int i = 0; i < 5; i++) {
if (!std::isfinite((float) achievedRes[i]) ||
achievedRes[i] > coarseTracker->lastResiduals[i]) // take over if achievedRes is either bigger or NAN.
achievedRes[i] = coarseTracker->lastResiduals[i];
}
}
// 如果当次的优化结果是上一帧结果的N倍之内,认为这就是最优的
if (haveOneGood && achievedRes[0] < lastCoarseRMSE[0] * setting_reTrackThreshold)
break;
D. 更新其他变量
最后,如果上面三个步骤都能如期运行,那么我们就已经跟踪上了前一个关键帧;但是如果上面的步骤并没有给出一个很好的结果,那么算法将匀速假设作为最好的假设并设置为当前的位姿。最后就是讲当前的误差水平更新为保存变量供之后的过程使用。代码如下:
if (!haveOneGood) {
LOG(WARNING) << "BIG ERROR! tracking failed entirely. Take predicted pose and hope we may somehow recover." << endl;
flowVecs = Vec3(0, 0, 0);
aff_g2l = aff_last_2_l;
lastF_2_fh = lastF_2_fh_tries[0];
}
lastCoarseRMSE = achievedRes;
总结
整体来看,DSO在进行位姿跟踪的时候确实花了不少心思,一是准备了很多运动假设,二是给每一个假设很足的机会,能初始化就初始化,实在不行才放弃。不过这么做也必然会花费不少时间。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









