









标题:GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis
链接:https://arxiv.org/pdf/2007.02442
这是一篇改进NeRF的文章,主要是引入了GAN,从而避免了NeRF对于相机参数标签的需求。

主要的结构非常直观,就是一个标准的conditional GAN, 然后NeRF的部分就放在了生成器里面。
首先,生成器的输入就是相机的各种参数,包括了位置,方向,焦点,远近等等信息,这些参数都是完全随机的从一个均匀分布中取出来的。
然后输入光线采样器来确定光线的落点和光线的数量。
之后就分了两路输入条件辐射场:
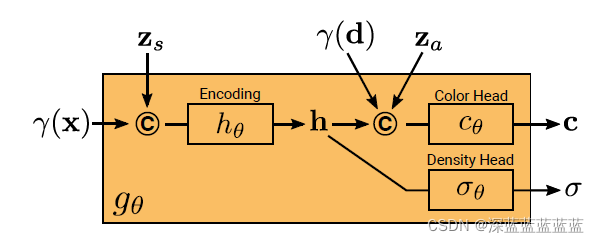
1.沿着光线进行采样,确定需要采样点的位置。然后将位置信息和随机采样的形状信息结合输入神经网络,学出一个形状表示。形状表示就可以用于预测目标点的密度
2.将光线落点信息结合上面的形状表示,再结合随机采样的纹理信息,一同预测出目标点的颜色
目标点的密度和颜色都有了后用体渲染就可以渲染出最终结果了,也即生成器生成的结果。
然后我们还会从真实的图像中采样一些结果,和生成的结果一起输入判别器,从而让判别器学习真实图像的分布。
注意点:
1.文中为了加速训练,生成和采样均只合成了图像中的部分像素,并没有一次性生成整个图像。
2.其实刚开始读这个文章的时候有些难以理解,为什么不需要对相机位置做任何约束就可以学出来平滑的视角过渡?我个人认为是辐射场的效果,因为辐射场是隐式的建立了一个无限分辨率的3D物体,而最简单的建立出一个合理的3D物体的方式就是按照现实世界的3D结构来建立,因此可以保证视角过渡是平滑的。但如果作为参考的图像数量过少,或者物体结构过于简单,我认为是会出现一些奇奇怪怪的问题的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









