




能不拆就不拆
“假设你是一家电商网站的架构师,现在要将原有单点上百G的订单做数据重构,存储到多个节点上,你会如何设计存储策略?”
因为是存储扩容的设计问题,很容易想到做数据的分库分表。
明确一个原则,那就是能不拆就不拆,能少拆不多拆。
只有主从架构、读写分离等等,这些都没有效果之后,才考虑分库分表。
原因
开发成本、维护成本高,出问题概率要大。
分库分表不是一个事,而是三个事
1、只分库不分表
分库解决的是并发量大的问题。通过增加数据库的实例数,来提供更多的数据库可用连接,提升系统的并发度。
2、只分表不分库
分表解决的数据量大的问题。单表超过2000万,存储性能、查询性能都已经出现瓶颈。
3、既分库又分表
数据量大,就分表;并发高,就分库。
核心问题1:选择Sharding Key(分表字段)⭐
选择Sharding Key的最重要参考因素:业务是如何访问数据的?
对于用户平台(美团用户端),应该用UserId去分片
因为用户对于订单最高频访问的是app页面中“我的订单”页面,此时查询的条件是UserID。
1、如果分片依据是OrderID,那就没法查。只能强行去查询所有分片,然后合并查询结果,效率很低。分片就没有意义了;(查询所有分片库的所有分片表,通过 UNION ALL 的形式关联,该举动存在读扩散问题)
2、用UserID作为分片依据,此时用户在“我的订单”页面正好能用到Sharing Key,一个用户对应的订单都在一个分片中。此时效率最高,直接去对应分片中去查询就行了。
问题来了:用UserId分片之后,有需要用OrderID查询的场景怎么办?
基因编码:在生成OrderID的时候,可以UserID的后几位作为OrderID的一部分。比如18位的订单号,第15-18位是UserID的后四位,此时按照OrderID查询的时候,可以根据OrderID后四位的UserID找到分片。
问题又来了:用UserId分片之后,对于商家侧后台,商家查询自己的订单,需要用ShopID查询怎么办?
将原订单数据(以UserId分片)复制到新数据库中,但以ShopID作为分片键重新组织数据。商家通过 ShopID查询时,直接访问新库,根据 ShopID 快速定位到对应分片,提升查询效率。
需要额外存储一份数据,但这是有目的的冗余:
- 目的:解决原分片键(
UserId)无法高效支持ShopID查询的问题。 - 非简单复制:新数据以
ShopID重新分片,存储结构与原库不同,专门优化商家查询场景。
方案的核心是通过冗余存储和分片键转换,为商家查询需求构建独立的ShopID分片数据库。这种设计虽然增加了存储成本,但显著提升了商家侧的查询效率,是典型的分片键多副本策略,在高并发或复杂查询场景中常见。
核心问题2:分片算法的选择⭐
时间范围分片
- 热点数据:例如,电商大促期间的订单量可能远高于日常,导致对应分片负载过高。
- 分片浪费:若按时间分片(如按月),旧的订单集中在一个或者几个分片中,访问量很少。
Hash分片
- 哈希算法(如
hash(UserID) % N)将数据均匀分散到各个分片,避免了时间范围分片(如按 年/月 分库)可能导致的 数据倾斜(如某些时间段订单量激增,导致对应分片负载过高)、热点Key集中(查询的全都是近期的订单记录)。 - 一致性哈希(Consistent Hashing):通过将哈希值映射到一个环形空间(如
2^32环),新增或删除节点时只需重新分配少量数据。
扩展性保证
需要二次扩容时,比如20个分片要扩大到50个,需要重新计算Hash值,映射关系会变化,就会涉及到迁移问题。
- 所有数据的哈希值需要重新计算模数,导致几乎全部数据需要迁移
- 这会引发 数据倾斜(扩容瞬间部分分片负载过高)和 性能波动(大量数据迁移导致写入阻塞)
为了解决扩容问题,可以采用 “一致性哈希” 的方式来做分表
不同点:一致性哈希可以按照常用的hash算法来将对应的key哈希到一个具有 2^32 个节点的空间中,形成一个顺时针首尾相接的闭合的环形。所以当添加一台新的数据库服务器时,只有增加服务器位置的顺时针方向的第一个分片上的键会受影响。
假设哈希环上有节点 A、B、C,新增节点 D 后(在A、B之间),仅需迁移 B 和 D 上的数据,其他区域数据不变。
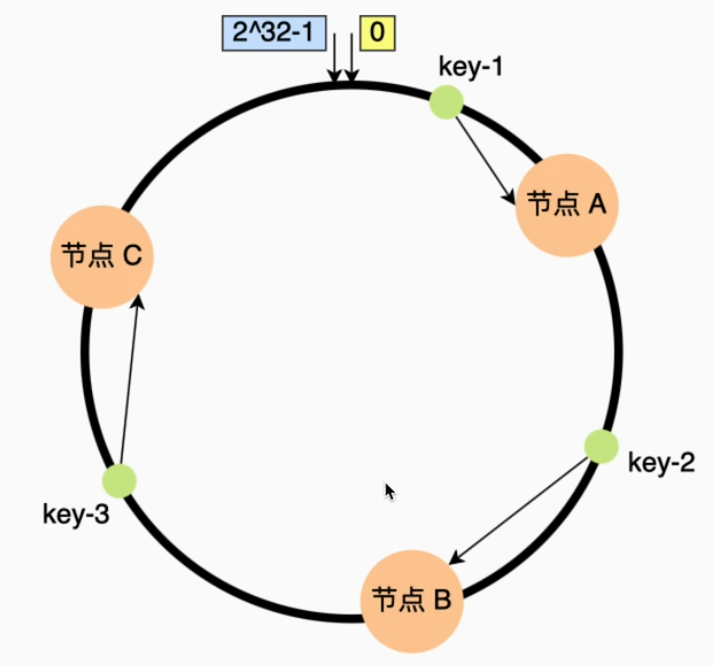
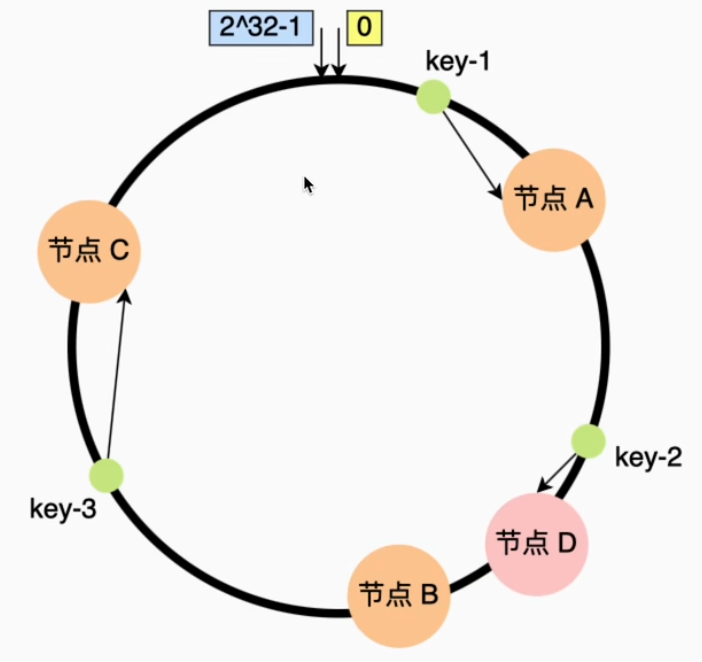
一致性Hash分片的优点:数据可以较为均匀地分配到各节点(分片),其并发写入性能表现也不错。

















 3138
3138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









