









标题:Look Ma, no landmarks - Unsupervised,model-based dense face alignment
链接:https://eprints.whiterose.ac.uk/164093/1/4043.pdf
这篇文章讲的是如何在无监督的情况下将3DMM拟合到2D图像上。
文章有些难以理解,因为用了大量的图形学知识,不过大体上讲一讲还是没问题的。
首先,为了无监督的学习3D人脸重建,那么重要的就是如何表示3D人脸和如何判断3D人脸的重建效果。
这里作者提出可以直接将shape(位置)和albedo(颜色)这两个参数都用UV map的形式表示,就像下图这样:
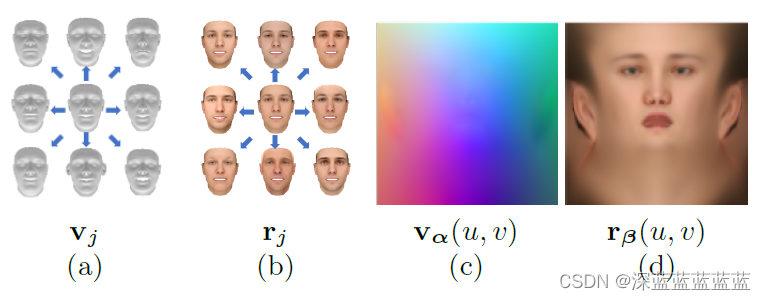
a和b是形状和颜色,c和d是形状和颜色转换成UV map后的样子。
之后再将UV map中对应的位置反映射回原始图像,从而得到和原始图像结构一样的shape和albedo表示:

a是输入的2D图,b和c是shape在UV map上的的u和v的坐标,d是shape的uv坐标一起放到一张图上,e是albedo的uv值放到图像上。而这b-e就是坐着所谓的correspondence map了。
但为什么要这些correspondence map呢,因为作者说从这几张correspondence map中我们可以完美的回归3DMM参数,因此可以不需要额外的回归器了。
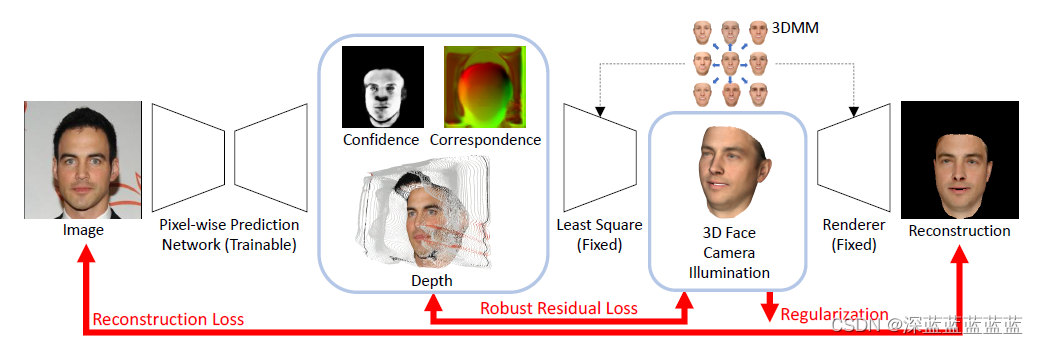
如图结构图中所示,作者训练了一个U-Net来直接生成这些correspondence map用来代替3DMM中的参数,另外还用了个confidence map用来避免模型从遮挡部分获得奇奇怪怪的信息,并且这个confidence map还可以用作皮肤的语义分割。另外,作者还预测了个深度图。
之后,在获得这些信息后作者就通过least square公式来拟合对应的3D模型了,最后再用一个固定的可微渲染器来生成最终的2D图像。
作者在最终渲染的图像和输入图像间做了重建损失,还在深度图和3D模型间做了位置损失,从而让整个框架端到端的训练。

















 8204
8204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









