




 该文章介绍了如何利用Python和深度学习库Yolov5训练车牌检测模型。首先,从Kaggle下载数据集,然后在GoogleColab上创建训练和验证目录,将XML标注文件转换为Yolo所需的TXT格式。接着,分割数据集并设置训练参数,最后运行训练脚本来训练模型。训练完成后,模型可用于车牌检测,进一步结合OCR技术实现车牌文字识别。
该文章介绍了如何利用Python和深度学习库Yolov5训练车牌检测模型。首先,从Kaggle下载数据集,然后在GoogleColab上创建训练和验证目录,将XML标注文件转换为Yolo所需的TXT格式。接着,分割数据集并设置训练参数,最后运行训练脚本来训练模型。训练完成后,模型可用于车牌检测,进一步结合OCR技术实现车牌文字识别。
续写序列Python深度学习,想了解更多可点击上篇超赞的学习笔记——《Python深度学习6:预测顾客是否流失》_wpgddt的博客-优快云博客
►前言
现在许多停车场使用车牌识别系统,停车时需要先使用摄像头拍摄图像,透过AI检测车牌再进行识别,本篇博客介绍如何训练车牌检测模型。
►代码讲解
在Kaggle网站内搜寻Car License Plate Detection并下载,解压缩文件夹,更改名称为“CarLicensePlateDetection”,将文件夹上传至Google云端硬盘,开启Colab并设定为GPU执行,连接Google云段硬盘。
先建立训练文件夹,代码如下:
import numpy as np
import pandas as pd
import os
import numpy
os.mkdir(“/content/plate_train_data”)
os.mkdir(“/content/plate_train_data/images”)
os.mkdir(“/content/plate_train_data/labels”)
os.mkdir(“/content/plate_train_data/images/train”)
os.mkdir(“/content/plate_train_data/images/val”)
os.mkdir(“/content/plate_train_data/labels/train”)
os.mkdir(“/content/plate_train_data/labels/val”)将xml文件转换为txt文件,因为Yolo需要使用归一化边界框的txt文件,格式为「class id,x,y,width,height」,数据呈现如下:
0 0.39375 0.34615384615384615 0.0975 0.05263157894736842
0 0.64375 0.35020242914979755 0.0625 0.06072874493927125
转换代码如下:
import xml.etree.ElementTree as ET
from xml.dom.minidom import parse
path =“/content/drive/MyDrive/AI/dataset/CarLicensePlateDetection/annotations”
classes = {“licence”:0}
for annotations in os.listdir(path):
dom = parse(os.path.join(path,annotations))
root = dom.documentElement
filename =“.txt”.join(root.getElementsByTagName(“filename”)[0].childNodes[0].data.split(“.png”))
image_width = root.getElementsByTagName(“width”)[0].childNodes[0].data
image_height = root.getElementsByTagName(“height”)[0].childNodes[0].data
with open(“/content/plate_train_data/labels/train/”+filename,“w”)as r:
for items in root.getElementsByTagName(“object”):
name = items.getElementsByTagName(“name”)[0].childNodes[0].data
xmin = items.getElementsByTagName(“xmin”)[0].childNodes[0].data
ymin = items.getElementsByTagName(“ymin”)[0].childNodes[0].data
xmax = items.getElementsByTagName(“xmax”)[0].childNodes[0].data
ymax = items.getElementsByTagName(“ymax”)[0].childNodes[0].data
x_center_norm =((int(xmin)+int(xmax))/ 2)/ int(image_width)
y_center_norm =((int(ymin)+int(ymax))/2)/ int(image_height)
width_norm =((int(xmax)-int(xmin))/int(image_width))
height_norm =((int(ymax)-int(ymin))/int(image_height))
r.write(str(classes[name])+“”)
r.write(str(x_center_norm)+“”)
r.write(str(y_center_norm)+“”)
r.write(str(width_norm)+“”)
r.write(str(height_norm)+“\n”)复制CarLicensePlateDetection内的image至plate_train_data/images/train
import shutil
path =“/content/drive/MyDrive/AI/dataset/CarLicensePlateDetection/images”
for images in os.listdir(path):
image_path = os.path.join(path,images)
shutil.copy(image_path,“/content/plate_train_data/images/train/”+images)将训练数据集随机数分割120至验证数据集内
from random import shuffle
from glob import glob
import random
import shutil
random.seed(42)
files = glob(“/content/plate_train_data/images/train/*.png”)
shuffle(files)
txt_train_path =“/content/plate_train_data/labels/train/”
img_train_path =“/content/plate_train_data/images/train/”
txt_val_path =“/content/plate_train_data/labels/val/”
img_val_path =“/content/plate_train_data/images/val/”
for i in files[:120]:
filename = i.split(“/”)[-1]
shutil.move(txt_train_path+filename.replace(“.png”,“.txt”),\
txt_val_path+filename.replace(“.png”,“.txt”))
shutil.move(img_train_path+filename,img_val_path+filename)建立yaml档案,train后面为train数据集位置
%cd /content
!echo“train: /content/plate_train_data/images/train”> licence.yaml
!echo“val: /content/plate_train_data/images/val”>> licence.yaml
!echo“nc:1”>> licence.yaml
!echo“names: ['licence']”>> licence.yaml下载Yolov5,并安装相关套件
%cd /content/
%rm -rf yolov5
!git clonehttps://github.com/ultralytics/yolov5
%cd yolov5
!pip install -r requirements.txt开始训练
--img为图象大小
--batch批次量
--epochs循环几次
--data训练数据的yaml档案
训练指令如下:
!python train.py --weights yolov5s.pt --cfg models/yolov5s.yaml --img 416 --batch 48 --epochs 40 --data /content/licence.yaml --cache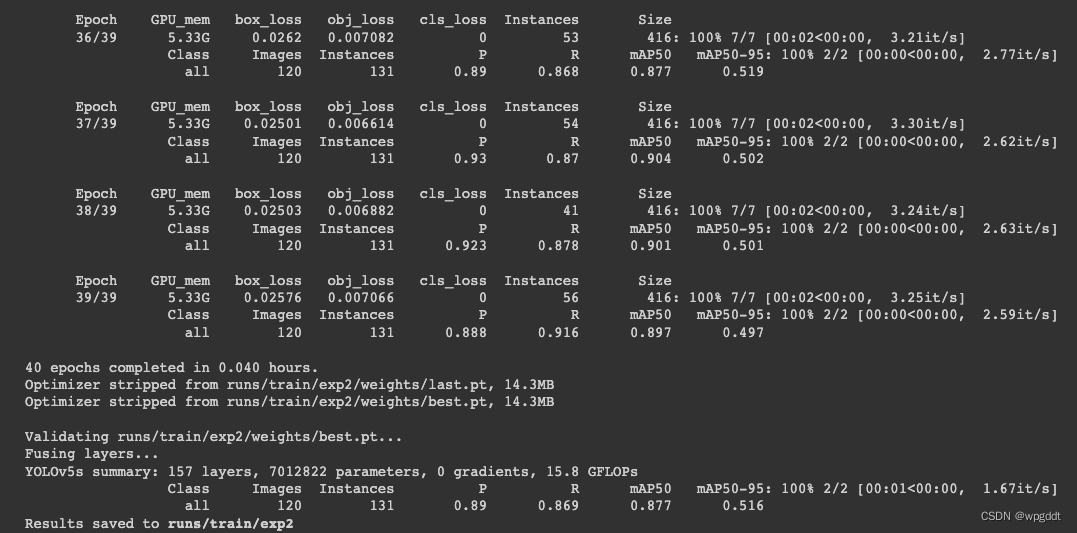
P(Precision)为正确数/预测总数
R(Recall)为预测正确数/真实总数
mAP(mean Average Precision):每个类的AP值的平均数,mAP越高,推论准确度越好。
mAP50-95表示在不同区段IoU阔值,从0.5~0.95,间隔0.05
训练完成后显示推论结果
from IPython.display import Image
Image('/content/yolov5/runs/train/exp/val_batch0_labels.jpg')
►小结
以上流程是使用Yolov5训练车牌检测的流程,当检测出车牌就可以裁切进行文字OCR,让客户缴费时输入自己的车牌,点选自己的车子照片进行缴费,之后有空再来整理发文。


















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









