




搭建一个dify 工作流,不是目的。我们希望的是可以在具体的业务中使用起来。所以避免不了要通过api 的方式。
本文将教会你如何一步一步对接一个工作流,看完这个教程,我相信你可以对接所有的工作流。
工作流搭建教程: 票据识别工作流搭建
一个工作流,本想着一会就对接完毕,没想到坑不少。
每一个细节不对,都无功而返,折腾了几个小时。
终于走完了全流程。废话不多说,来,走起。
一、首先,阅读:票务识别工作流的api:
无论对接什么平台,仔细阅读api 是必须的。
可以看出这个工作流包含7个接口。
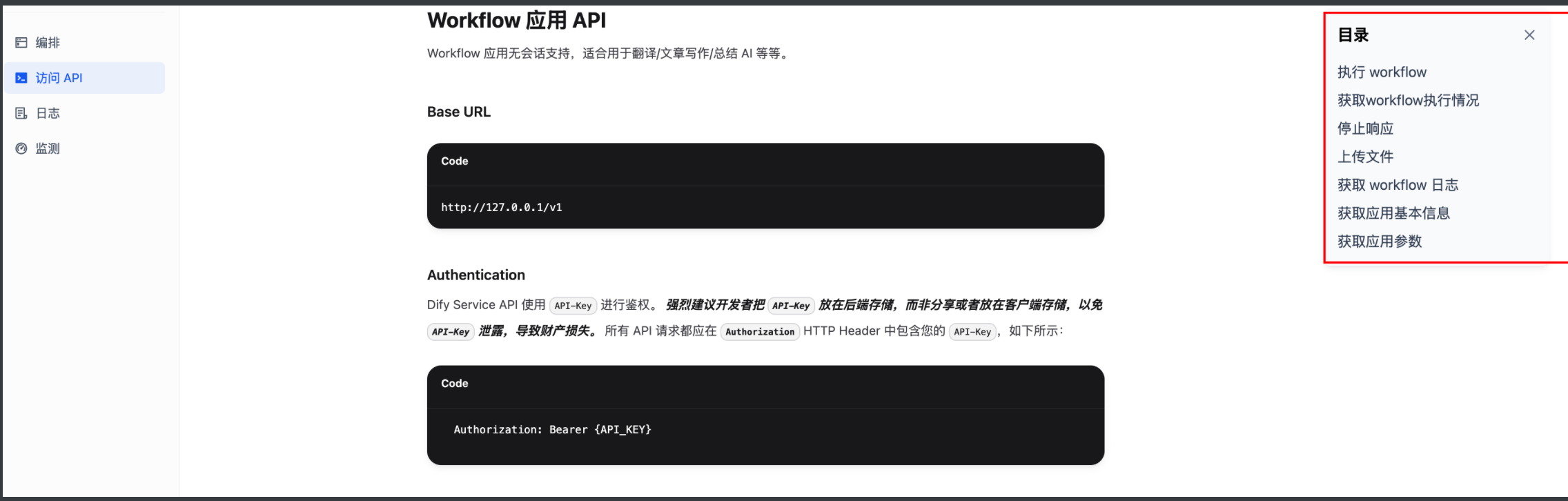
因为我们的目的是执行工作流,所以第一个接口,必须是执行工作流;
重点关注:执行 workflow

从图中可以看出,这个接口有3个参数:
-
response_mode: 很好理解。使用推荐的 streaming 即可。
-
User:一个唯一标识符。也好理解。
-
Inputs: 这个就麻烦了,看不懂。inputs 解释的最后一句话,如果是文件类型,就需要一个以下files 中所描述的对象。files 如下图所示:

先读files, 属性 transfer_method 很重要。即文件选择本地还是网络。即支持本地上传和从网络读取。
我们这里实验本地读取。
从图中1 和 2 的对比可以看出, inputs 中是放了一个 key-value 模式的参数。 Value 是一个对象,包含3个参数。key 从哪里来呢? 可以看出图中2 ,ke y 是用{}大括号圈起来的。
重点来了:打开工作流,在开始节点,新增变量。 p 。
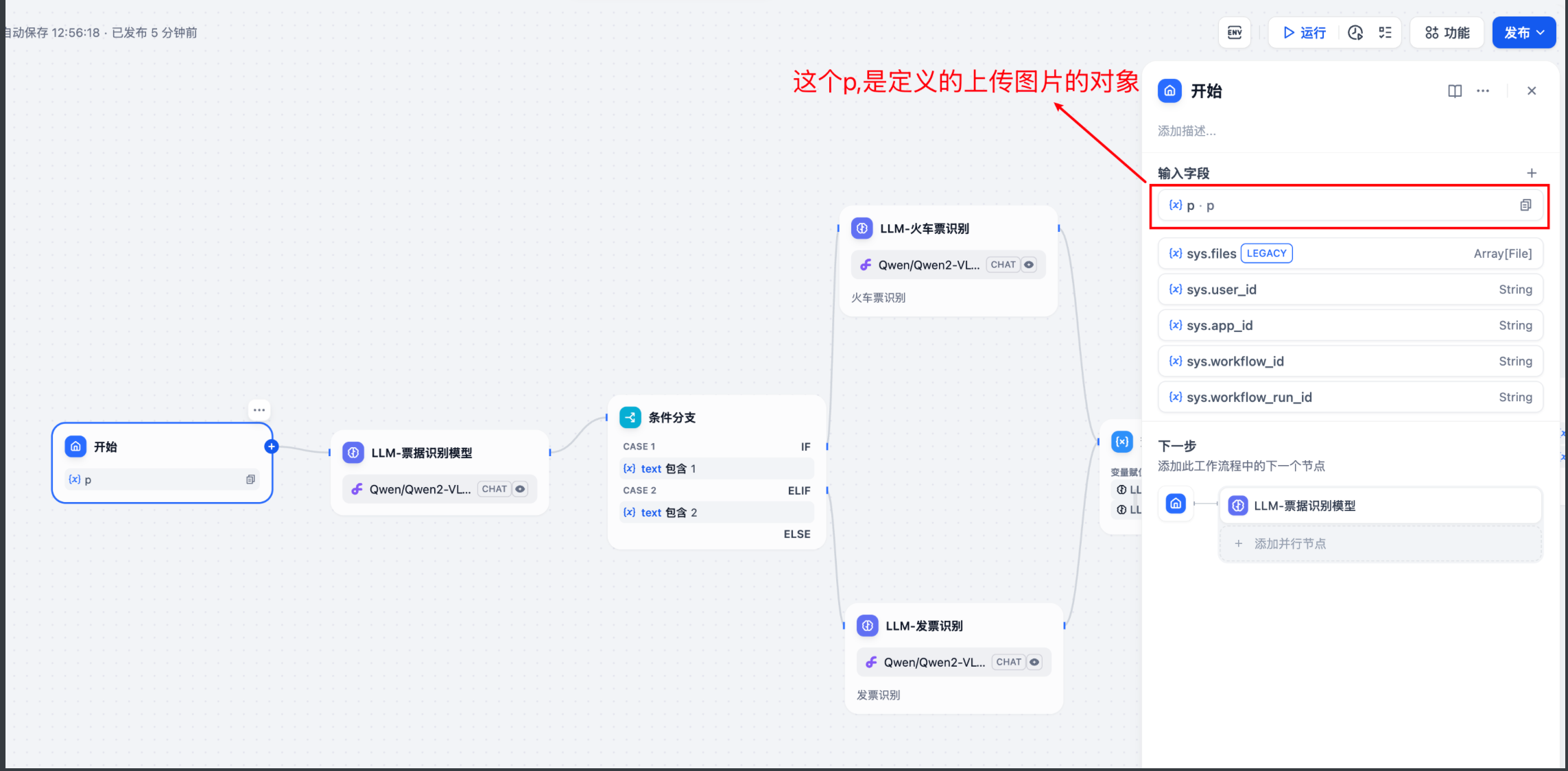
完整的传参:
{
"inputs": {
"p": [{
"transfer_method": "local_file",
"upload_file_id": "3954b2dd-f1f4-4ba4-8528-31b479f09537",
"type": "image"
}]
},
"response_mode": "streaming",
"user": "abbbacc-123123"
}
需要注意的是: 我们选择了本地上传。 从 files 的介绍中可以看出,我们需要一个upload_file_id。从哪里来呢?
就需要下面的上传图片接口:会返回一个id.
接口:上传图片

二、介绍完毕,开始实操:
2.1 创建api-key:
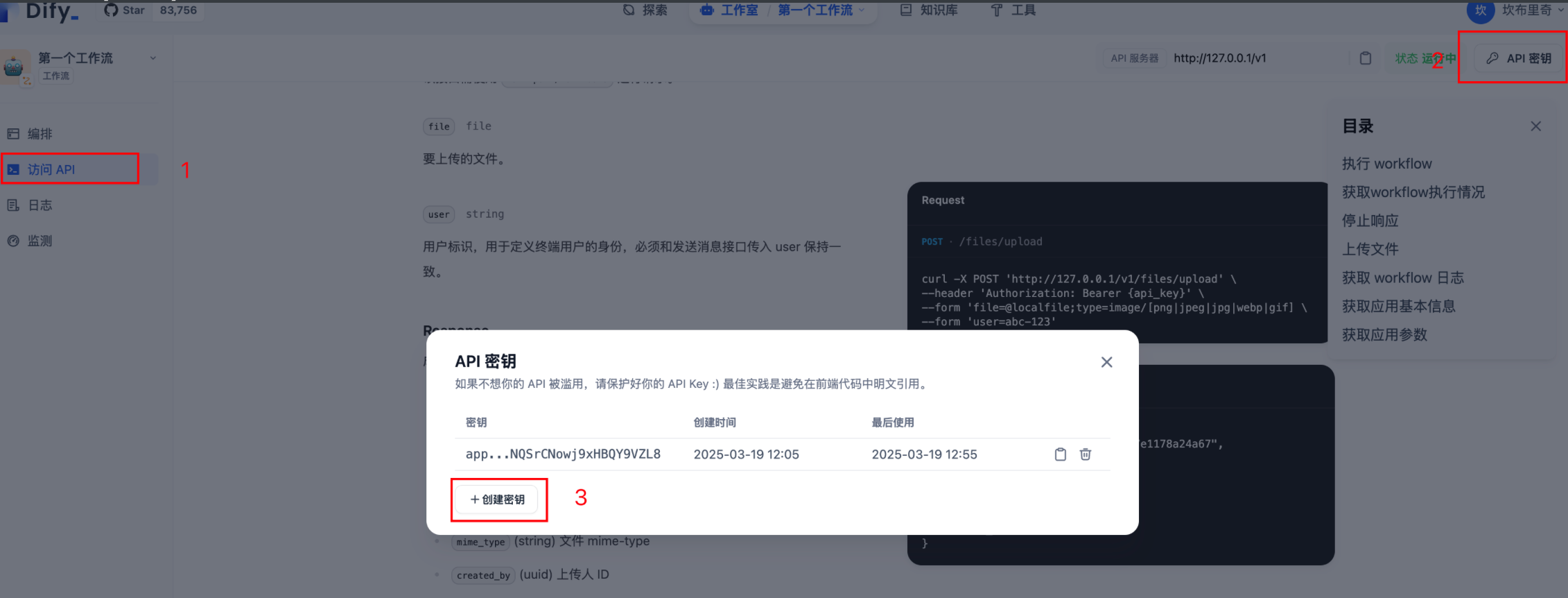
通过图中1,2,3 即可获取一个密钥。
2.2 配置上传图片的变量:
这里至关重要,不创建变量。在执行工作流的时候,没有key,无法传参。
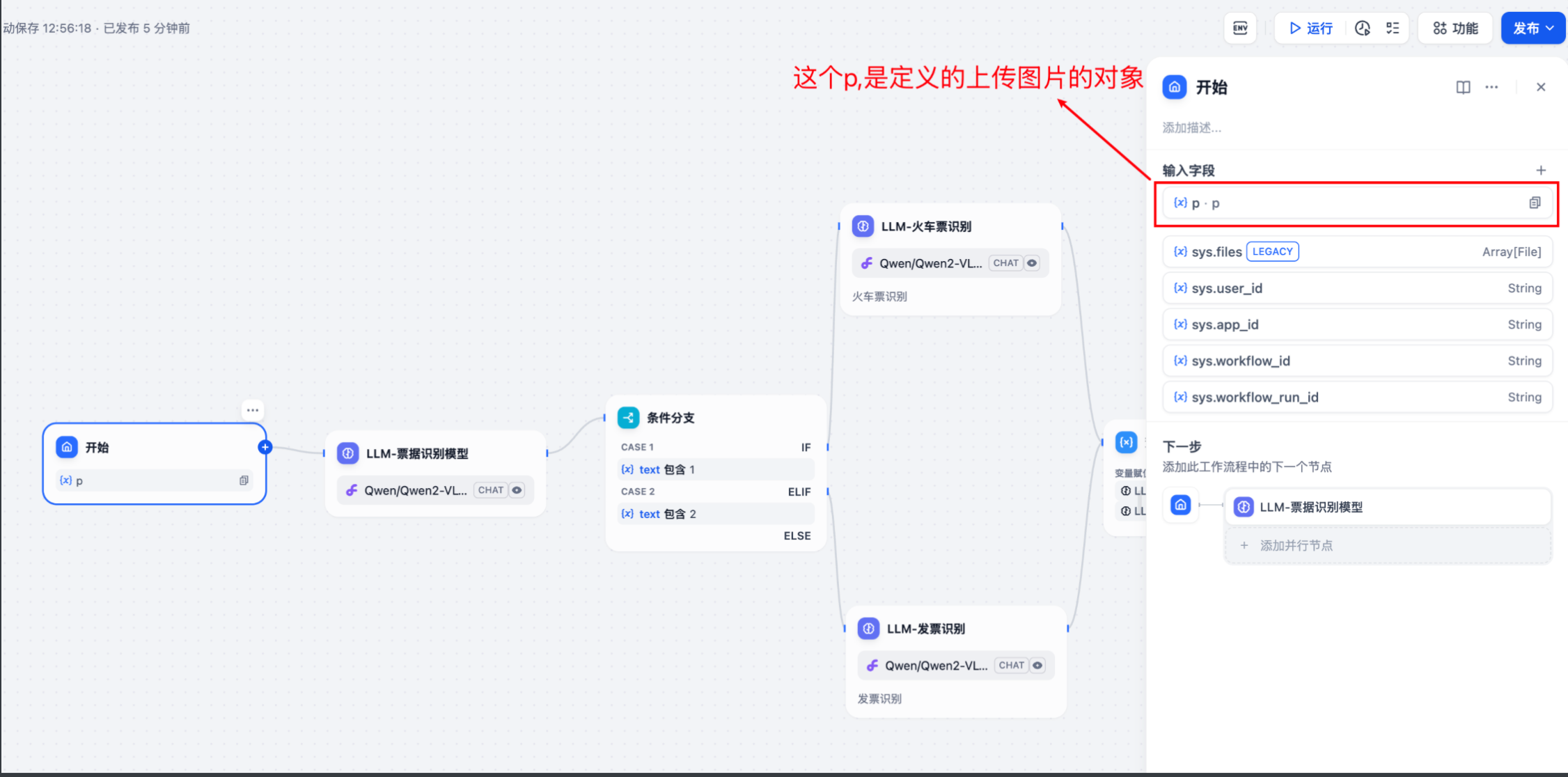
2.3 调用上传图片接口:
1. 复制 curl ,导入到 apifox 中:
2.添加参数;
3. 执行;
记得添加端口号。默认的请求没有端口号
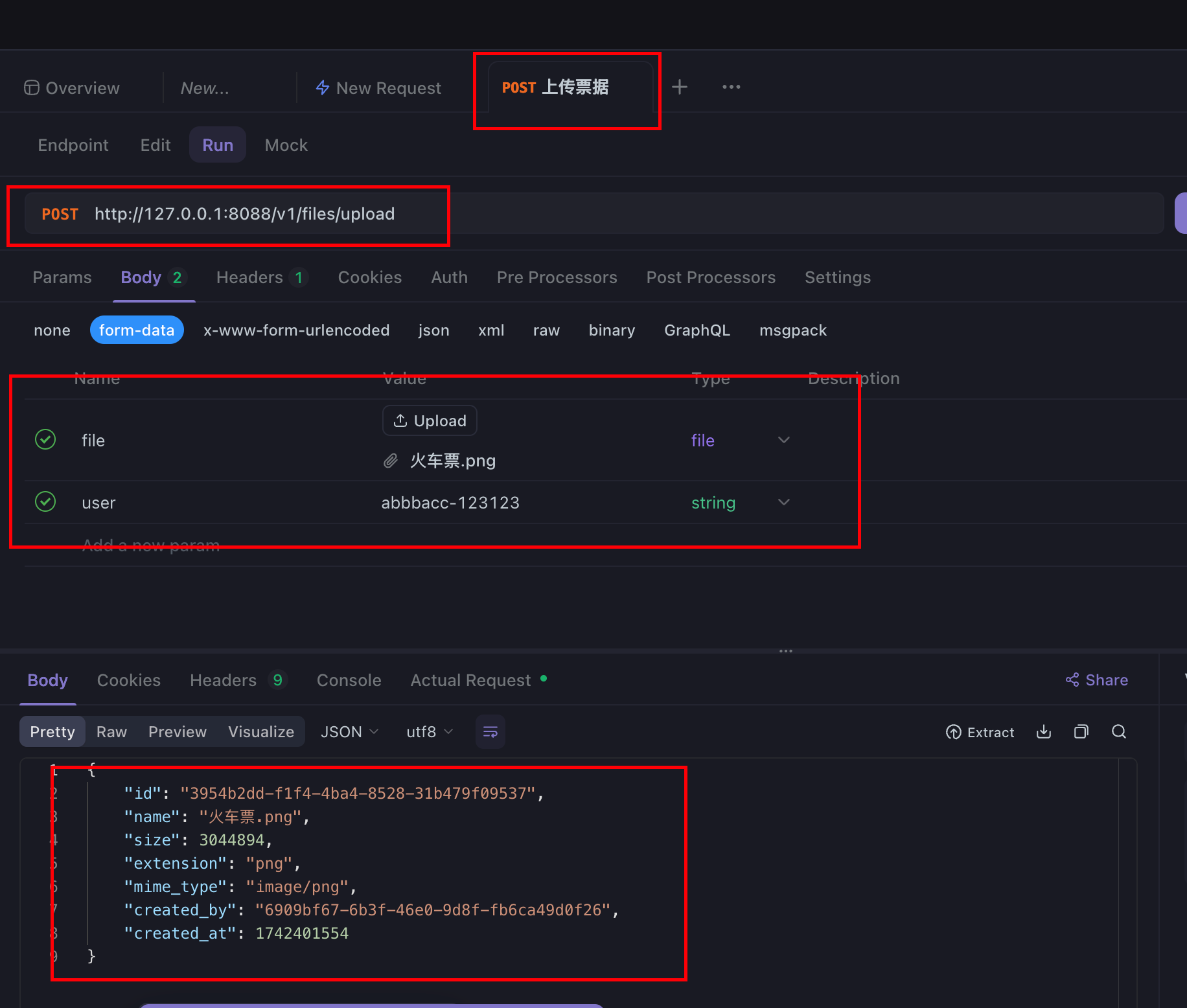
4. 保存返回的 id.
2.4 调用: 票务识别工作流
导入接口:
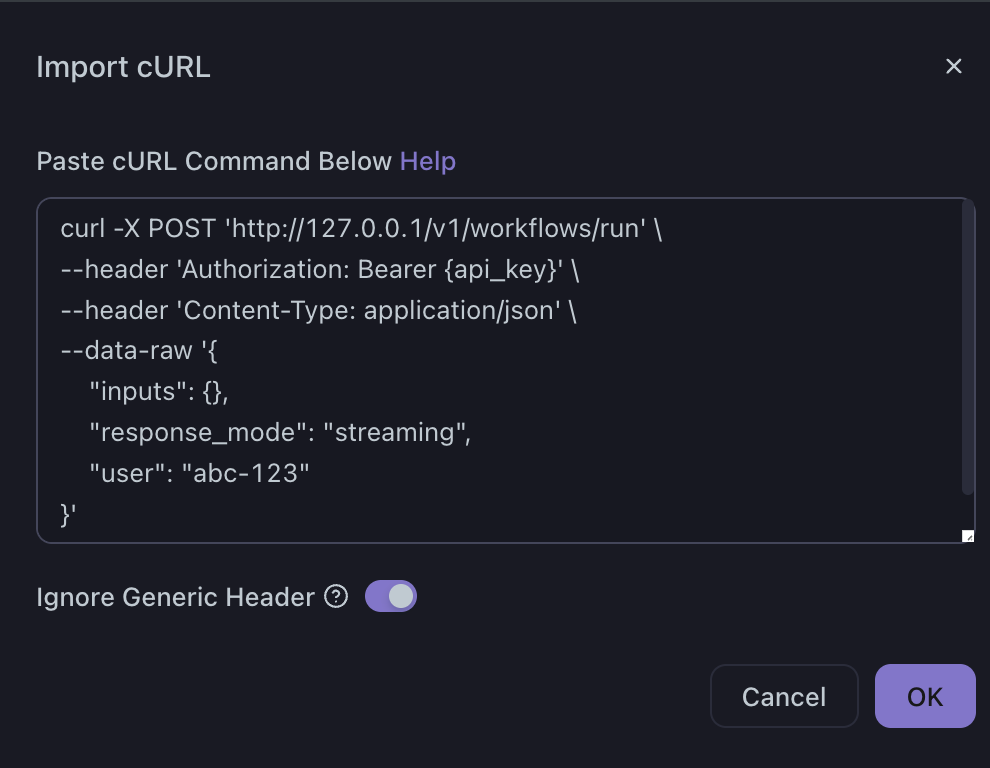
添加参数:
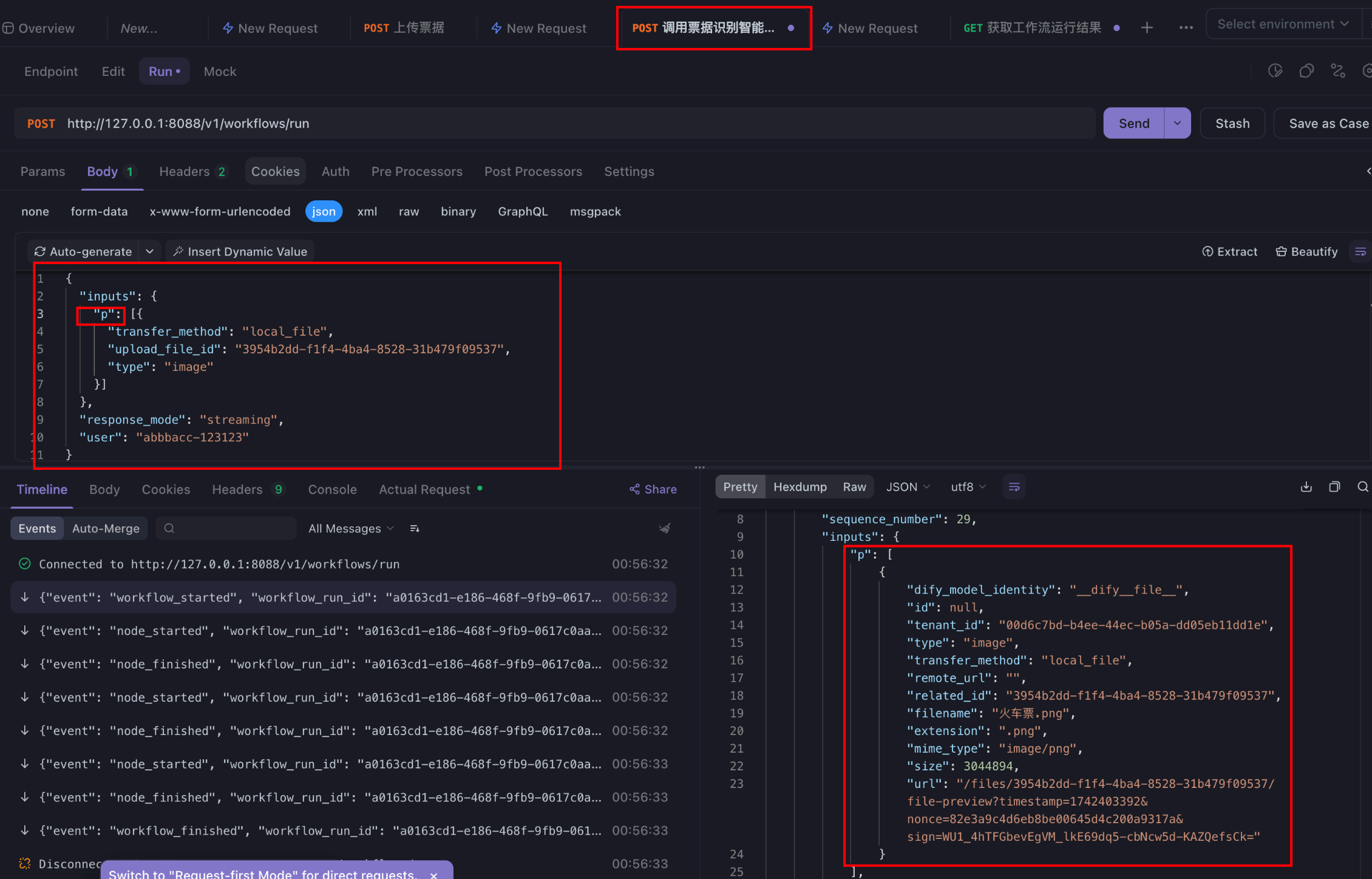
执行,结果如下:
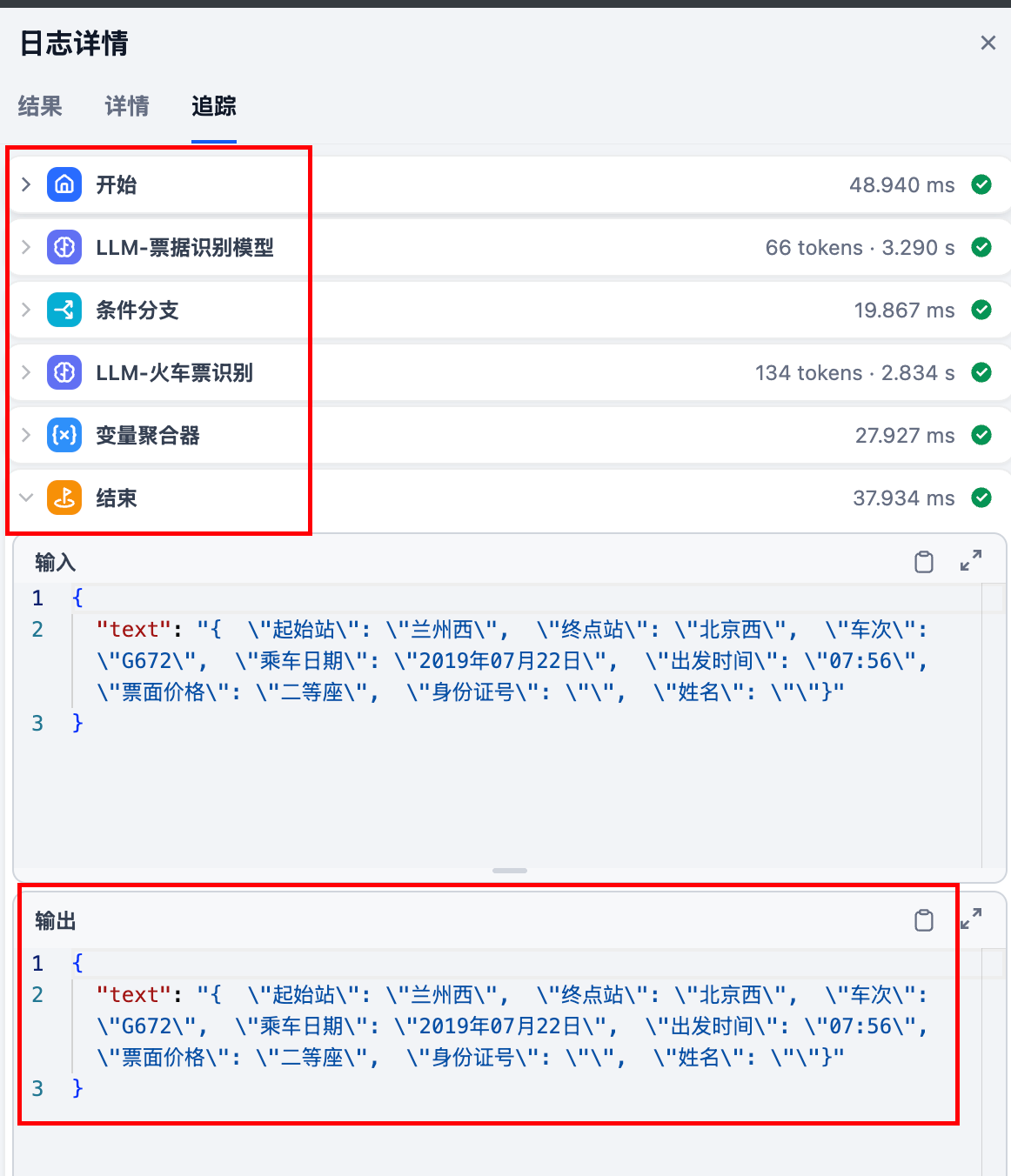
2.5 在dify 中查看调用记录,现实成功:
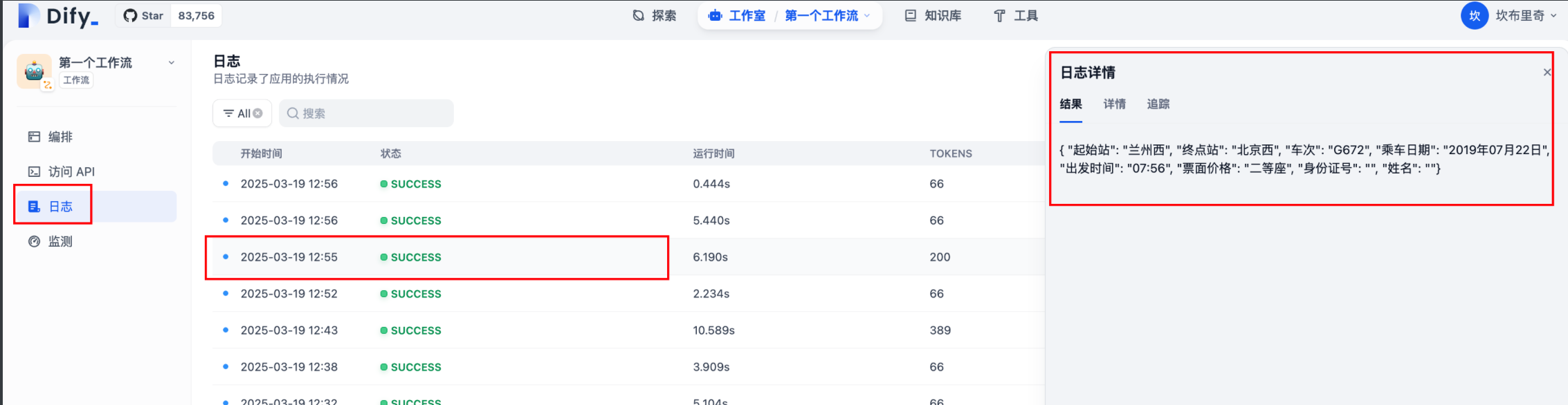
日志分析:
三、总结:
在apifox 可以调用成功,就说明这个接口可以在我们的服务中使用了。可以对接到业务中了。
下一篇将介绍: agent+工作流,如何使用。

















 4764
4764





 到【灌水乐园】发言
到【灌水乐园】发言







