




Dify最牛的地方就是像搭积木一样简单——不用懂代码,普通人稍微学学就能用它的「智能机器人」和「流程图」功能,自己拼出一套自动化工具。比如自动回复客户、处理文件这些事,你拖拖拽拽就能搭出想要的功能,特别适合折腾些好玩的小发明。
我们可以通过智能体或工作流,自定义工具完成很多我们好玩的功能。
报文篇幅较长,简单说下内容:
- 从0开始创建一个票务识别智能体;
- 介绍搭建过程中的各个细节;
- 教会你每一步为什么,而不是只是完成;
通过实践这个流程,我相信你可以学会自己搭建自己需要的智能体。
一、Dify 工作流:
工作流通过将复杂的任务分解成较小的步骤(节点)降低系统复杂度,减少了对提示词技术和模型推理能力的依赖,提高了 LLM 应用面向复杂任务的性能,提升了系统的可解释性、稳定性和容错性。
Dify 工作流分为两种类型:
- Chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。
- Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
二、如何开始呢?
- 从一个空白的工作流开始构建或者使用系统模版帮助你开始;
- 熟悉基础操作,包括在画布上创建节点、连接和配置节点、调试工作流、查看运行历史等;
- 保存并发布一个工作流;
- 在已发布应用中运行或者通过 API 调用工作流;
根据这四步,我们一步一步来实现。
三、创建火车票单类票据识别智能体工作流:
3.1 创建工作里空白应用:
在首页,选择 工作室-> 工作流-> 创建空白应用
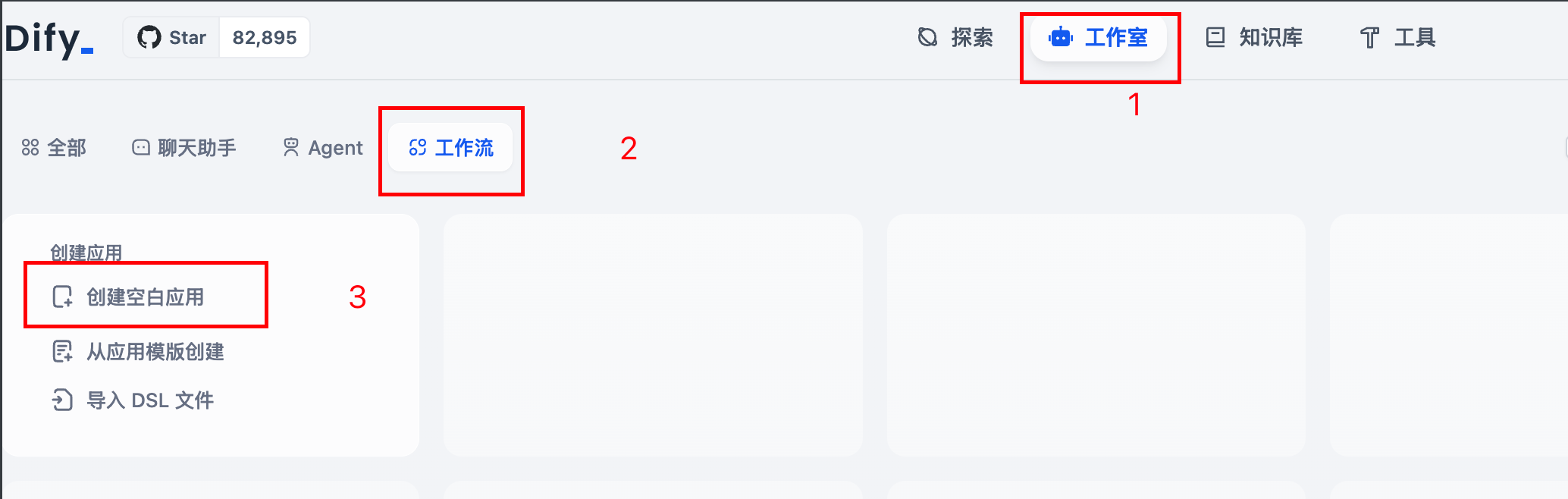
按照下图所示 1-> 2 -> 3 ,操作
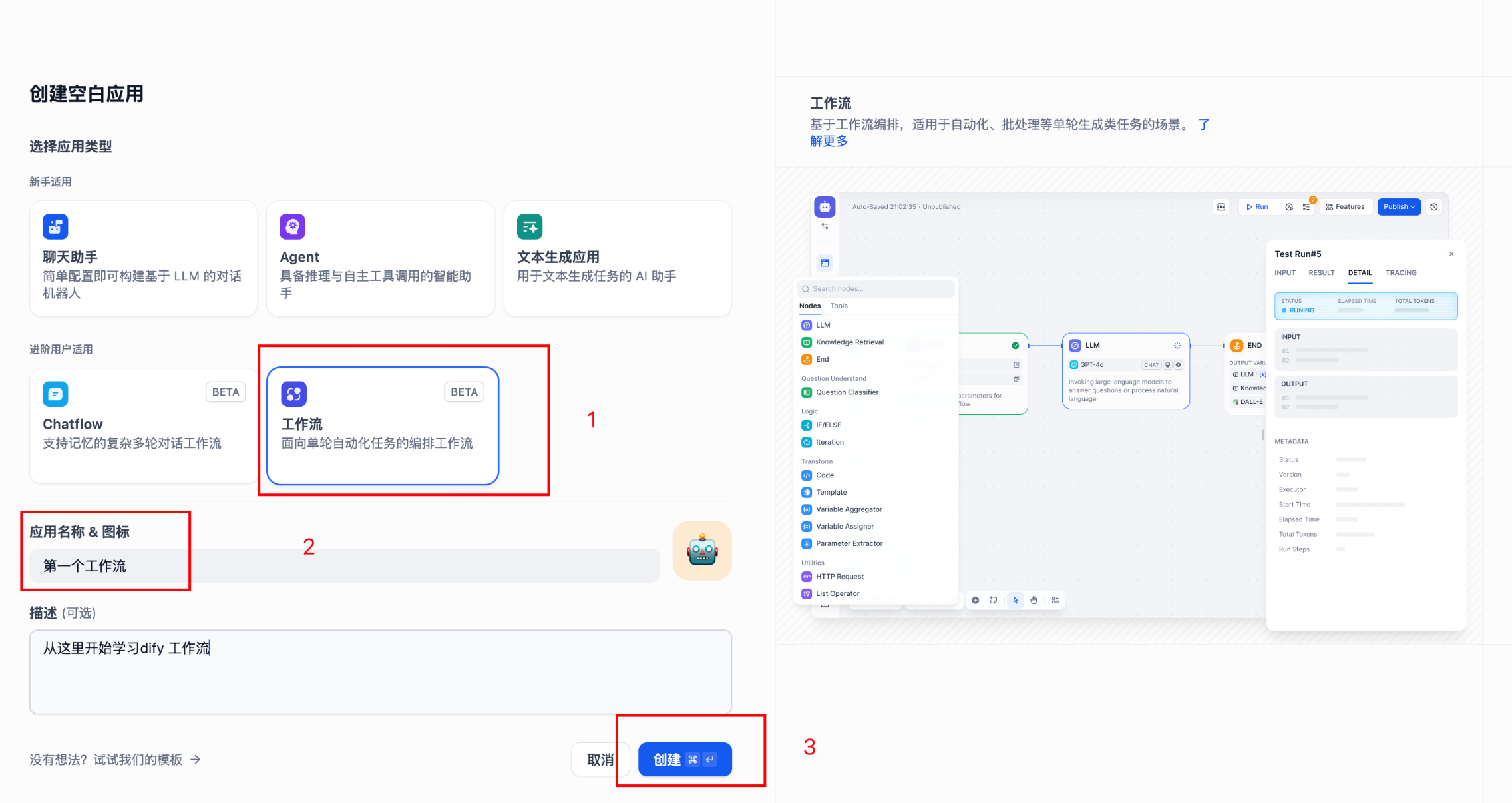
工作流创建成功:
3.2 添加节点:
点击 + 号,添加节点。
选择自己需要的节点:我们这里选择 LLM
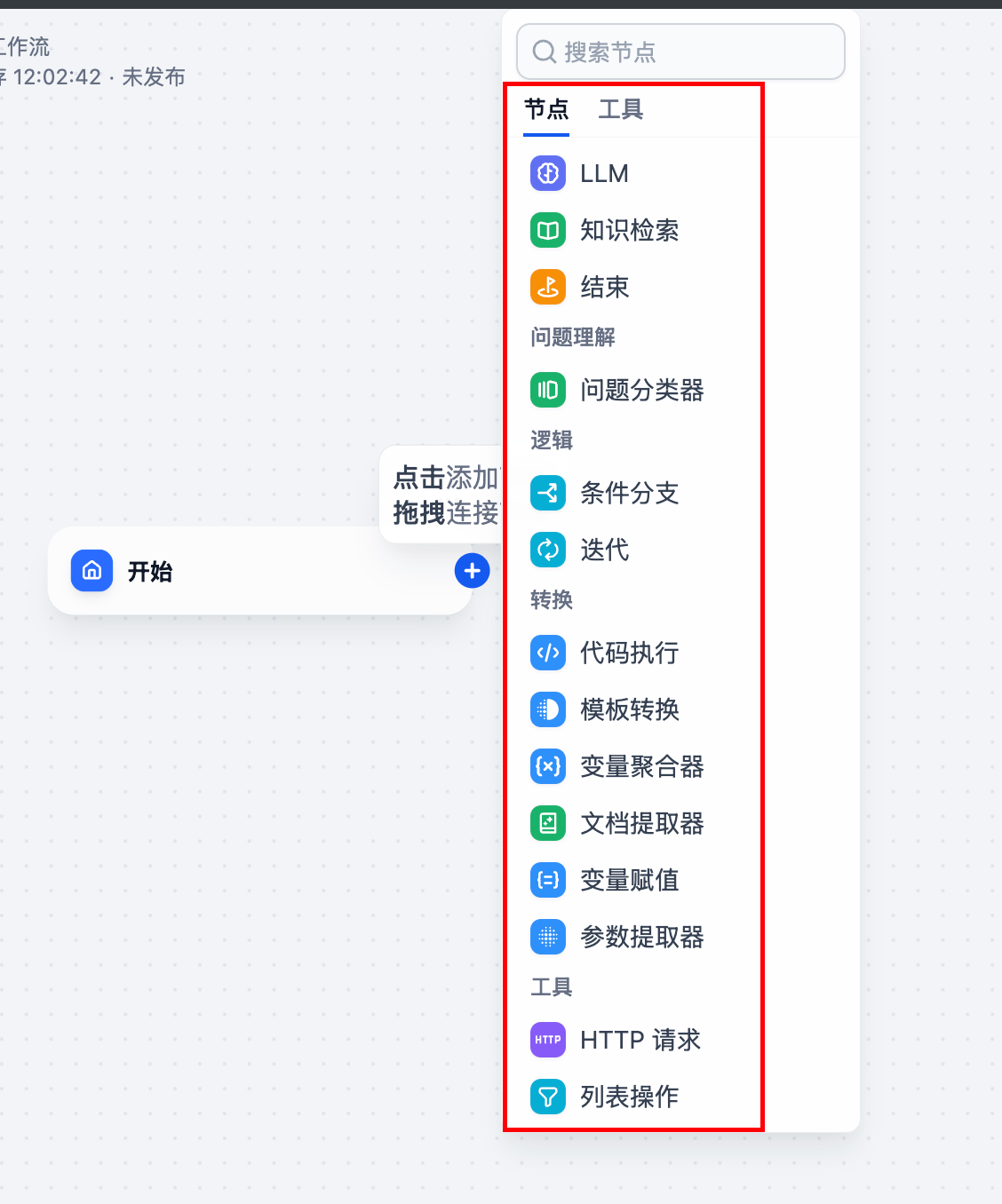
3.3 选择LLM 节点后如下:
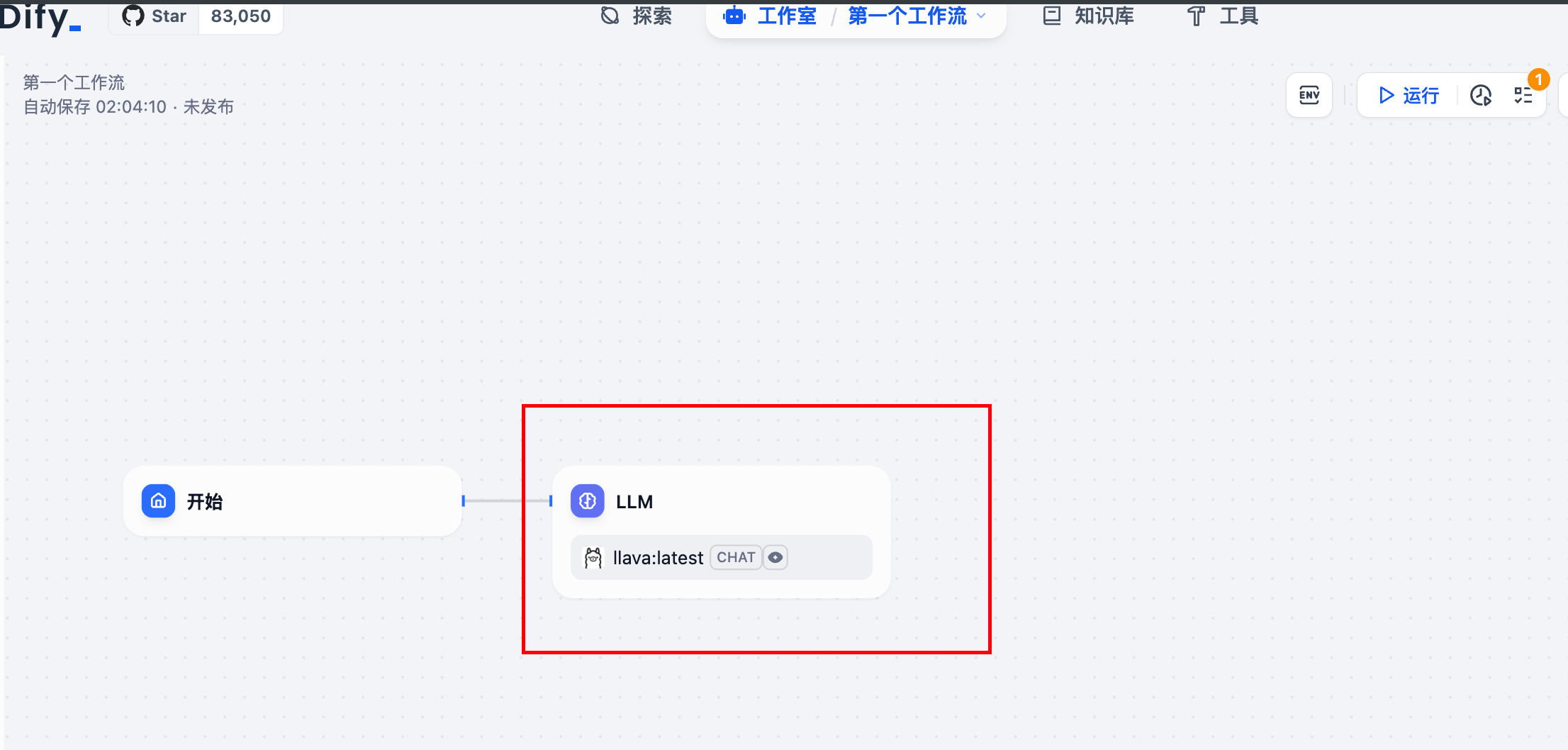
3.4 修改配置LLM
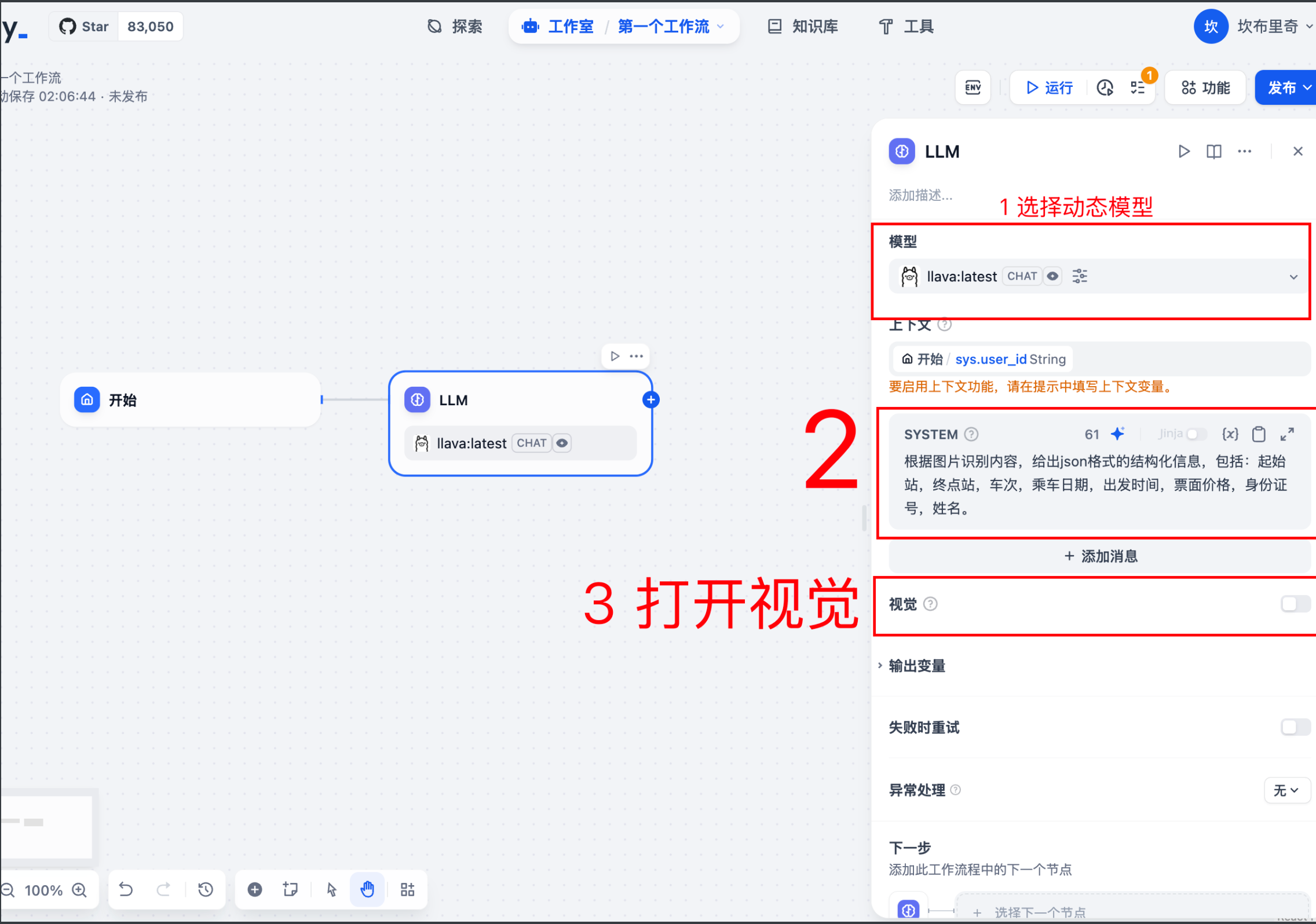
-
选择模型,这里选择的模型需要支持:
多模态输入的大模型。因为要使用视觉。我这里使用的是通过ollama 部署的 llava 本地模型。 -
输入角色提示词,在
SYSTEM中填入:根据图片识别内容,给出json格式的结构化信息,包括:起始站,终点站,车次,乘车日期,出发时间,票面价格,身份证号,姓名。
因为我们的任务非常简单,因此无需复杂的提示词,只要把你的要求清晰表达出来即可。
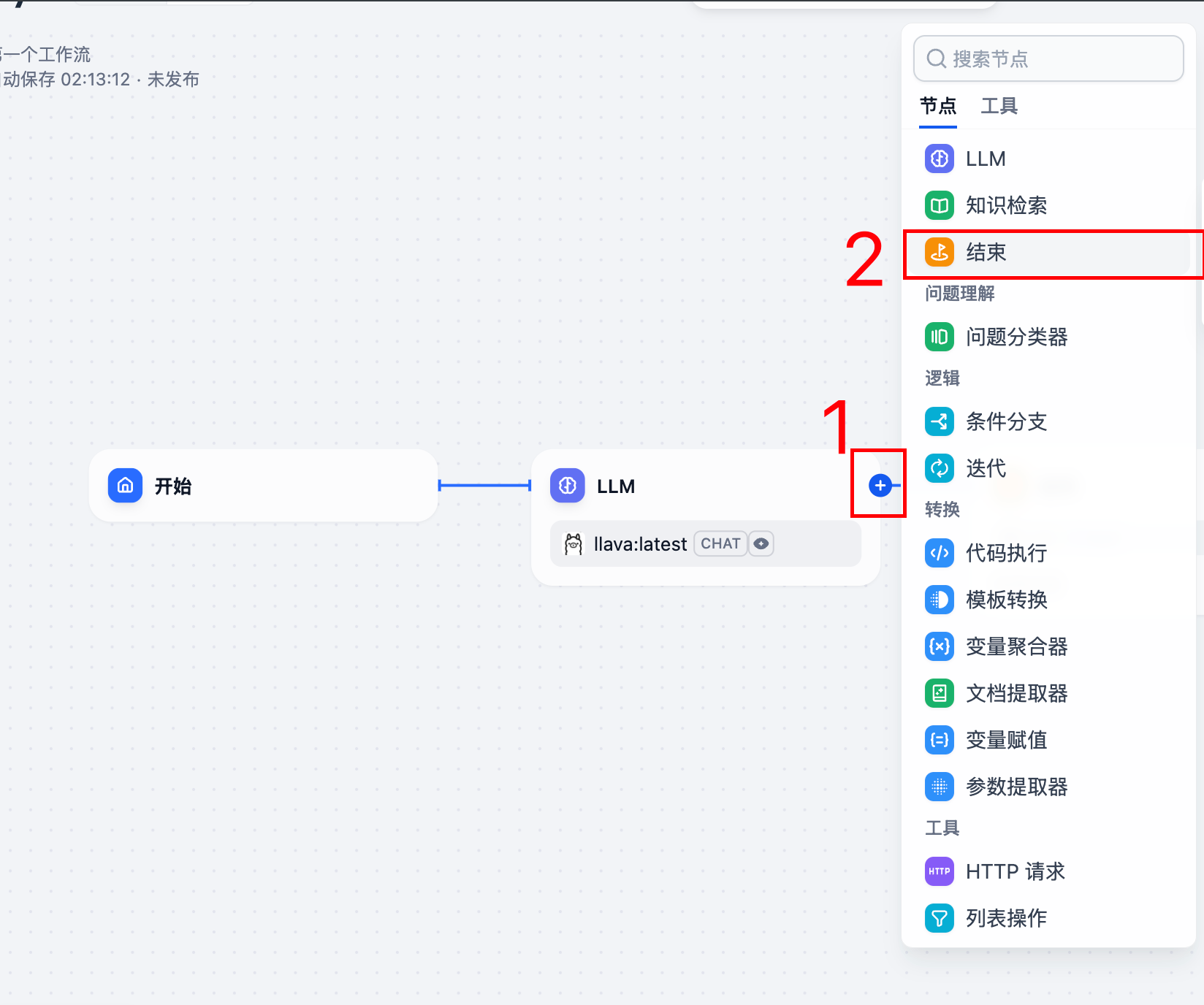
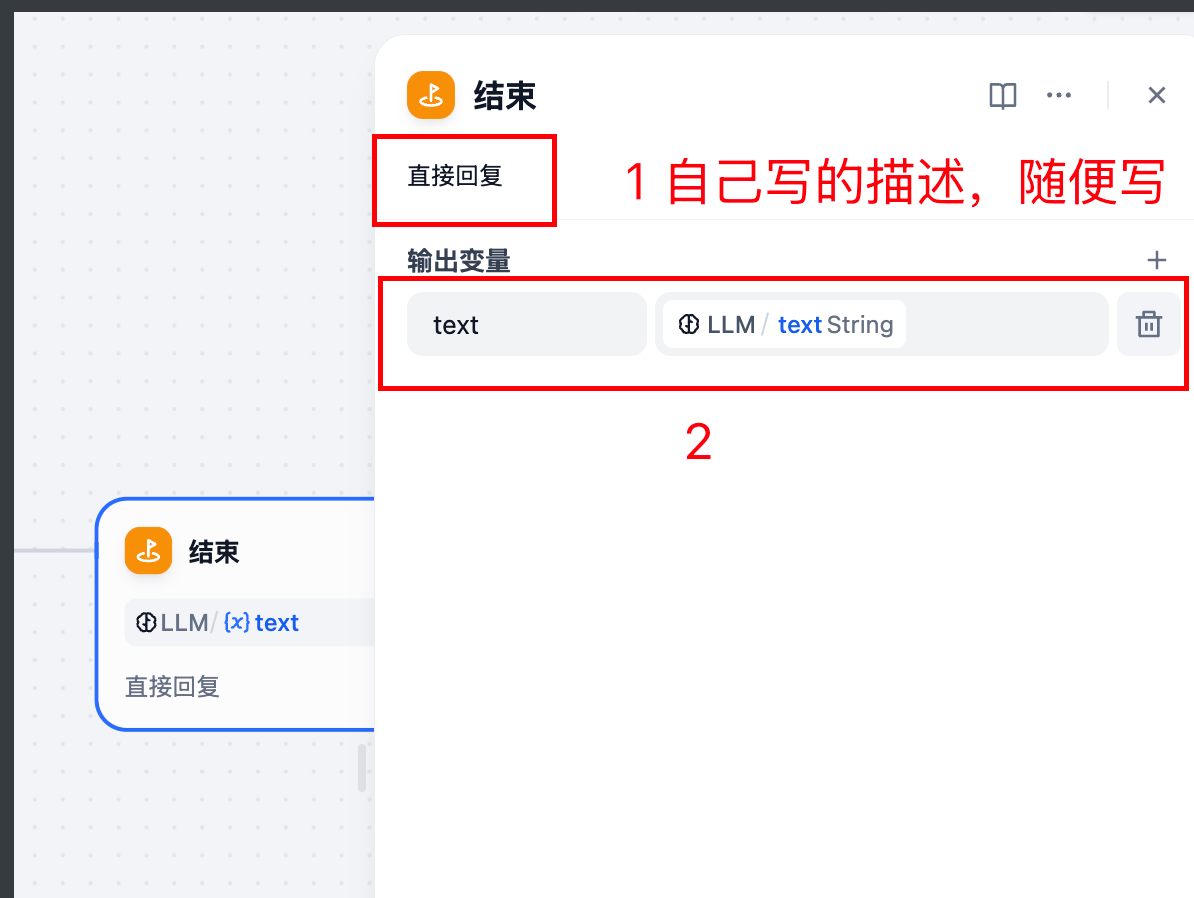
3.5 一个火车票识别智能体就搭建完了。点击发布。
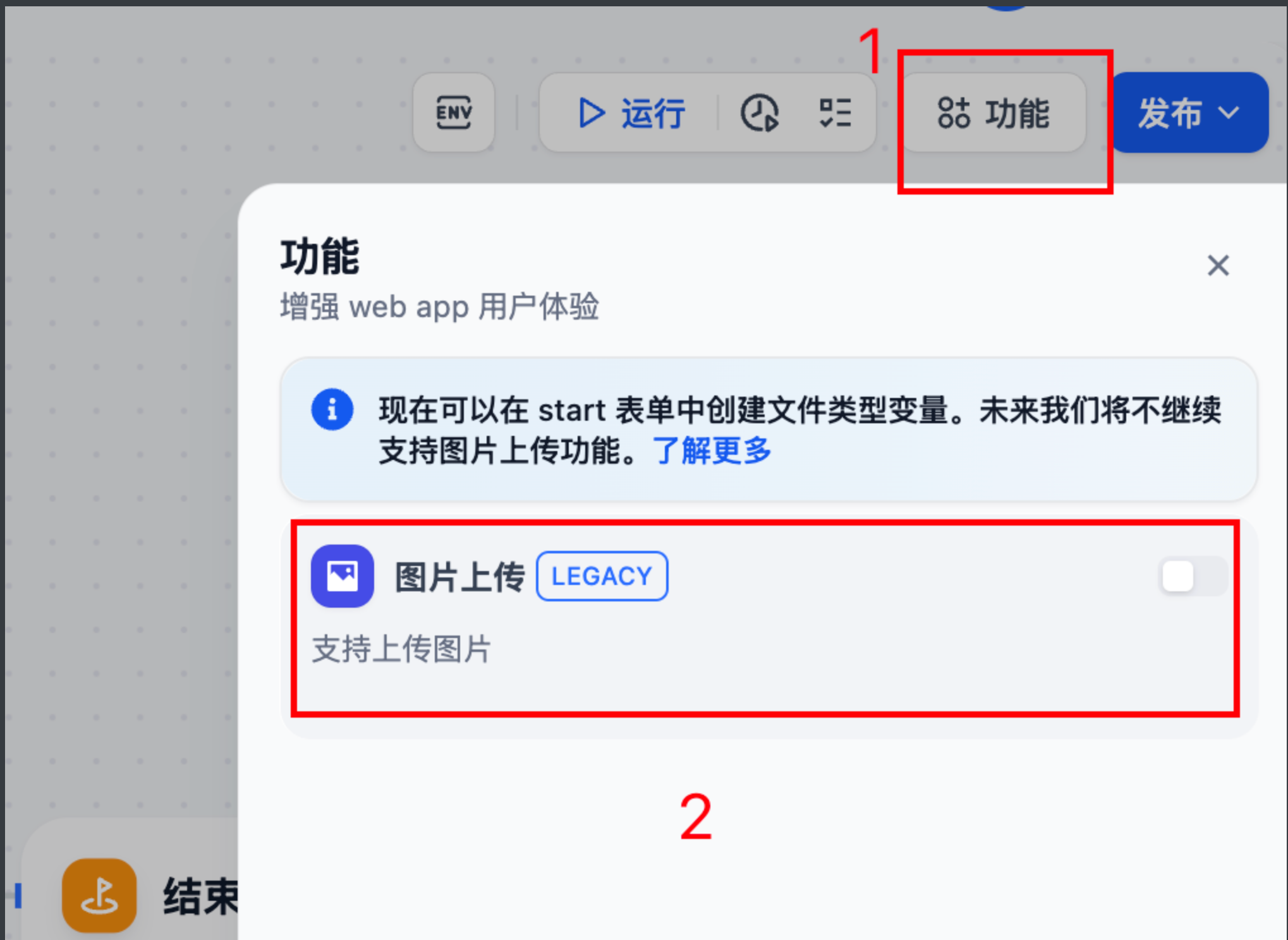
3.6 开启图片上传功能:
3.7 火车票识别智能体运行:
3.8 点击运行,上传火车票:
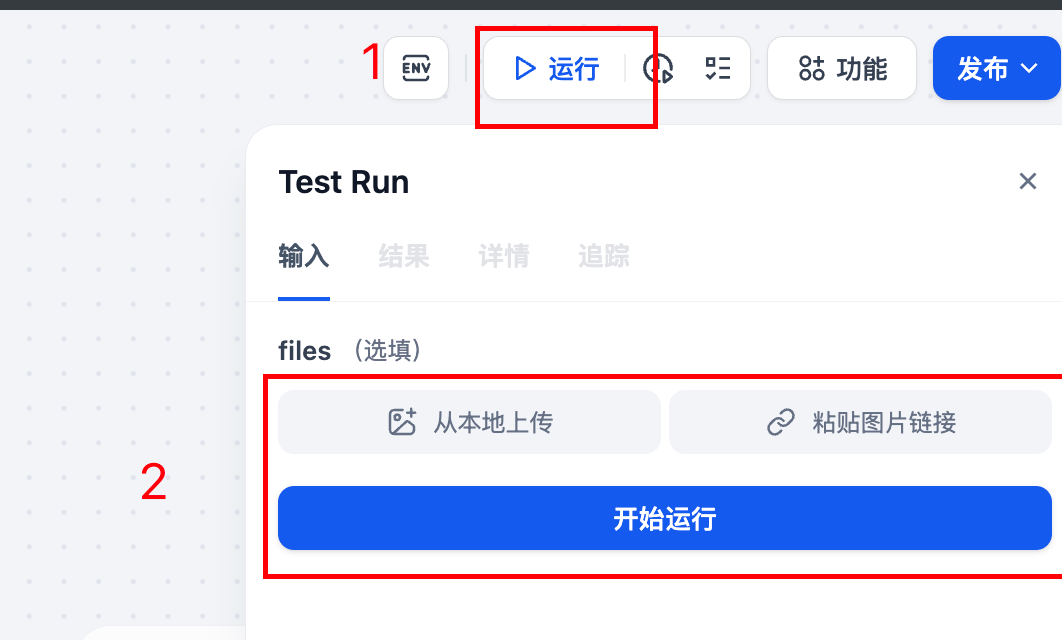
图片支持:本地和网络地址
3.9 点击开始运行,分析结果:

可以看出结果是比较糟糕的,识别的信息错误很大。主要是模型不星。
3.10 更换大模型:
使用:Qwen/Qwen2-VL-72B-Instruct
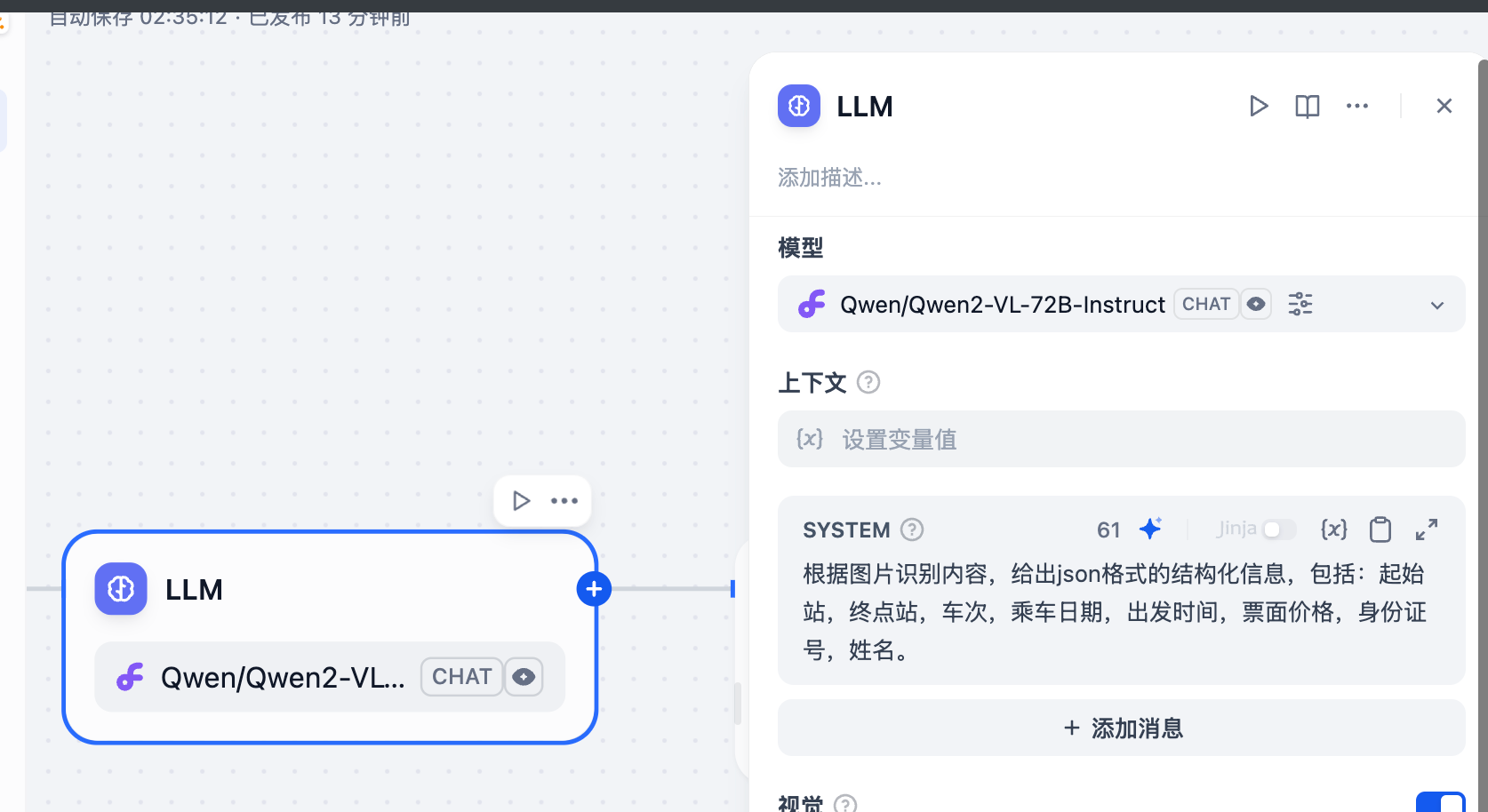
3.11 重新识别,非常完美的结果:

四、创建多类票据识别智能体工作流:
多票据,可以知道,需要先判断是什么票?
遇事不决,交给大模型。
4.1 只需加一个发票类型识别的LLM:
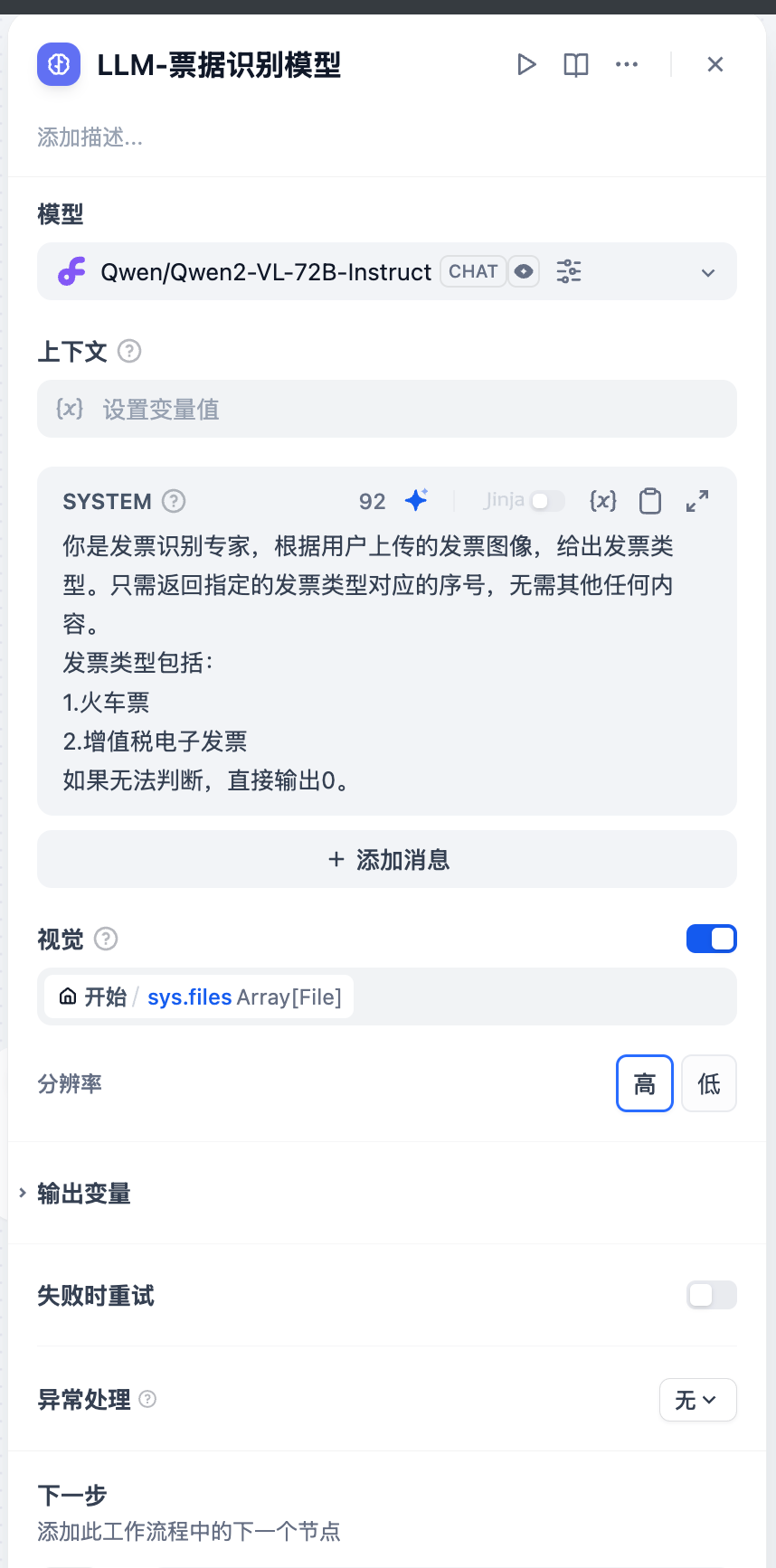
发票和火车票,提示词如下:
你是发票识别专家,根据用户上传的发票图像,给出发票类型。只需返回指定的发票类型对应的序号,无需其他任何内容。
发票类型包括:
1.火车票
2.增值税电子发票
如果无法判断,直接输出0。
如果是火车票,输出 1. 如果是增值税电子发票,输出2.
4.2 添加条件分支:
这个分支的意义是,如果是火车票,走哪个模型;如果是发票,走哪个模型:
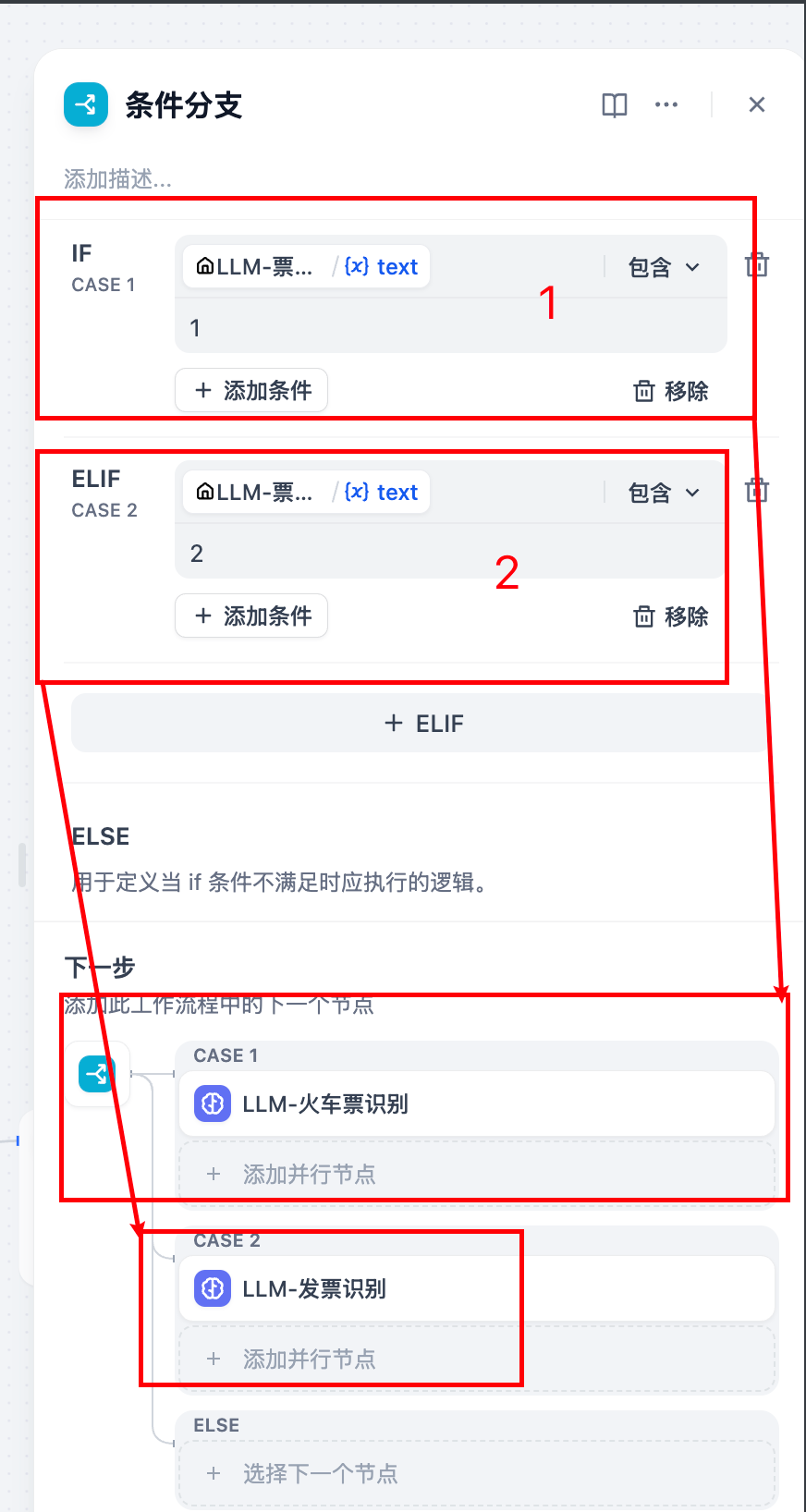
4.3 需要新增一个 LLM发票识别.
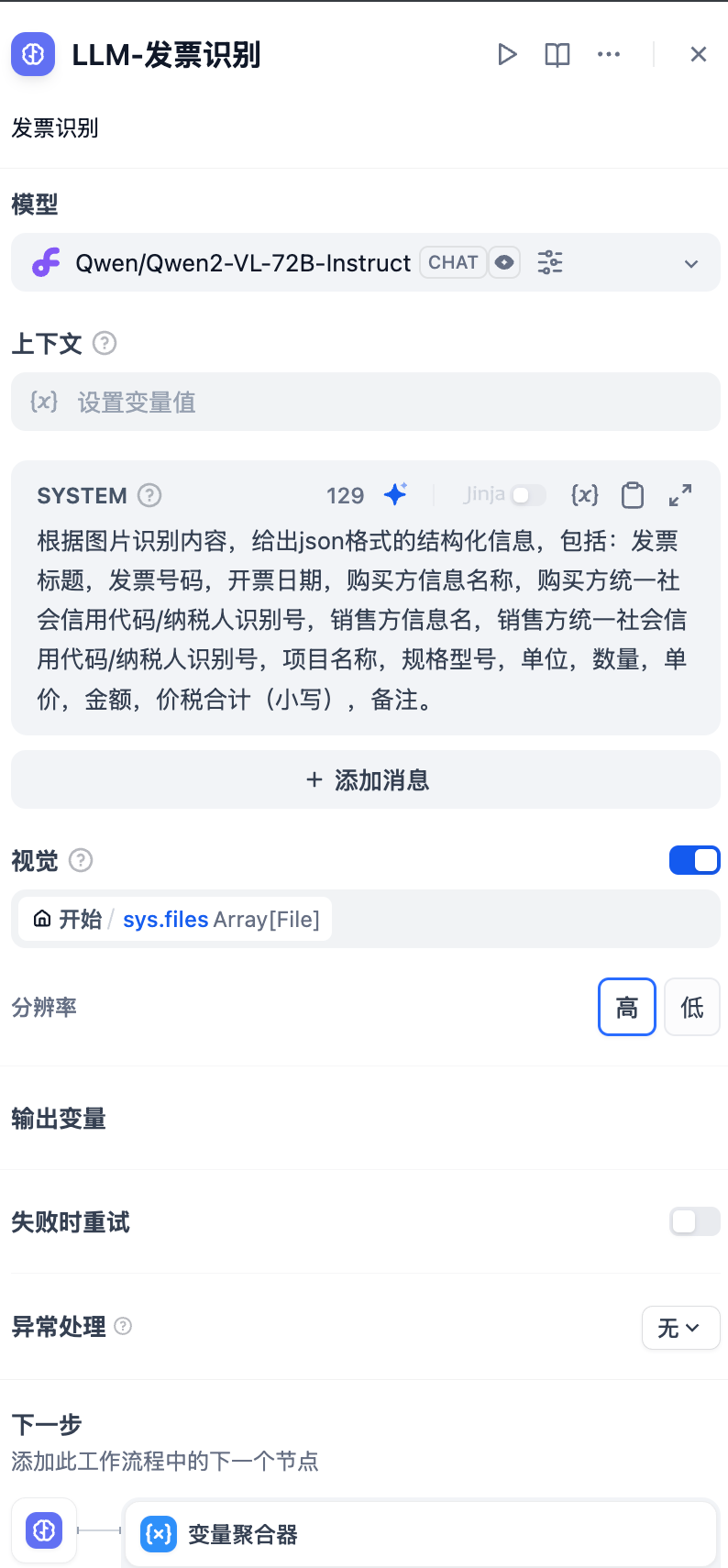
提示词:
根据图片识别内容,给出json格式的结构化信息,包括:发票标题,发票号码,开票日期,购买方信息名称,购买方统一社会信用代码/纳税人识别号,销售方信息名,销售方统一社会信用代码/纳税人识别号,项目名称,规格型号,单位,数量,单价,金额,价税合计(小写),备注。
其实就是,把发票上的信息。描述了一下。
4.4 添加变量聚合器
把不同识别大模型的输出,都统一路由到一个叫变量聚合器的组件中:
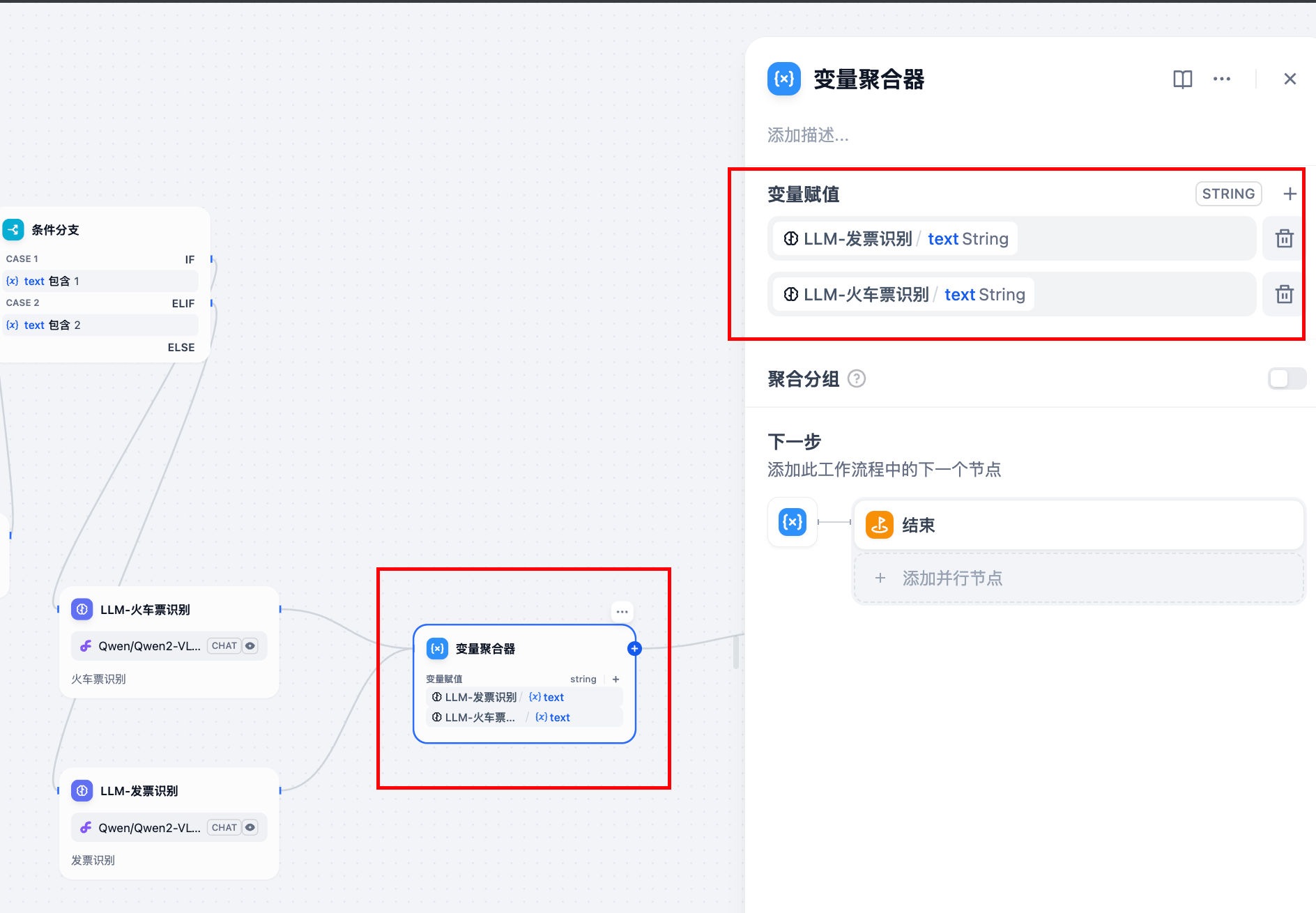
这样的话,就不用给每一个识别模型,都设置结束节点。
4.5 配置结束节点:
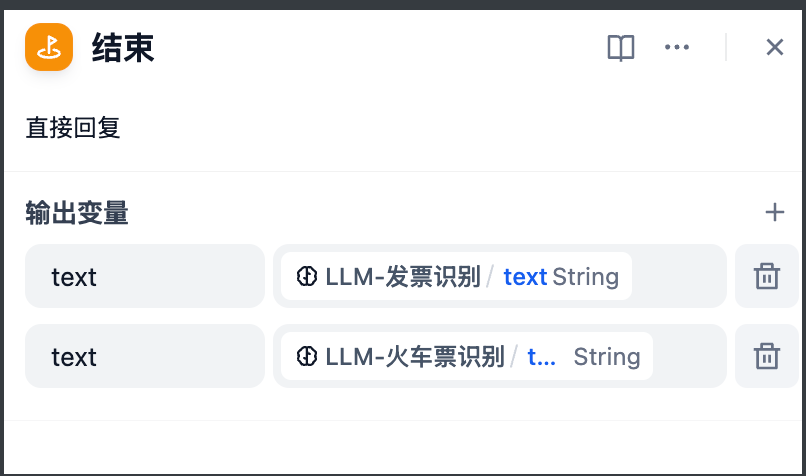
4.6 完整工作流展示:
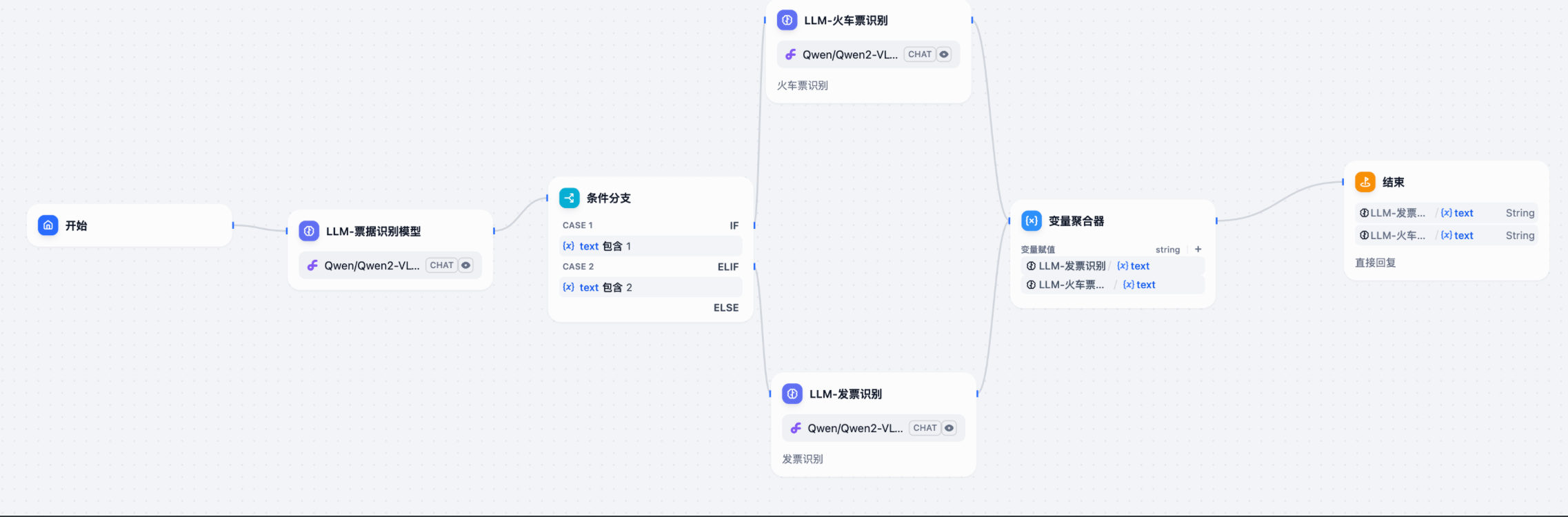
4.7 验证:运行识别火车票,完美实现功能:

从追踪结果看:完全符合我们的判断;
如果识别是火车票,输出 1. 条件判断走: 火车票识别大模型,通过变量聚合器后,输出。
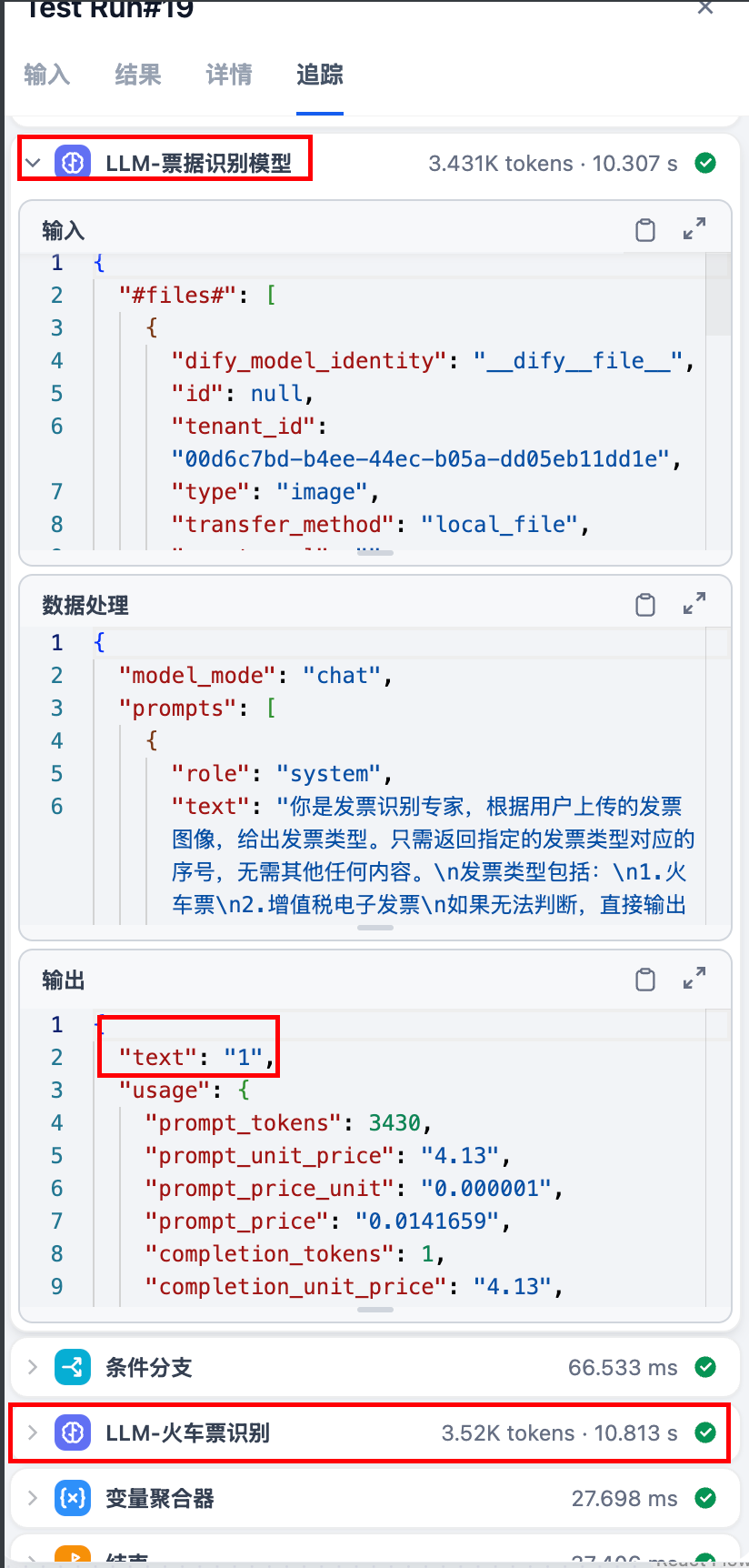
4.8 验证:运行发票识别,完美:

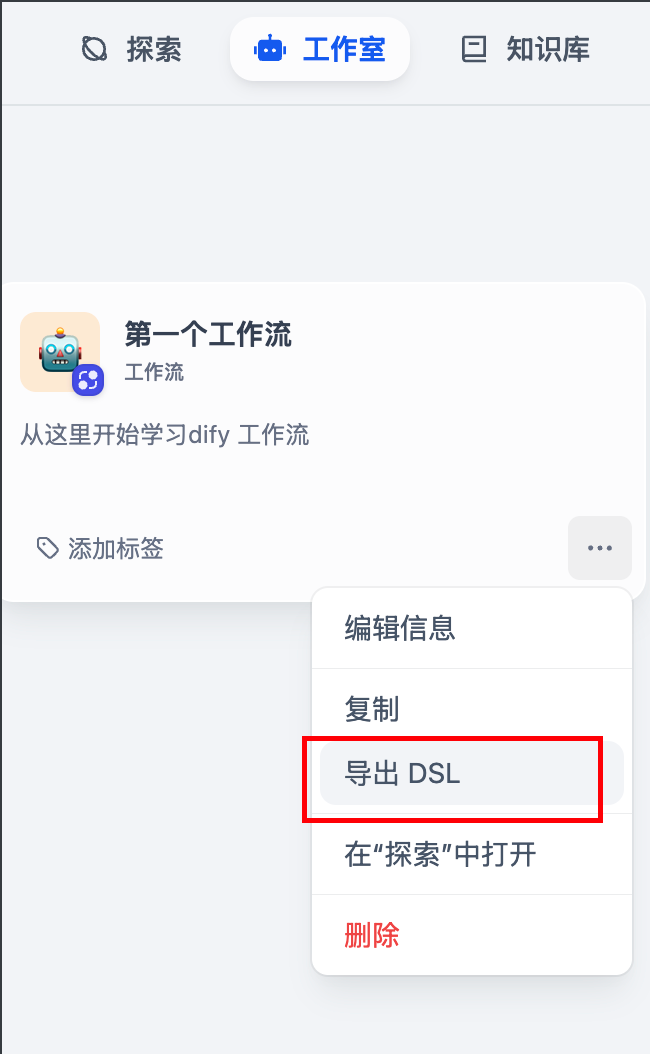
4.9 导出保存DSL:
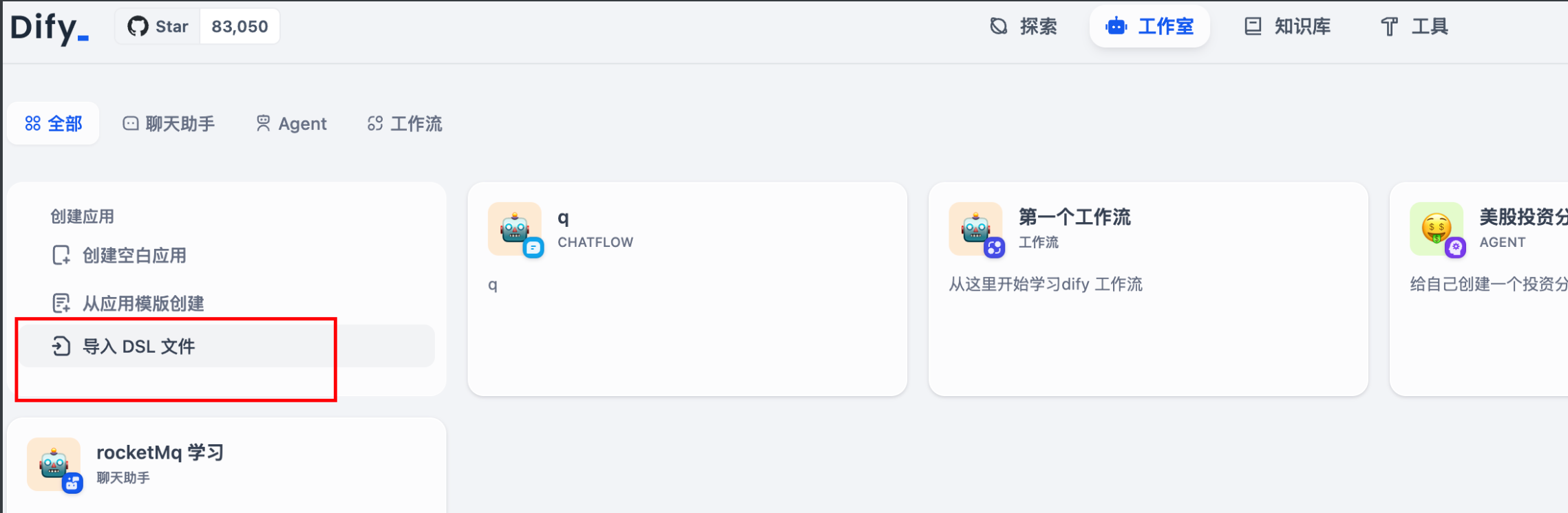
4.10 导入入口:
如果想要使用别人的工作流,这里直接导入即可。
五、备注一下,文中使用的模型都是用的硅基的,获取流程如下:
注册即送 2000 万 Tokens
5.1 注册地址:
https://cloud.siliconflow.cn/i/5WC4oDo4
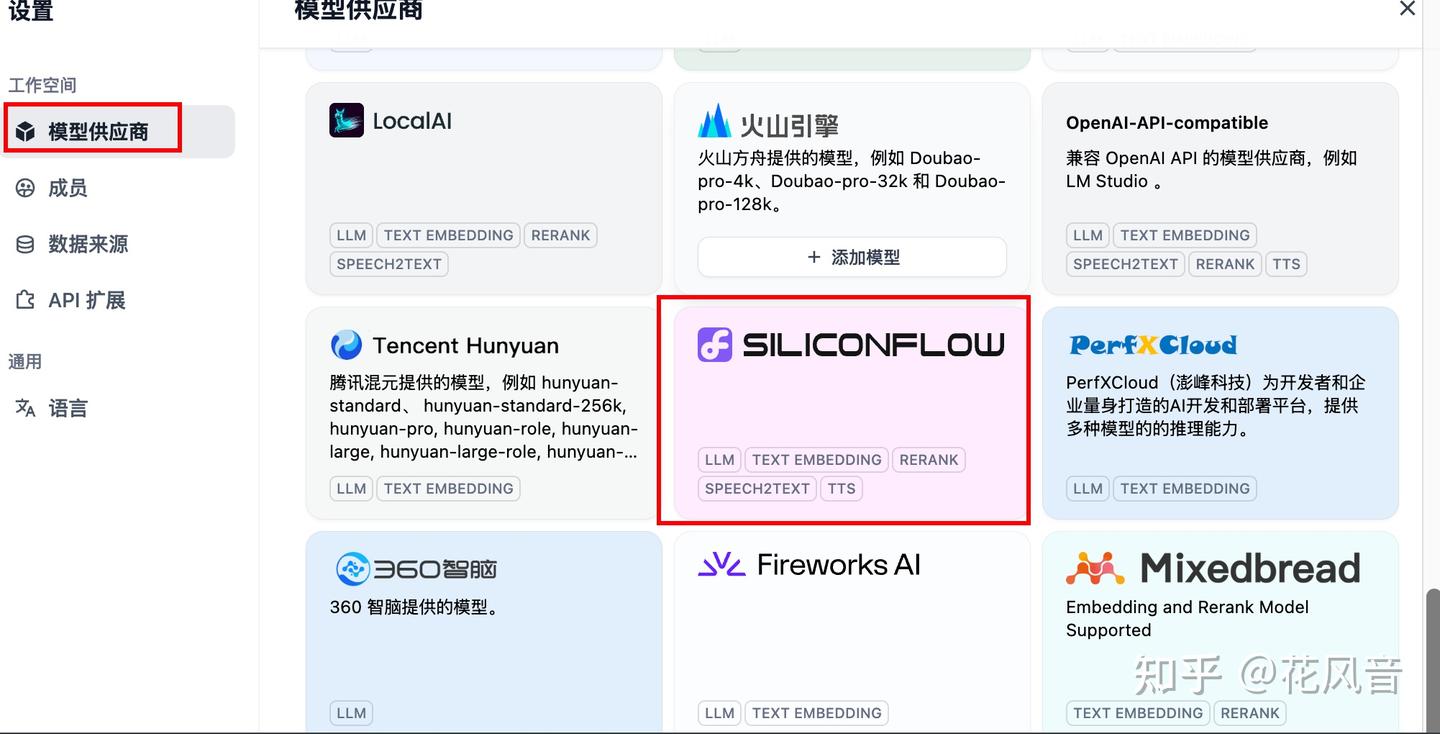
5.2 如何获取 SiliconCloud api-key?
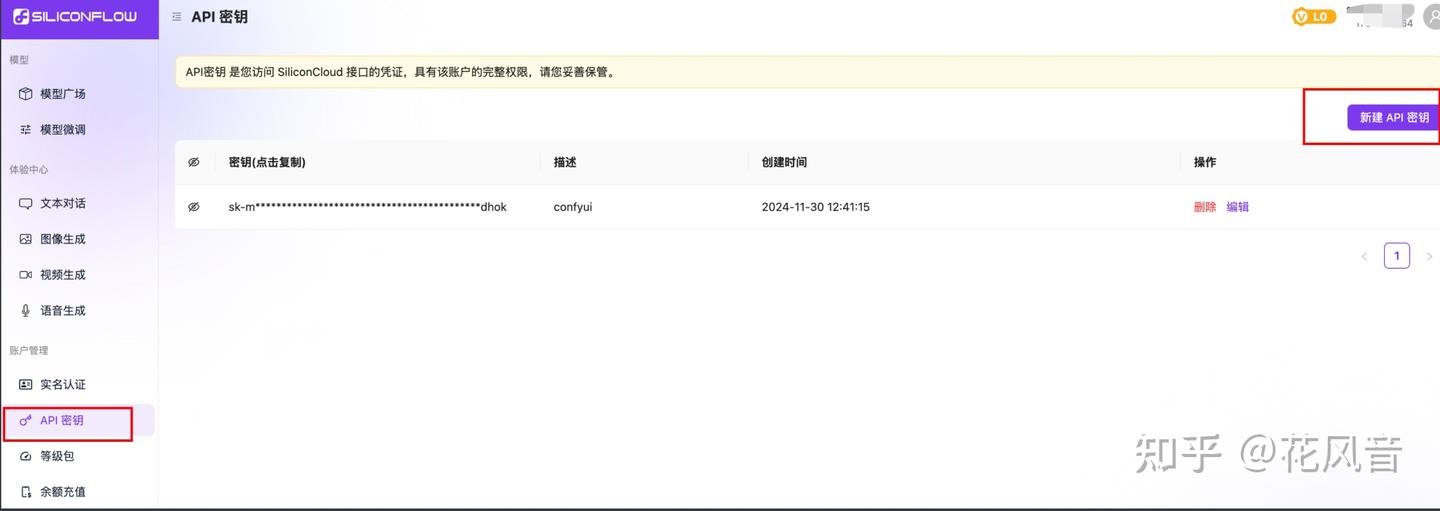
点击注册地址: https://cloud.siliconflow.cn/i/5WC4oDo4。注册后登陆进入以下页面,创建api-key。
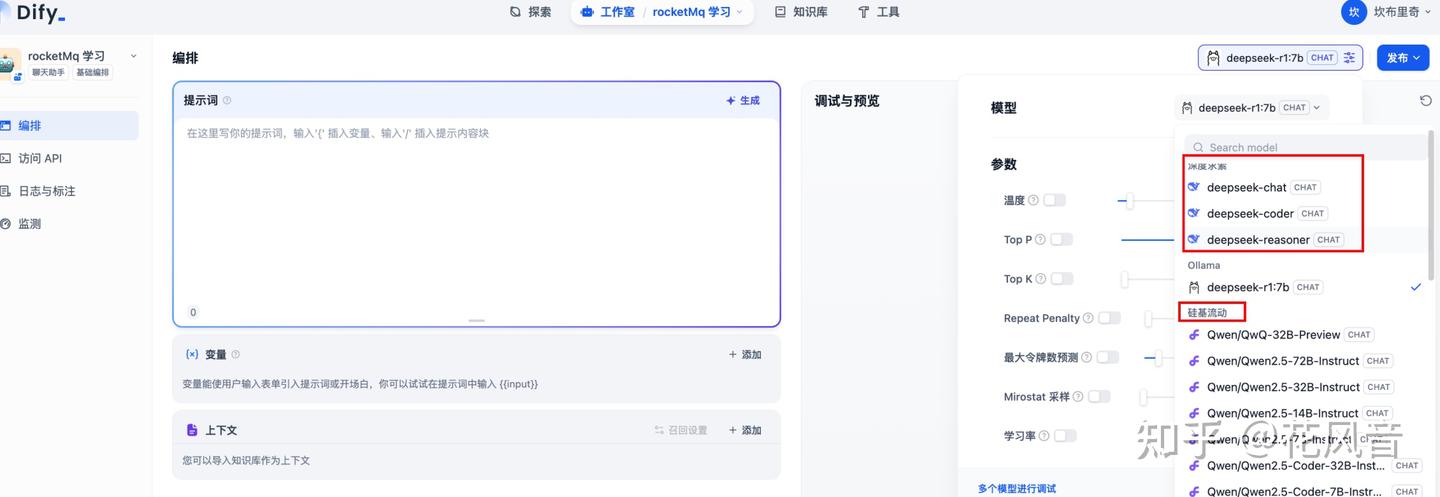
配置后,在聊天助手中就可以使用,可以看到硅基的模型:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









