




序言
虽然是从零开始,但是我也不可能真的从底层数学开始讲。所以,读这篇文章时,默认你知道:
高数
线性代数的矩阵运算
了解MLP
搞定之后就让我们开始吧
宏观架构
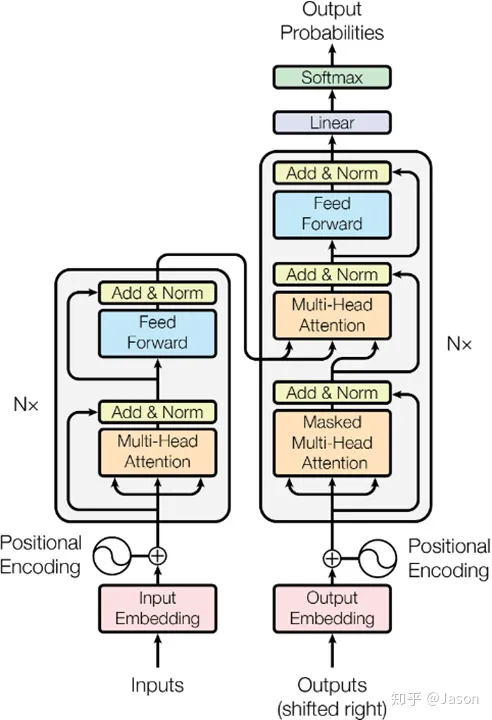
来自官方论文。
这么看你可能还不太懂。那我们一个个来讲讲他的核心概念。
核心概念
输入嵌入(Input Embedding): 首先,源语言的句子经过嵌入层,将每个单词转换成一个向量表示。这个向量包含了该单词的语义和上下文信息。
位置编码(Positional Encoding): Transformer 模型没有像循环神经网络(RNN)那样的显式顺序信息。为了引入序列中单词的位置信息,位置编码被添加到输入嵌入中,以便模型能够理解单词在序列中的相对位置。
自注意力机制(Self-Attention): 这是 Transformer 的关键步骤之一。它允许模型在一个序列中的不同位置关注其他位置的信息,从而捕捉长距离的依赖关系。自注意力机制计算一个权重矩阵,用来对输入序列中的每个单词进行加权组合,以获得更丰富的表示。
多头注意力(Multi-Head Attention): 为了更好地捕捉不同语义信息,Transformer 使用多个并行的自注意力头。每个注意力头关注输入的不同子空间,然后将它们的输出连接在一起,得到更丰富的表征。
残差连接和层归一化(Residual Connectio
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









