






SVM尤其适用于解决二分类问题,基本思想是找到一个能够最大化分类间隔的最佳超平面,将不同类别的样本分开。
超平面:用来将数据分为不同的类别。对于二维数据,超平面就是一条线,而对于高维数据,超平面则是一个超平面。(其实就是分界线)
支持向量:距离分类超平面最近的样本点,简单来说,支持向量是最“边缘”的样本,它们对分类边界有重要的影响。(其实就是最靠近分界线的点,它们对分界线的位置有影响)
最大化间隔:SVM的目标是找到一个超平面,使得支持向量到超平面的距离(即间隔)最大化。最大化间隔可以提高模型的泛化能力,从而提高分类的鲁棒性。(其实就是找到支持向量离分界线越远,效果越好,要不然容易混淆)
线性可分与线性不可分:如果线性可分,SVM可以直接找到一个线性超平面将数据分开;如果线性不可分,SVM会通过核技巧(Kernel Trick)将低维数据映射到高维空间,使其线性可分。
核函数:可以将非线性问题转化为线性问题。
1.线性核(Linear Kernel):用于线性可分的数据
2.多项式核(Polynomial Kernel):用于较为复杂的非线性数据
3.径向基函数核(RBF Kernel,常用高斯核):是最常用的非线性核函数之一,适合复杂的分类任务。
SVM工作过程:
1.输入数据集及标签,选择核函数类型
2.使用训练数据构建模型,找到分类超平面和支持向量
3.在测试数据上验证模型性能,计算分类准确率
例子:
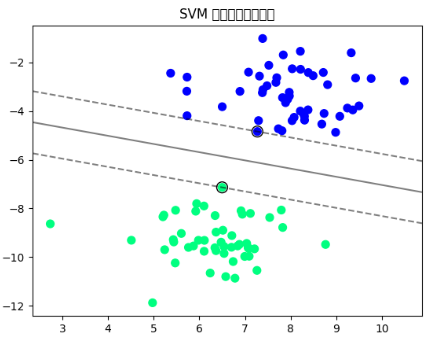
将一个随机分布的蓝绿色点划分出超平面(黑实线),支持向量(黑色圈着的蓝绿色点),黑色虚线代表支持向量边界。

















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









