







word2vec中最大的问题是,随着语料库中处理的词汇量的增加,计算量也随之增加。
对上一章中简单的
word2vec
进行两点改进:引入名为Embedding 层的新层,以及引入名为
Negative Sampling
的新损失函数。
1 word2vec的改进①
假设词汇量有 100 万个,CBOW 模型的中间层神经元有 100 个
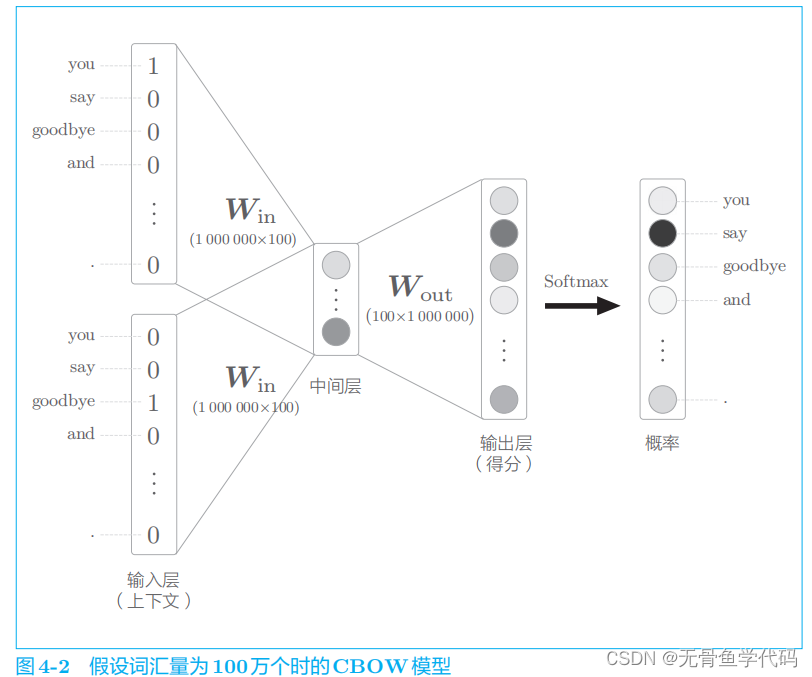
存在问题:



1.1 Embedding层
在上一章的
word2vec
实现中,我们将单词转化为了
one-hot
表示,并将其输入了 MatMul
层,在
MatMul
层中计算了该
one-hot
表示和权重矩阵的乘积。
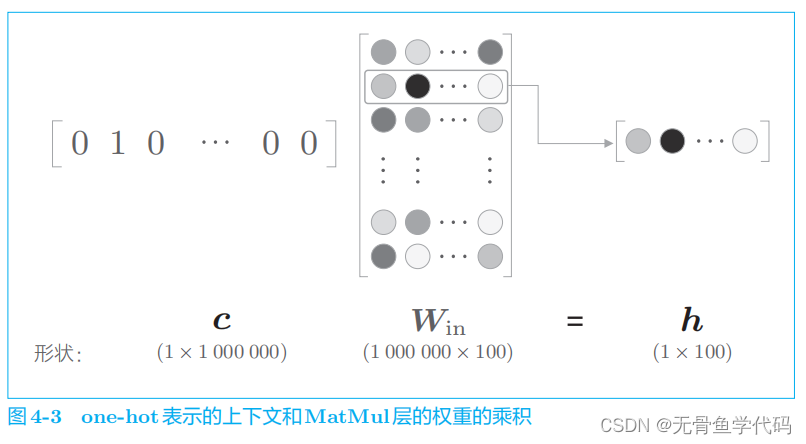
图
4
-
3
中所做的无非是将矩阵的某个特定的行取出来。
现在,我们创建一个从权重参数中抽取“单词
ID
对应行(向量)”的层,这里我们称之为Embedding
层。
1.2 Embedding层的实现
从矩阵中取出某一行的处理是很容易实现的。
例子:


多行里的实现假定用于mini-batch 处理。
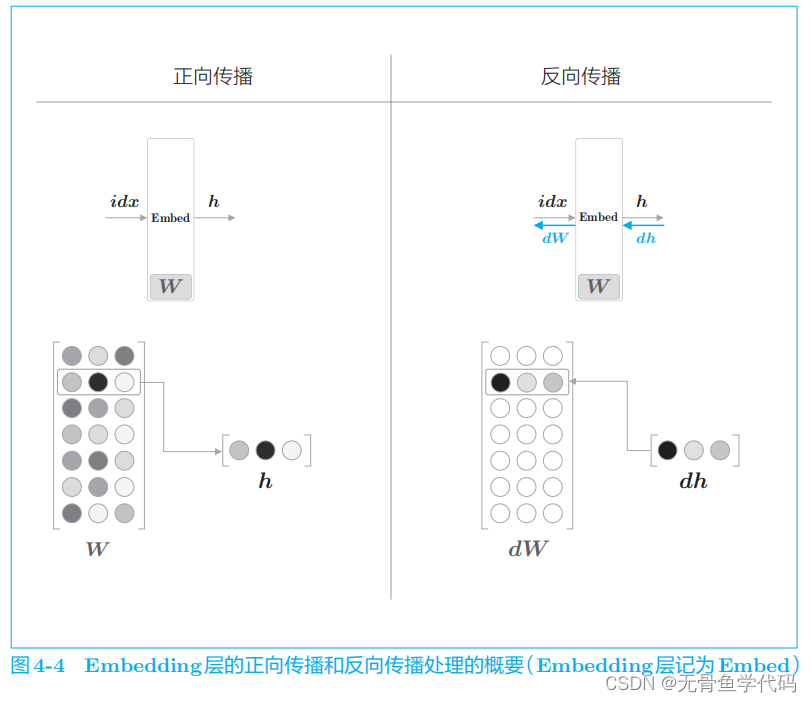
Embedding
层的正向传播只是从权重矩阵 W 中提取特定的行,并将该特定行的神经元原样传给下一层。因此,在反向传播时,从上一层(输出侧的层)传过来的梯度将原样传给下一层(输
入侧的层)。不过,从上一层传来的梯度会被应用到权重梯度
dW
的特定行
(
idx
)

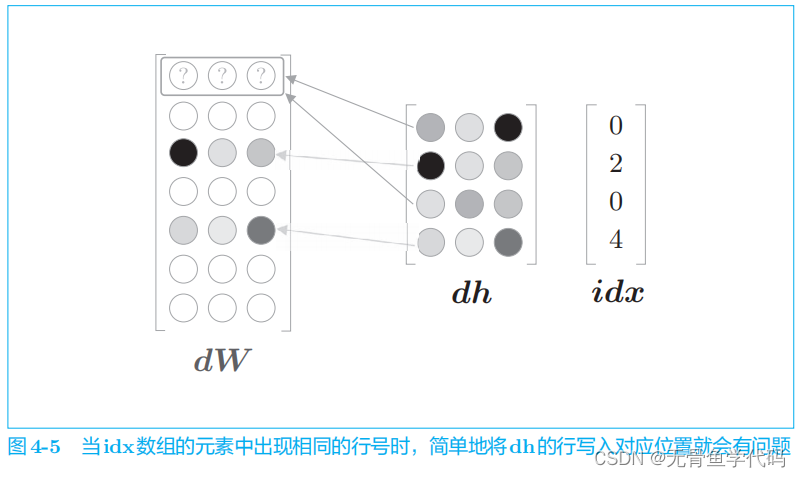
这样处理存在一个问题,这一问题发生在 idx
的元素出现重复时。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9504
9504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









