






 文章介绍了Kafka的核心组件和概念,如消息、批次、主题、分区、生产者和消费者,以及消费者群组和偏移量。接着,详细阐述了如何使用Docker部署Kafka和Zookeeper,包括启动容器、创建测试topic以及发送和接收消息。最后提到了通过Kafka-UI-Lite进行Web管理页面的搭建和使用。
文章介绍了Kafka的核心组件和概念,如消息、批次、主题、分区、生产者和消费者,以及消费者群组和偏移量。接着,详细阐述了如何使用Docker部署Kafka和Zookeeper,包括启动容器、创建测试topic以及发送和接收消息。最后提到了通过Kafka-UI-Lite进行Web管理页面的搭建和使用。
一、kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
消息:Kafka 中的数据单元被称为消息,也被称为记录,可以把它看作数据库表中某一行的记录。
批次:为了提高效率, 消息会分批次写入 Kafka,批次就代指的是一组消息。
主题:消息的种类称为 主题(Topic),可以说一个主题代表了一类消息。相当于是对消息进行分类。主题就像是数据库中的表。
分区:主题可以被分为若干个分区(partition),同一个主题中的分区可以不在一个机器上,有可能会部署在多个机器上,由此来实现 kafka 的伸缩性,单一主题中的分区有序,但是无法保证主题中所有的分区有序
生产者:向主题发布消息的客户端应用程序称为生产者(Producer),生产者用于持续不断的向某个主题发送消息。
消费者:订阅主题消息的客户端程序称为消费者(Consumer),消费者用于处理生产者产生的消息。
消费者群组:生产者与消费者的关系就如同餐厅中的厨师和顾客之间的关系一样,一个厨师对应多个顾客,也就是一个生产者对应多个消费者,消费者群组(Consumer Group)指的就是由一个或多个消费者组成的群体。
偏移量:偏移量(Consumer Offset)是一种元数据,它是一个不断递增的整数值,用来记录消费者发生重平衡时的位置,以便用来恢复数据。
broker:一个独立的 Kafka 服务器就被称为 broker,broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。
broker 集群:broker 是集群 的组成部分,broker 集群由一个或多个 broker 组成,每个集群都有一个 broker 同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。
副本:Kafka 中消息的备份又叫做 副本(Replica),副本的数量是可以配置的,Kafka 定义了两类副本:领导者副本(Leader Replica) 和 追随者副本(Follower Replica),前者对外提供服务,后者只是被动跟随。
重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
二、docker部署kafka
1.拉取镜像
docker pull wurstmeister/zookeeper
docker pull wurstmeister/kafka
#kafka是依赖于zookeeper的,所以也需要安装zookeeper
2.启动zookeeper
docker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper

3.启动kafka
docker run -d --name kafka -p 9093:9093 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=你的服务器IP:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://你的服务器IP:9093 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9093 wurstmeister/kafka

4.进入kafka容器创建测试topic
docker exec -it kafka /bin/sh
cd opt/kafka_2.13-2.8.1
bin/kafka-topics.sh --create --zookeeper 你的服务器IP:2181 --replication-factor 1 --partitions 1 --topic test

5.查看topic状态
在kafka容器中的opt/kafka_2.11-2.0.0/目录下输入
bin/kafka-topics.sh --describe --zookeeper 你的服务器IP:2181 --topic test

6.发送kafka消息
在kafka容器内,/opt/kafka_2.11-2.0.0/bin目录下执行
./kafka-console-producer.sh --broker-list 你服务器的IP:9093 --topic test
>hello

7.接收消息
kafka-console-consumer.sh --bootstrap-server 你服务器的IP:9093 --topic test --from-beginning
>hello

至此kafka消息队列已经搭建完成可以使用
三、搭建kafka的web管理页面
1.docker下载镜像
docker run -d -p 8889:8889 freakchicken/kafka-ui-lite
启动容器后浏览器输入 http://你的服务器IP:8889 访问管理界面
下面是web管理页面的消息生产和消费演示
点击kafka——配置——输入名称和kafka地址
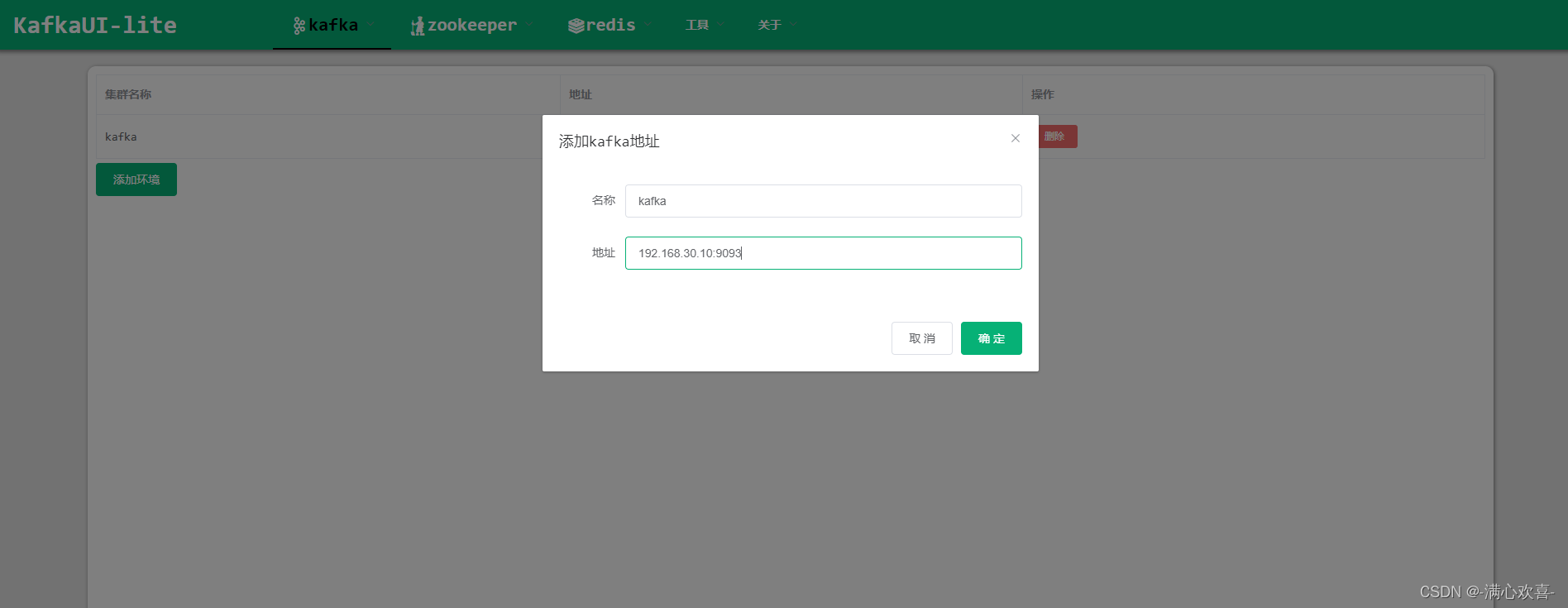
点击kafka——管理——选择kafka查看topic信息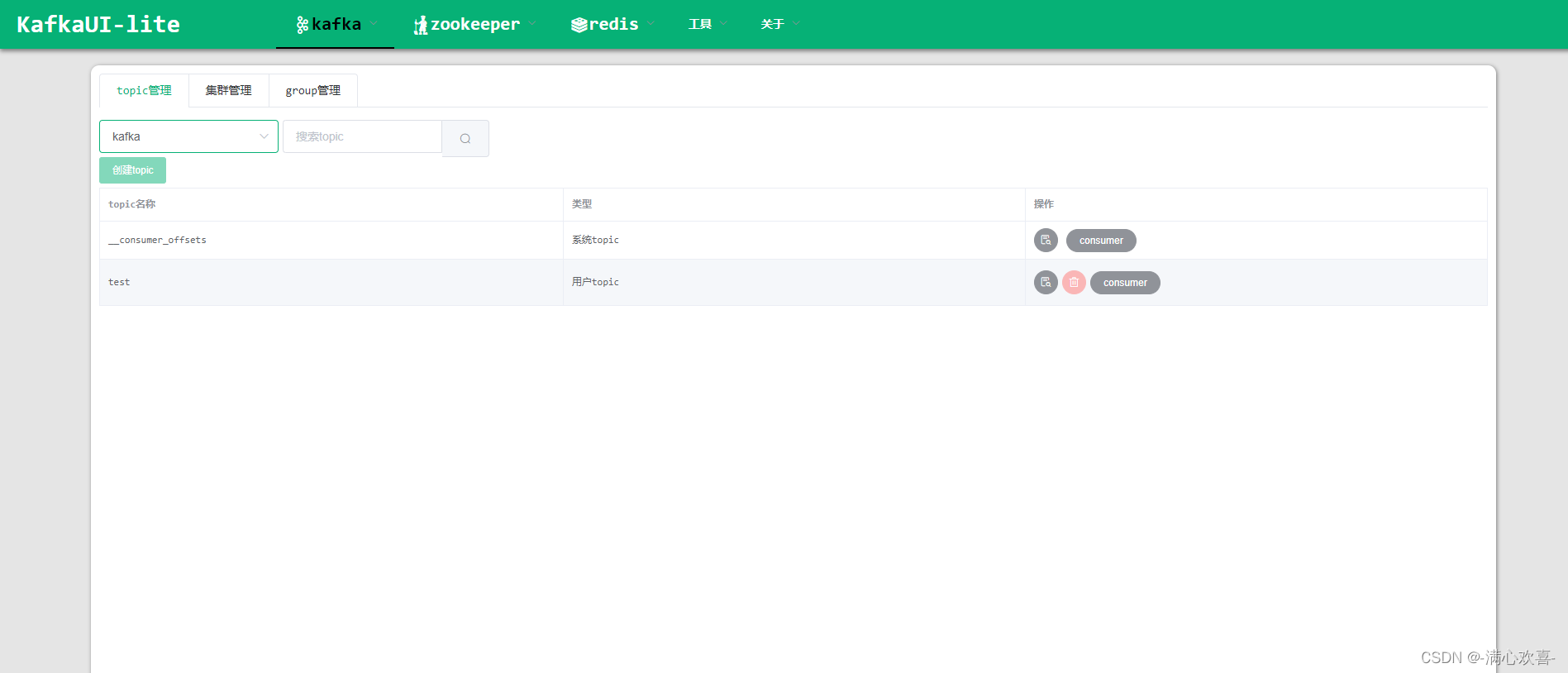 kafka——操作——生产
kafka——操作——生产
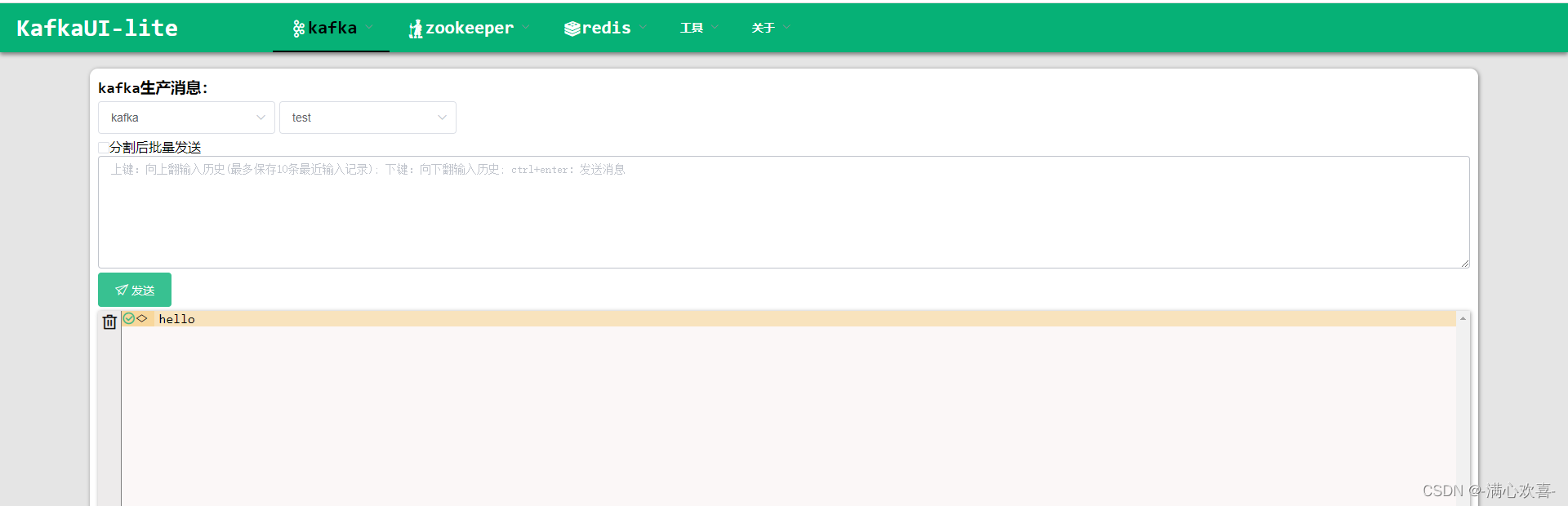
kafka——操作——消费
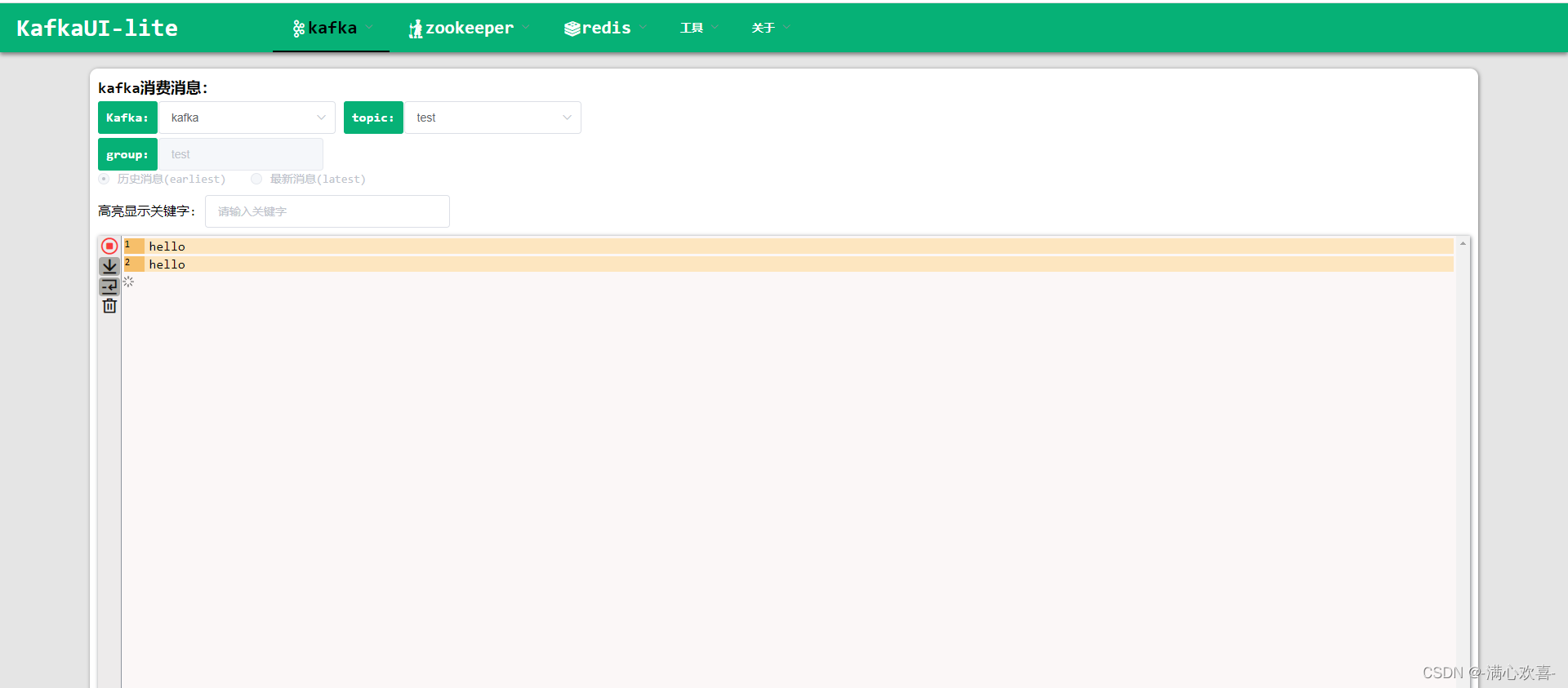


















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











