







上一期”【R语言】——聚类热图行列分组信息注释热图2“介绍了R语言pheatmap包绘制分组信息注释热图,本期主要介绍了另一种分组信息注释方式,通过对数据聚类结果的分析,预设数据聚类簇,从而针对这一数据信息,绘制按聚类结果分组的聚类热图。
1 数据准备
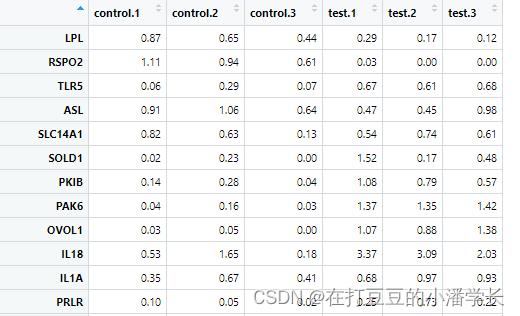
数据输入格式(csv格式):
2 R包加载及数据导入
#下载包#
install.packages("pheatmap")
install.packages("RColorBrewer")
#加载包#
library("pheatmap")
library("RColorBrewer")
#加载绘图数据#
data<-read.table(file='C:/Rdata/jc/pheatmap.csv',header=TRUE,row.names= 1,sep=',')
head(data) #查看数据
#data=log2(data[,1:6]+1) #对基因表达量数据处理
#data <- as.matrix(data) #转变为matrix格式矩阵
#head(data)3 按聚类结果分组的热图
3.1 查看数据的分簇数
在绘制由聚类结果分组的热图前,需估计数据的分簇数,从而为后续分簇数选择提供依据。通常,选择类内平方和降低开始趋于平缓的聚类数作为较优聚类数:
#查看数据的分簇数
data <- t(apply(data, 1, scale))
tested_cluster <- 30 #检验的分簇数
wss <- (nrow(data)-1) * sum(apply(data, 2, var))
for (i in 2:tested_cluster) {
wss[i]  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5556
5556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









