 语音识别ASR技术入门解析
语音识别ASR技术入门解析





理论描述
问题描述
信息来源:https://blog.youkuaiyun.com/weixin_44652758/article/details/136067803
语音识别的目标是:在给定声学信号时,输出最可能的文字序列。
语音识别的任务可以简化为概率问题,进行建模并简化计算:
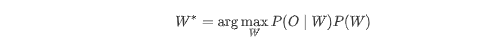
-
W∗ 表示最优文字序列
-
O:观测(如语音特征帧序列)
-
P(W):语言模型概率(文本序列的合理性)
-
P(O∣W):声学模型概率(给定待选文本W,生成当前观测语音O的概率)
在所有可能的文本序列W 中,找到联合概率(声学模型概率 × 语言模型概率)最大的那一个,这个最大值对应的文本就是最优的识别结果。
这样,我们就将不容易估计的概率转变成容易估计的概率。
传统语音识别技术
简述:它使用一个深度学习模型,直接用声音信号和人工标记的文字训练,在推理时听到新的声音信号就能给出它认为最匹配的文字内容。
音频分帧提特征输入声学模型对每帧给出状态/符号概率,借助发音词典与语言模型在搜索图中求最优路径,把帧级概率汇成音素/子词,最终得到词序列。
总结流程:时域波形图 → FFT → 频谱图 → Mel滤波器组 → Fbank特征(频域压缩) → DCT(去相关+能量集中) → MFCC特征(截断+更紧凑) → 特征后处理 -1->1→ WFST 声学模型、发音词典与语言模型组合 → 字符序列。
在 DNN-HMM (神经网络和声学模型)体系下,系统通过大规模标注训练音频,学习“音频帧特征到隐藏状态(如音素或捆绑状态)标签”的映射。实际识别时,对新输入音频做特征提取,然后用 DNN(神经网络) 给出每帧属于各状态的概率,结合 HMM(声学模型) 的状态转移规律,采用解码算法(如 Viterbi),遍历所有可能状态序列,最终选出概率最大的路径,对应为识别结果文本。
现代端到端 Transformer 模型(如基于 CTC、Attention 或 Transducer)将声学模型与语言模型统一到同一网络中,直接学习从音频序列到文本序列的映射,不再显式使用 HMM 状态转移或 Viterbi 解码. 其核心目标依然是将语音转换为最优文本。
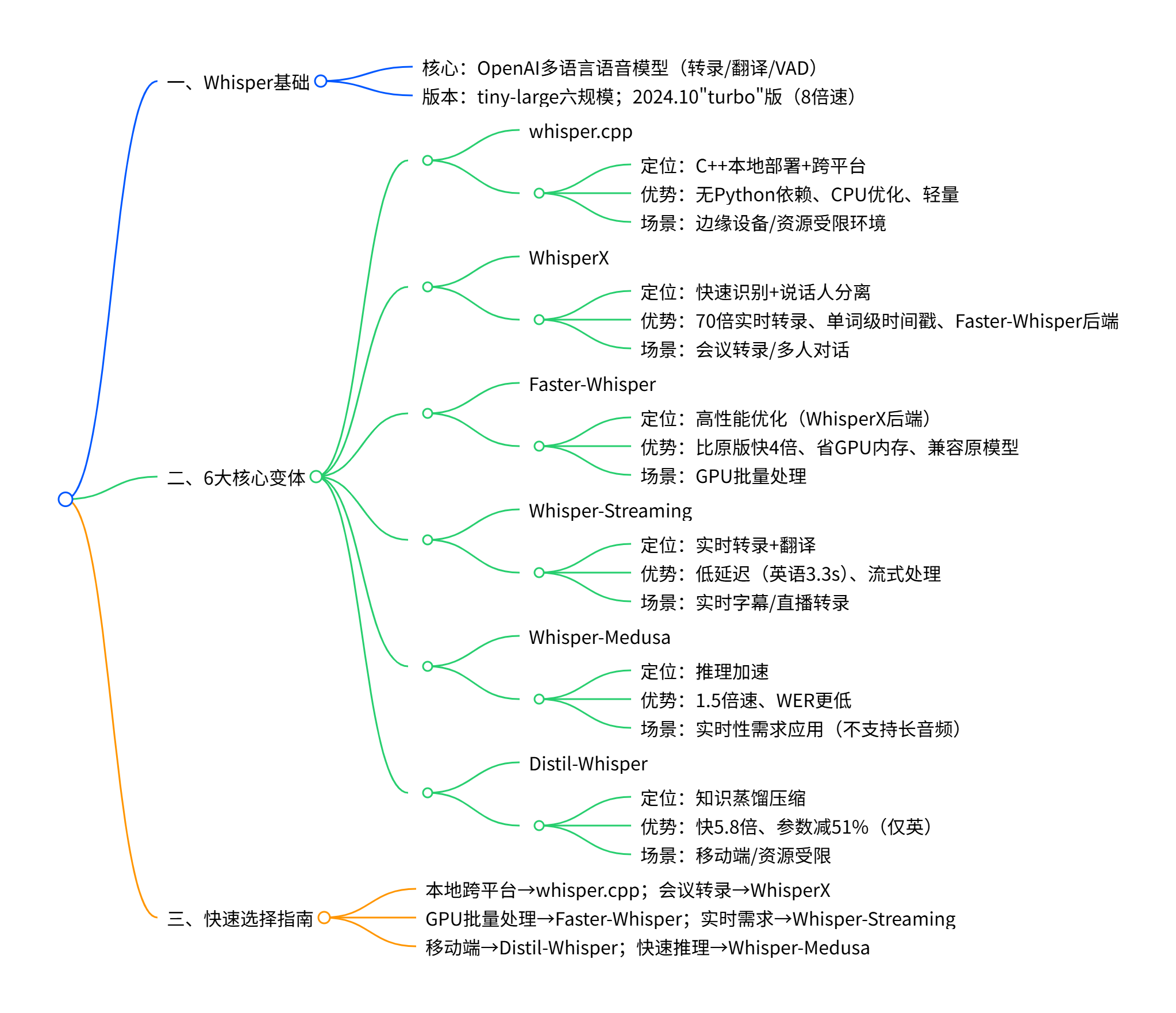
开源项目
Whisper
Whisper 是 OpenAI 开源的端到端多语言语音识别与翻译模型,基于Transformer架构,强调在口音、噪声与术语下的稳健性与多语种适配能力。 模型以约68万小时多任务、多语言的监督数据训练,支持跨语言转录以及将多种语言直接翻译为英文的任务模式。
基于whisper模型基础开发的项目
其中主要测试实验过的有whisper.cpp和whisper-streaming。
whisper.cpp主要用本地wav音频数据,对不同类型模型转录质量评估(纯感觉评估)和CPU优化程度。以及自动翻译英文功能和项目参数调优的测试。项目提供了实时流demo,主要是做了输入音频分帧缓存模型输入。
结论:1550M模型参数,具备常规项目的ASR质量能力。缺点是测试环境机器没有GPU加速,CPU推理速度优化不足以达到实时需求。支持模型架构的调优策略,支持束缚和贪心两种策略(ffmpeg 8月底以过滤器方式,加入whisper只支持GPU基础选项,不支持模型架构策略设置)。
whisper-streaming主要是解决实时流场景,是否满足实时流转录需求。结论是要求转录质量,无GPU加持。无法满足实时响应需求。
模型列表
量化模型是减少主模型精度从而带来推理速度提升。比如从基础数据类型从8字节减少4字节,在有限的内存总量实现读取更多的数据,加快推理速度。
英文场景常用准确率指标是WER(Word Error Rate,词错率),按照“词”为单位。
| 模型名称 | 参数量 | WER | 量化 | 推理速度 | 备注 |
|---|---|---|---|---|---|
| ggml-tiny.bin | 39M | ~10-15% | 无 | 最快 | 最小模型,适合资源受限设备 |
| ggml-base.bin | 74M | ~8-12% | 无 | 快 | 速度与精度平衡的入门选择 |
| ggml-small.bin | 244M | ~6-9% | 无 | 中等 | 日常转录的良好选择 |
| ggml-large-v2.bin | 1550M | ~4-6% | 无 | 慢 | 高精度多语言模型 |
| ggml-large-v3.bin | 1550M | ~3.3-5% | 无 | 慢 | 最新大模型,精度最高 |
| ggml-large-v2-q5_0.bin | 1550M | ~4.5-6.5% | Q5_0量化 | 中等偏快 | 文件大小减少62%,精度轻微下降 |
| ggml-large-v3-q5_0.bin | 1550M | ~3.8-5.5% | Q5_0量化 | 中等偏快 | V3版本量化,最佳量化精度 |
| ggml-large-v3-turbo.bin | 1550M | ~4-6% | 优化架构 | 快 | 解码层从32减至4层,8倍速度提升 |
OpenAI官方并没有明确给出具体的中文CER数据。
中文场景主流准确率指标为CER(Character Error Rate,字错率或字符错率),直接用“字”作为最小单位。
表格数据来源于第三方开发者的评估结果,并非OpenAI官方数据。
| 模型 | AISHELL-1 Test | WenetSpeech Net | WenetSpeech Meeting |
|---|---|---|---|
| ggml-large-v2.bin | 8.817% | 12.332% | 26.547% |
| ggml-large-v3.bin | 8.086% | 11.452% | 19.878% |
| ggml-large-v3-turbo.bin | 8.639% | 13.507% | 20.313% |
基于whisper.cpp项目本地测试音频信息:
-
采样数:664277
-
时长:41.52 秒
-
采样率:16000 Hz
基于上述信息,测试图表:
| 模型名称 | 文件大小(MB) | 模型类型 | 特点 | 转录时长 |
|---|---|---|---|---|
| ggml-tiny.bin | 74.1 | 最小模型 | 超轻量级,适合边缘设备 | 9s |
| ggml-base.bin | 141.1 | 基础模型 | 平衡性能与资源消耗 | 19s |
| ggml-small.bin | 465.0 | 小型模型 | 中等精度,适合一般应用 | 33s |
| ggml-large-v2-q5_0.bin | 1030.7 | 量化大型v2 | 65%压缩率,性能损失minimal | 181s |
| ggml-large-v3-q5_0.bin | 1031.1 | 量化大型v3 | 65%压缩率,最新版本优化 | 215s |
| ggml-large-v3-turbo.bin | 1549.3 | 大型v3加速版 | 速度优化版本 | 74s |
| ggml-large-v2.bin | 2951.3 | 完整大型v2 | 高精度,完整参数 | 244s |
| ggml-large-v3.bin | 2951.7 | 完整大型v3 | 最高精度,最新版本 | 239s |
whisper-streaming
声明:由于实验whisper-streaming 项目时选择base级别模型,已经造成机器超负荷且响应慢。在没有硬件条件,寻找一些相对于可靠数据用于主观判断,作为ASR后期模型更换的理论基础。数据来源:Whisper 实时转录系统
问题描述:尽管OpenAI的Whisper模型在多语言语音识别和翻译任务中表现出色,但它原本并未设计用于实时转录应用 。传统的Whisper实现只能进行离线处理,需要完整的音频文件才能开始工作,这在实时场景(如现场字幕、会议转录)中存在明显局限性。whisper-streaming解决了这个技术问题。
实际需求:在实时字幕、会议记录等场景中,需要在语音产生的同时进行处理,并在短时间内(如2秒)输出转录结果。现有的Whisper流式实现方法较为简单粗暴(如先录制30秒音频段再处理),导致延迟大、分段边界质量差的问题。
核心创新:Whisper-Streaming 采用 LocalAgreement 策略结合自适应延迟来实现流式转录。该方法解决了传统实现中简单分段导致的高延迟和边界质量差的问题。
LocalAgreement 策略:系统使用 LocalAgreement-2 策略(使用2个连续源块的局部一致性策略),通过寻找连续两次更新中的最长公共前缀来确定稳定的转录内容。这种方法能够:
-
识别已确认的输出内容
-
处理模型输出的不确定性
-
保持转录的连贯性
举例:两次ASR结果"Brejc"和"Brake"不一致(AI当前最优特点),系统会等待下次更新来确认正确的名字。

示例图:处理三个连续更新的示意图。
-
黄色突出显示的文本是“提示词”,即要遵循的先前上下文。
-
黑边矩形是一个音频缓冲区,里面的文本是 Whisper 从该声音片段生成的转录。
-
蓝色垂直线是一个时间戳,它将缓冲区分成两部分,左边是先前确认的,右边是未确认的。LocalAgreement-2策略或搜索最长的公共前缀在两次后续更新中应用于未确认(右侧)部分。
-
最长的公共前缀以绿色突出显示,绿色下划线突出显示新确认的输出,而绿色虚线下划线表示之前和随后确认的输出。
-
灰色下划线表示已确认部分中被忽略的更新。
(非论文观点)LocalAgreement策略本质上是一个输出后处理算法,它并不依赖于特定的模型架构。可考虑后续QNAAIS模块增加这一机制。
whisper-streaming 系统架构特点 :
-
音频缓冲区管理:维持最多30秒的音频缓冲区,始终从完整句子开头开始处理。
-
更新循环:通过MinChunkSize参数控制语音块,实现延迟和质量平衡。
-
确认部分跳过:避免重复处理已确认的转录内容。
-
句间上下文连接:使用前200个单词作为"提示"参数保持文档一致性。
-
语音活动检测(VAD):可选的噪声过滤机制。
测试实验数据
论文基于NVIDIA A40 GPU的性能,在欧洲议会语音数据集上的评估结果显示关键性能指标表现:
| 语言 | 平均延迟 | WER(词错率) | 相比离线模式 |
|---|---|---|---|
| 英语 | 3.3秒 | 8.1% | +2% |
| 德语 | 4.4秒 | 9.4% | +2% |
| 捷克语 | 4.8秒 | 12.9% | +6% |
VAD (Voice Activity Detection) - 语音活动检测影响分析:
-
对于流畅的原始英语演讲,关闭VAD可降低延迟0.23-0.41秒且质量相当
-
对于含有停顿的同声传译,开启VAD可显著提升质量2-3% WER
应用风险:
-
技术交流群反应存在因中美关系,甲方拒绝使用外部技术,防止后期维护带来的问题。
-
入门硬件要求高,要求配置NVIDIA A40 GPU(1w美金)。
-
部分企业基于qwen3+whisper打造智能语音客服,硬件提供4090*2总96G显存。
总结:目前机器硬件条件限制,无法基于whisper的研发工作。针对于硬件条件和ASR转录质量标准,我们选择Paraformer-zh-streaming,它能够满足我们本地部署使用CPU资源进行实时转录工程。
参考文献
https://blog.youkuaiyun.com/weixin_44652758/article/details/136067803
学习社区
https://github.com/0voice

















 1422
1422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









