 准确率与召回率详解
准确率与召回率详解




入门阶段大纲
本文通过AI对话方法,进行学习,介意勿扰。主要核心是通过聊天记录的模式,学习到基础知识。不知直觉的入门。
| 提示词 |
|---|
| 人工智能定义 |
| 机器学习 vs 深度学习 |
| 监督 / 无监督 / 强化学习 |
| 训练集 / 验证集 / 测试集 |
| 过拟合 / 欠拟合 |
| 特征工程 |
| 损失函数 |
| 梯度下降 |
| 准确率 / 召回率 / F1 分数 |
| 混淆矩阵 |
备注:准确率 / 召回率 / F1 分数 因存在混淆矩阵,不通过聊天方法引导阅读,因为逻辑太绕了!
参考文献
一文看懂分类模型的评估指标:准确率、精准率、召回率、F1 - 知乎
机器学习中的混淆矩阵,准确率,精确率,召回率,F1分数,roc曲线以及发生比_混淆矩阵精确率和召回率-优快云博客
引入
在机器学习中,构建分类模型后,如何客观衡量其性能并比较不同模型的优劣?
量化评估指标就是“尺子”,帮助我们从整体正确率到正负类区分能力进行全面检验,尤其在二分类任务(如垃圾邮件检测或疾病诊断)中,这些指标基于混淆矩阵(Confusion Matrix)计算,避免主观判断。后续计算方法就是解决客观衡量其性能并比较不同模型的优劣。
基础概念
-
混淆矩阵:TP(真阳)、FP(假阳)、TN(真阴)、FN(假阴)。
-
记住第一个是是否正确”能帮你快速对号入座,“第二个字母是预测结果。
-

-
-
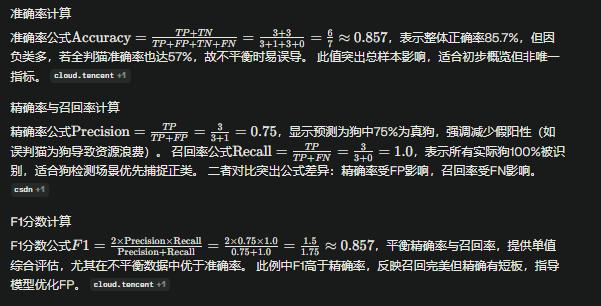
准确率 Accuracy:Acc = (TP + TN) / (TP + FP + TN + FN)。
-
精确率 Precision:P = TP / (TP + FP),关注“预测为正”里有多少是真的。
-
召回率 Recall(灵敏度):R = TP / (TP + FN),关注“实际为正”被找出多少。
-
F1 分数:F1 = 2PR / (P + R),是精确率与召回率的调和平均,对不平衡数据更稳健于仅看准确率。
-
PR曲线、AUC-PR 略,暂时不投入时间研究。
直接结论
-
四大指标的核心关系:准确率看整体正确比例;精确率看“判为正”的可靠性;召回率看“把正找全”的能力;F1用调和平均在精确率与召回率间求平衡。
-
何时用谁:样本均衡与泛看效果可先看准确率;重视误报少用精确率;重视漏报少用召回率;想综合平衡用F1,类别不平衡时优先考虑F1/PR曲线而非仅用准确率。
阈值与权衡选择
二分类常通过阈值调节 P-R:阈值升高,通常精确率↑、召回率↓;阈值降低,召回率↑、精确率↓。
具体业务按代价选择:(相关度高则假阴召回率 低则假阳精确率)
-
假阴代价更高(漏诊、漏检):优先召回率。
-
假阳代价更高(误封、误警):优先精确率。
-
两者都重要且不均衡数据:关注F1、PR曲线,而非单看准确率。
与数据不平衡
-
极端不平衡时,准确率可能“虚高”(全判负也很高),需看精确率、召回率、F1,或使用PR曲线、AUC-PR 等。
猫狗图像分类示例
假设一个二分类模型用于区分猫狗图像,测试集有7张图片:实际3张狗(正类)和4张猫(负类),模型预测结果为TP=3(实际狗预测狗)、FN=0(无漏判狗)、FP=1(1张猫误判狗)、TN=3(3张猫正确判猫)。 混淆矩阵以行实际类别(狗/猫)、列预测类别(狗/猫)表示:
| 实际\预测 | 狗 | 猫 |
|---|---|---|
| 狗 | 3 (TP) | 0 (FN) |
| 猫 | 1 (FP) | 3 (TN) |
ROC 与 AUC 要点
-
轴含义:横轴 FPR,纵轴 TPR;通过遍历阈值得到整条曲线。
-
判优直觉:在同一 FPR 下 TPR 越高越好;曲线越“陡峭”越优。
-
AUC 解释:曲线下面积,取值常见于 0.5 到 1;0.5 近似随机猜测,越接近 1 越好;也可理解为随机抽取一对正负样本时,模型把正样本排在负样本前的概率。
Precision-Recall 与阈值权衡
-
提高阈值通常提升 Precision、下降 Recall;降低阈值相反,因此应结合业务代价选择阈值。
-
假阴代价高(漏诊、漏检)时重召回;假阳代价高(误封、误警)时重精确;权衡困难时用 F1 或给出全阈值曲线供选择。

















 1141
1141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









