




Paraformer-zh-streaming
信息来源:从Paraformer语音识别到SenseVoice音频理解
Paraformer-zh-streaming是阿里巴巴达摩院开发的中文流式语音识别模型 ,作为FunASR工具包的旗舰模型,专门针对实时语音处理场景进行优化。该模型基于创新的非自回归并行Transformer架构,实现了精度与效率的完美平衡。该模型使用约 6w(whisper的1/10) 小时英语标注语音进行训练,参数量约为 220 M,覆盖多样化发音、口音和噪声场景,以提升跨域适应性.
核心优势:
-
准确率: 非自回归设计(NAR),在学术集合上准确率与Transformer自回归模型相当。
-
解码速度:解码速度比自回归Transformer快10倍以上(RTF指标)。
-
RTF(实时因子) 是衡量语音识别系统处理速度的核心指标。Paraformer RTF = 0.009,处理10秒音频仅需0.09秒。
-
-
开源效果: Modelscope开源的Paraformer-large是中文开源模型中效果最好的之一。
-
应用情况: 已全面上线应用于阿里巴巴内部各产品线,以及后续FunClip开源项目。
-
典型应用案例:天猫精灵、小米音箱、Siri语音助手。(不严格要求准确)
技术角度
传统方法:将语音特征转换为帧级别音素序列,需标注帧与音素对齐。通过WFST解码器优化音素序列为合理文本。缺点是依赖精细对齐和模块化流程,导致训练繁琐。端到端语音识别方法解决。
传统流程:声学模型 → 语言模型 → 解码器 ↓ 问题:需要精细帧-音素对齐 + 模块化训练 → 训练繁琐
端到端语音识别定义:通过单一神经网络完成传统多步骤级联的语音识别任务。其中解决语音帧数(变长输入)与文字序列(变长输出)的不等长映射问题。
核心挑战:变长输入(语音帧)→ 变长输出(文字序列) 解决方案:单一神经网络完成整个识别任务
主要有2种方法:
-
CTC原理:生成与输入帧数相等的预测序列,用blank标签占位后删除空标签得到文字序列。
-
# CTC方式(硬对齐): CTC_输出 = ["你", "blank", "你", "好", "blank", "blank", "好", "blank"] CTC_最终 = ["你", "好"] # 移除blank和重复
-
Transformer模型方法:采用自回归方式,通过起始符逐步生成字符直至终止符EOS。
-
分化点:如何解决序列长度映射问题? ↙ ↘ CTC路径 Transformer路径 (帧级对齐) (序列生成)
-
解码过程的自回归和非自回归介绍:
-
自回归解码(AR):
-
依赖关系: 解码过程需要历史解码结果,需迭代解码至⟨eos⟩终止符
-
计算代价: 需多次Decoder前向计算,使用Beam Search时需维护状态集合,资源消耗显著增加
-
波束搜索算法(Beam Search)机制:
-
实现方式: 维护多个候选解码路径,通过扩展可能性集合保留最优解。
-
代价分析: 每步需计算所有候选路径的扩展可能性,计算复杂度呈指数级增长
-
-
贪婪搜索(Greedy Search)机制:
-
实现方式: 维护当下最优候选解码路径,局部最优无法做到全局最优。
-
-
-
-
非自回归解码(NAR):
-
设计目标: 消除对历史解码结果的依赖,提升GPU并行解码效率。默认采用贪婪搜索机制.
-
优势: 显著降低计算资源开销,特别适合需要实时性的应用场景。
-
NAR解决Transformer解码速度慢的问题,通过并行生成消除序列依赖。
-
-
帧级对齐
CTC的缺点:帧间无依赖关系,精度受限。后续引入CIF
CIF(Continuous Integrate-and-Fire)是一种“软、单调”的对齐机制:按时间对每帧赋权并累加,累计权重达到阈值就触发产出一个词元的声学向量,用于即时或低延迟识别。
举例说明:
# 输入:语音"你好" # 假设编码器输出8个音频帧的特征向量 音频帧序列 = [h₁, h₂, h₃, h₄, h₅, h₆, h₇, h₈] # CTC方式(硬对齐): CTC_输出 = ["你", "blank", "你", "好", "blank", "blank", "好", "blank"] CTC_最终 = ["你", "好"] # 移除blank和重复 # CIF方式(软对齐): CIF_权重 = [0.2, 0.4, 0.7, 0.3, 0.1, 0.6, 0.5, 0.2] CIF_累计 = [0.2, 0.6, 1.3🔥, 0.6, 0.7, 1.3🔥, 0.8, 1.0🔥] CIF对齐: 帧1-3 → "你", 帧3-6 → "好", 帧6-8 → "<eos>" CIF_输出 = ["你", "好", "<eos>"] # 关键差异: # CTC:每帧独立预测,依赖blank标签处理时序 局限:帧间无依赖关系,精度受限。 # CIF优势: # 1. 帧3既贡献给"你"也贡献给"好" → 软边界 # 2. 根据音频内容动态分配权重 → 自适应对齐 # 3. 单调性保证,不会出现时序混乱
Transformer 架构原则是AR架构,不支持NAR。因为CIF和CTC的机制,使得transformer在解码的时候能够预测多少个字符,也就使得从AR转向于NAR大幅度提升了推理速度。
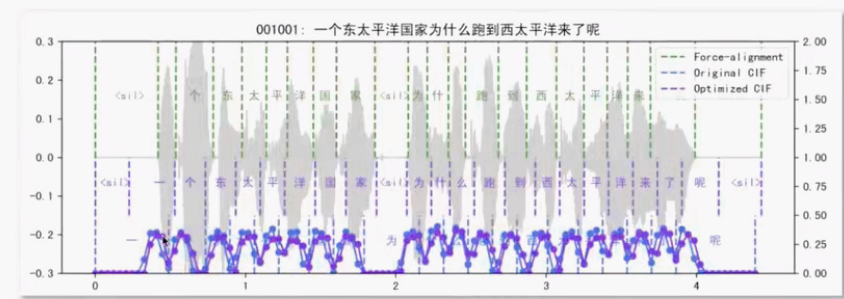
业务角度
热词定制化:根据输入词汇纠正识别结果中的人名、地名、专有名词等。
-
示例:将"邓玉松"纠正为"邓郁松","浮城街"纠正为"福成街"
-
应用价值:商用ASR系统用户可获取定制化结果
时间戳定制化业务:根据转录后的文字,跳转至画面位置。特别适合视频内容检索、在线教育、会议记录等需要精确时间定位的业务场景。
模型应用
FunClip开源项目是阿里巴巴达摩院通义实验室推出的一款完全开源、本地部署的AI自动化视频剪辑工具 。该项目集成了阿里巴巴自研的FunASR Paraformer系列模型,通过先进的语音识别技术实现智能视频剪辑。
核心功能:通过语音识别结果选择片段进行精准裁剪。
QMDAI服务基于FUNASR工具包接入Paraformer-zh-streaming模型。通过对比科大讯飞ASR在线API服务,音频质量良好情况下,普通话转录质量能够满足日常需求。比如天猫精灵、小米音箱、Siri语音助手。(不严格要求准确)。
该模型最大特点是花少量CPU硬件资源,能够顺畅运行ASR转录任务。VMware 全虚拟化环境下,Intel® Core™ i7-10700 基准频率 2.90 GH。测试wav文件:92.14秒,转录文本总花费8.935秒。转录CPU最高消耗大概在300左右。
中文场景更多模型选择
中文模型后续扩展选择:Paraformer-zh-streaming虽在流式部署和低延迟场景上表现优秀,但在字符错误率(CER)指标上已有更先进的开源模型超越,如FireRedASR-LLM(需GPU),其在公开基准上取得了3.05%的平均CER,而Paraformer-large(最接近的非流式版本)在WenetSpeech“Test Net”集上的CER为6.74%,可见性能已拉开明显差距。
| 模型 | 参数量(1B= 1000 M) | 测试集平均CER |
|---|---|---|
| FireRedASR-LLM | 8.3B | 3.05% |
| Paraformer-large | ~300–500M | 6.74% |
| Paraformer-zh-streaming | 220M | 未公开 |
学习社区
https://github.com/0voice

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









