







 本文介绍了Dev-C++遇到的编译错误,即链接器找不到函数引用。问题源于未正确添加头文件路径。通过屏蔽所有函数调用和头文件后,发现只有在引入自定义头文件时才会出现错误。解决方案是学习如何在Dev-C++中添加头文件路径,类似于Keil。按照步骤操作后,成功解决了编译问题。
本文介绍了Dev-C++遇到的编译错误,即链接器找不到函数引用。问题源于未正确添加头文件路径。通过屏蔽所有函数调用和头文件后,发现只有在引入自定义头文件时才会出现错误。解决方案是学习如何在Dev-C++中添加头文件路径,类似于Keil。按照步骤操作后,成功解决了编译问题。
一、Dev-C++编译 错误原始提示:
C:\Users\ADMINI~1\AppData\Local\Temp\cc2AAIV9.o main.c:(.text+0x18): undefined reference to `tst'
E:\Doxygen\Src\collect2.exe [Error] ld returned 1 exit status
下图仅参考,非问题原图,提示错误类似!原文如上文
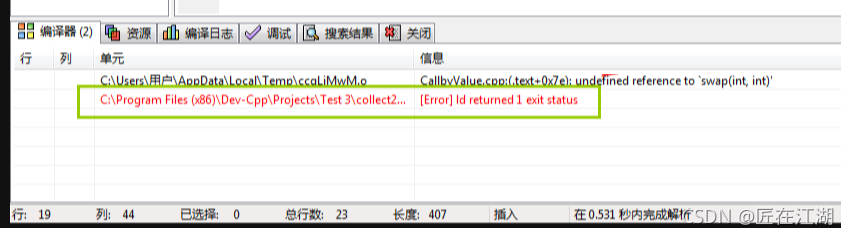
二、源码情况及问题分析
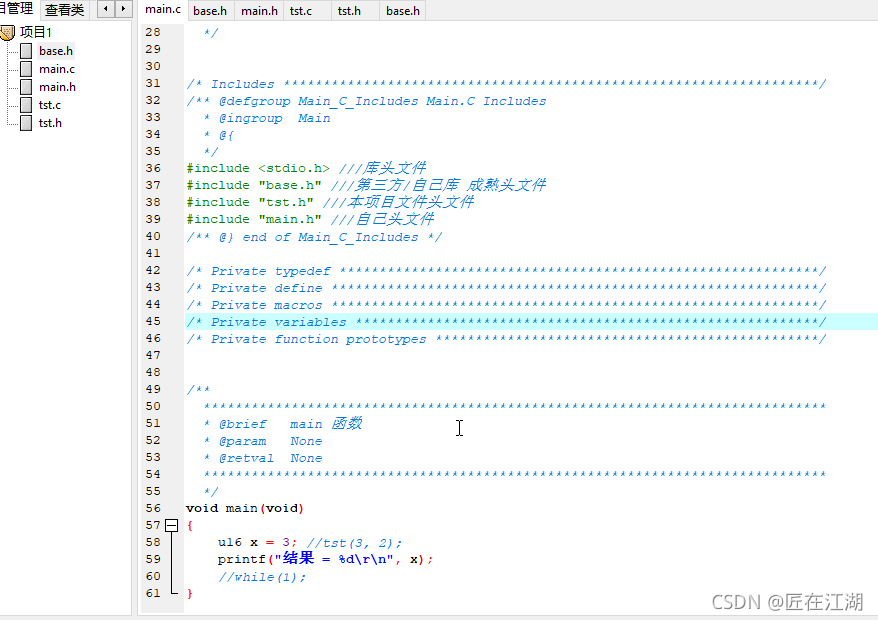
把所有调用函数和头文件都屏蔽!编译没问题!添加自己的头文件就有上文的提示错误!
经过调试验证,最终锁定是头文件没有添加!Dev-C++如Keil一样要添加头文件路径。
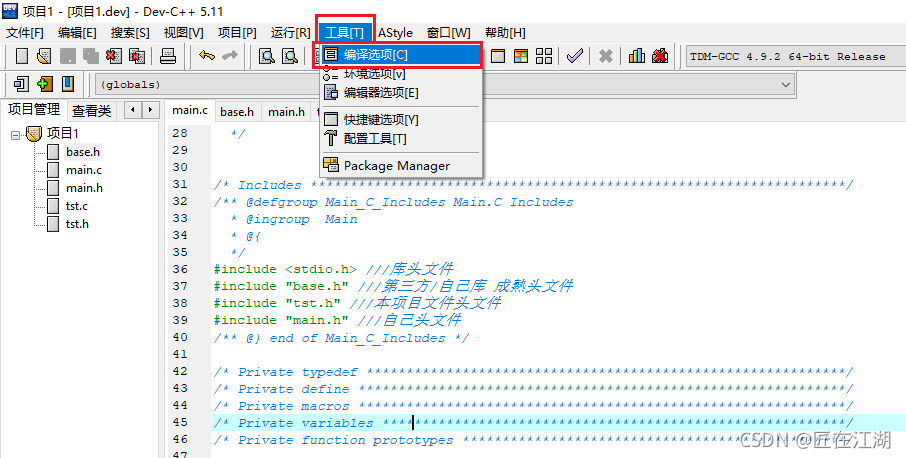
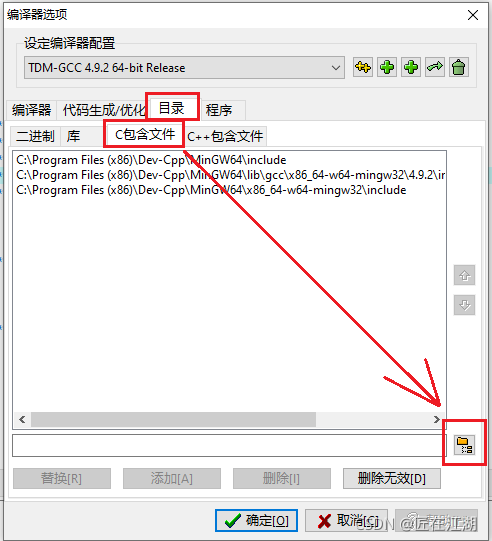
三、解决过程
添加头文件过程如下:
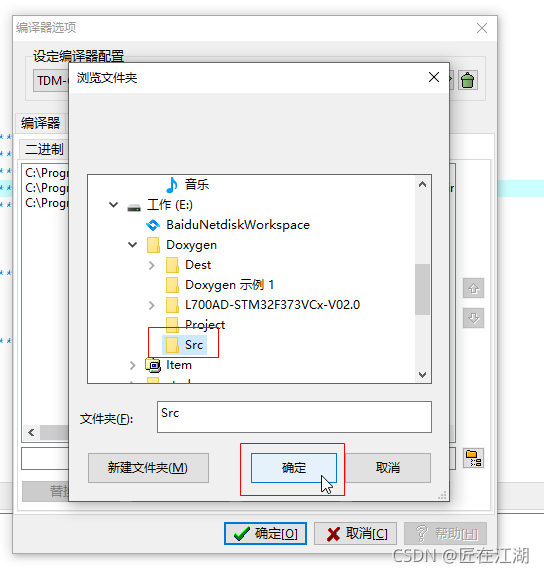
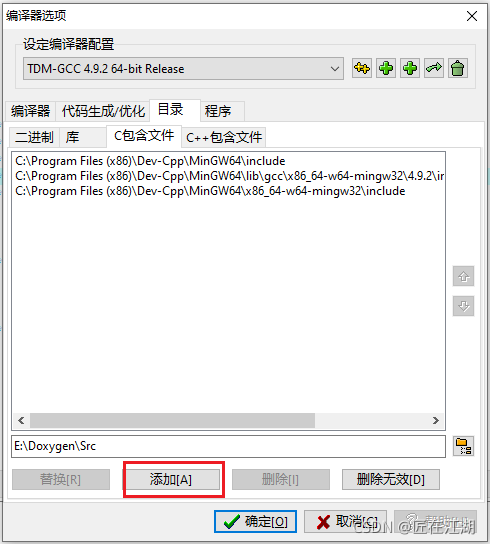
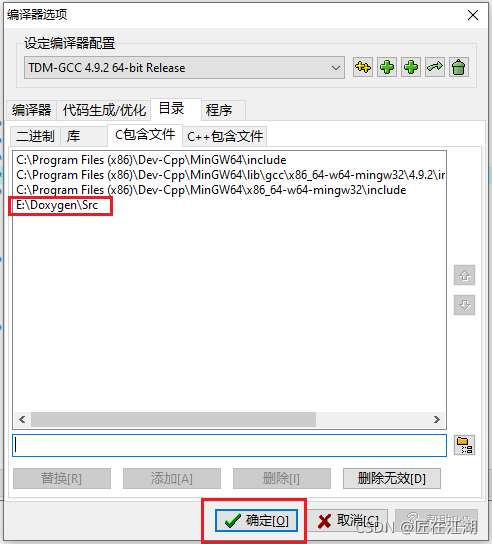

















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









