






 本文深入解析卷积神经网络(CNN)的工作原理及其在计算机视觉领域的应用,涵盖卷积、池化、激活函数和全连接层等核心概念。通过对比传统机器学习模型,展示CNN在图像处理上的优势。并提供基于Pytorch的CNN实现代码,包括模型定义和训练流程。
本文深入解析卷积神经网络(CNN)的工作原理及其在计算机视觉领域的应用,涵盖卷积、池化、激活函数和全连接层等核心概念。通过对比传统机器学习模型,展示CNN在图像处理上的优势。并提供基于Pytorch的CNN实现代码,包括模型定义和训练流程。
CNN介绍
卷积神经网络(Convolutional Neural Network,CNN)是一类特殊的神经网络。同全连接神经网络等不同的是,卷积神经网络直接对二维数据乃至三维等高维数据进行处理,并且具有更高的计算精度和速度。
CNN每一层由众多的卷积核组成,每个卷积核对输入的像素进行卷积操作,得到下一次的输入。随着网络层的增加卷积核会逐渐扩大感受野,并缩减图像的尺寸。
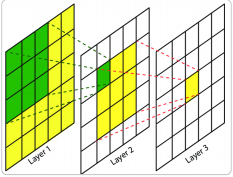
尤其是在计算机视觉领域,CNN的应用非常广泛,使其成为了解决图像分类、图像检索、目标检测、语义分割的主流模型。
CNN是一种层次模型,输入的是原始的像素数据。CNN通过卷积(convolution)、池化(pooling)、非线性激活函数(non-linear activation function)和全连接层(fully connected layer)构成。
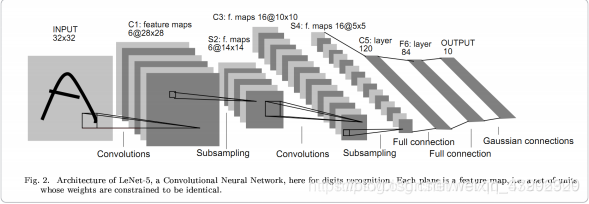
池化层:思考人对图像当中存在的物体进行的过程,我们通常没有审视整个图像,而是依据一些局部的特征就足以进行准确的判断。根据这样的指导思想,池化层孕育而生。通过提取一定区域(如22、33像素方格之中)内的关键信息,CNN通常能够更加准确快速的获取目标信息,同时又能够减少模型的参数量,大大提高了运行效率。基于以上的思想,我们可以得到平均池化操作(即对区域内的像素值取平均操作当做一个像素传递到下一层),最大池化(取区域内的最大值)等池化操作。
非线性激活函数:同一般的神经网络相同,采用非线性激活函数能够使网络全过程训练摆脱单一的线性关系,让feature map获得的特征更加符合现实。在大部分CNN网络架构当中,采用ReLU函数作为激活函数,ReLU函数表示如下:
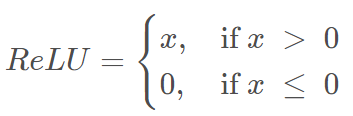
全连接层:全连接层的引入能够方便网络将提取到的特征值直接转化为我们想要的目标。比如实现手写数字识别的项目中,最后可以加入输出为10个神经元的输出层。每一个神经元代表的都是0-9数字当中的一个,输出的值可以看做是图片对应数字出现的概率。选取最大的即可获得输入图片对应的期望数字。在街景字符识别项目当中,我们首先实现基于定长字符识别的思路进行实现。在resnet18网络架构之后加入5个相互独立的512个神经元到11个元的输出层,每一个输出层负责识别一位数字,最终将数字组合到一起,即可以得到总体的预测结果。为什么这里是11个神经元呢,数字不是0-9一共只有10个嘛?因为定长识别当中需要额外添加一个空位,这在识别当中同样被算作一个字符,所以输出为11个神经元。
与传统的机器学习模型相比,CNN具有一种端对端(End to End)的思路。在CNN训练的过程中是直接从图像像素到最终的输出,并不涉及具体的特征提取和构建模型的过程,也不需要人工的参与。
pytorch的CNN实现
Pytorch构建CNN模型很简单,只需要定义好模型的参数和正向传播即可,Pytorch会根据正向传播自动计算反向传播。
# CNN模型包括两个卷积层、6个全连接层
import torch
torch.manual_seed(0)
torch.backends.cundnn.deterministic = False
torch.backends.cudnn.benchmark = True
imoort torchvision.models ad models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
<div STYLE="page-break-after:always;"></div>
# 定义模型
class SVHN_Model1(nn.Module):
def __init__(self):
super(SVHN_Model1,self).__init__()
#CNN提取特征模块
self.cnn = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=(3,3), stride=(2,2)),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, kernel_size=(3,3), stride=(2,2)),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.fc1 = nn.Linear(32*3*7,11)
self.fc2 = nn.Linear(32*3*7,11)
self.fc3 = nn.Linear(32*3*7, 11)
self.fc4 = nn.Linear(32*3*7, 11)
self.fc5 = nn.Linear(32*3*7, 11)
self.fc6 = nn.Linear(32*3*7, 11)
def forward(self, img):
feat = self.cnn(img)
feat = feat.view(feat.shape[8], -1)
c1 = self.fc1(feat)
c2 = sefl.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
c6 = self.fc6(feat)
return c1, c2, c3, c4, c5, c6
model = SVHN_Model1()
# 训练代码
<div STYLE="page-break-after: always;"></div>
# 损失函数
criterion = nn.CrossEntropyLoss()
<div STYLE="page-break-after: always;"></div>
# 优化器
optimizer torch.optim.Adam(model, parameters(), 0.05)
loss_plot, c0_plot = [], []
<div STYLE="page-break-after: always;"></div>
# 迭代10个Epoch
for epoch in range(10):
for data in train_loader:
c0, c1, c2, c3, c4, c5 = model(data[0])
loss = criterion(c0, data[1][:, 0] + \
criterion(c1, data[1][:, 1] + \
criterion(c2, data[1][:, 2] + \
criterion(c3, data[1][:, 3] + \
criterion(c4, data[1][:, 4] + \
criterion(c5, data[1][:, 5] + \
criterion(c5, data[1][:, 6])
loss /= 6
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_plot_append(loss.item())
c0_plot.append((c0.argmax(1) == data[1][:,0].sum().item()*1.0 / c0.shape[0])
print(epoch)
为了提高精度,我们也可以使用在ImageNet数据集上的预训练模型,具体方法如下:
class SVHN_Model2(nn.Module):
def __init__(self):
super(SVHN_Model2, self),__init__()
model_conv = models.resnet18(pretrained=True)
model_conv .avgpool = nn.AdaptiveAvgPool2d(1)
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
self.cnn = model_conv
self.fc1 = nn.Linear(512, 11)
self.fc2 = nn.Linear(512, 11)
self.fc3 = nn.Linear(512, 11)
self.fc4 = nn.Linear(512, 11)
self.fc5 = nn.Linear(512, 11)
def forward(self, img):
feat = self.cnn(img)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
return c1, c2, c3, c4, c5
参考:
Datawhale 零基础入门CV赛事-Task3 字符识别模型
https://blog.youkuaiyun.com/weixin_42716570/article/details/106337520

















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









